
这篇文章由 David Mandelin 撰写,他是 Mozilla JavaScript 团队的成员。
Firefox 3.5 拥有一个全新的 JavaScript 引擎 TraceMonkey,它运行许多 JavaScript 程序的速度比 Firefox 3 快 3-4 倍,从而加快了现有 Web 应用程序的速度,并支持新的应用程序。本文将深入了解 TraceMonkey 的主要部分及其加速 JS 的方式。本文还将解释哪些类型的程序可以从 TraceMonkey 中获得最佳加速,以及您可以采取哪些措施来加速程序的运行。
为什么快速运行 JS 很困难:动态类型
像 JavaScript 和 Python 这样的高级动态语言使编程更加高效,但它们一直以来都比 Java 或 C 等静态类型语言慢。一条经验法则是,JS 程序可能比等效的 Java 程序慢 10 倍。
JS 和其他动态脚本语言通常比 Java 或 C 运行得慢的主要原因有两个。第一个原因是,在动态语言中,通常无法提前确定值的类型。因此,语言必须以通用格式存储所有值,并使用通用操作处理值。
相比之下,在 Java 中,程序员会为变量和方法声明类型,因此编译器可以提前确定值的类型。然后,编译器可以生成使用专用格式和操作的代码,这些格式和操作比通用操作运行得快得多。我将这些操作称为 **类型专用** 操作。
动态语言运行速度较慢的第二个主要原因是,脚本语言通常用解释器实现,而静态类型语言则编译成本地代码。解释器更容易创建,但它们会为跟踪其内部状态带来额外的运行时开销。像 Java 这样的语言编译成机器语言,几乎不需要状态跟踪开销。
让我们用一张图片来具体说明一下。以下是针对一个简单的数字加法操作 a + b 的速度降低情况,其中 a 和 b 是整数。现在,忽略最右边的条形图,重点关注 Firefox 3 JavaScript 解释器与 Java JIT 的比较。每一列都显示了在每种编程语言中完成加法操作所需执行的步骤。时间自上而下,每个框的高度与其完成框中步骤所需的时间成正比。
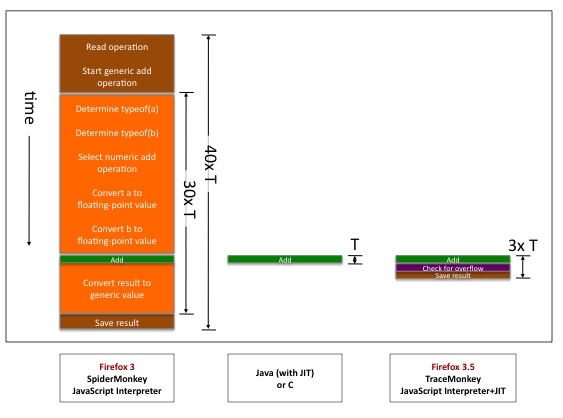
在中间,Java 只执行一条机器语言加法指令,该指令在时间 T(一个处理器周期)内运行。由于 Java 编译器知道操作数是标准机器整数,因此它可以使用标准的整数加法机器语言指令。就这些了。
在左边,SpiderMonkey(FF3 中的 JS 解释器)大约需要 40 倍的时间。棕色框代表解释器开销:解释器必须读取加法操作并跳转到解释器的代码以进行通用加法。橙色框代表由于解释器不知道操作数类型而必须完成的额外工作。解释器必须解包 a 和 i 的通用表示,找出它们的类型,选择特定的加法操作,将值转换为正确的类型,最后将结果转换回通用格式。
该图表明,使用解释器而不是编译器会略微降低速度,但缺乏类型信息会大大降低速度。如果我们希望 JS 的运行速度比 FF3 快一点,根据 Amdahl 定律,我们需要针对类型做点什么。
通过跟踪获取类型
我们在 TraceMonkey 中的目标是编译类型专用代码。为此,TraceMonkey 需要知道变量的类型。但 JavaScript 没有类型声明,我们之前也说过,JS 引擎实际上不可能提前找出类型。因此,如果我们想要提前编译所有内容,那就没辙了。
所以让我们换个角度思考这个问题。如果我们让程序在解释器中运行一段时间,引擎就可以直接 *观察* 值的类型。然后,引擎可以使用这些类型来编译快速类型专用代码。最后,引擎可以开始运行类型专用代码,并且运行速度会快得多。
这个想法中有一些关键细节。首先,当程序运行时,即使存在许多 if 语句和其他分支,程序始终只沿一个方向运行。因此,引擎不会观察整个方法的类型——引擎会通过程序实际采用的路径(我们称之为 *跟踪*)来观察类型。因此,虽然标准编译器会编译方法,但 TraceMonkey 会编译跟踪。每次跟踪编译的一项附带好处是,在跟踪中发生的函数调用会内联,从而使跟踪的函数调用非常快。
其次,编译类型专用代码需要时间。如果一段代码只运行一次或几次,这在 Web 代码中很常见,则编译和运行这段代码可能比仅仅在解释器中运行这段代码花费更多时间。因此,只有编译 *热点代码*(执行多次的代码)才是值得的。在 TraceMonkey 中,我们通过只跟踪循环来实现这一点。TraceMonkey 最初在解释器中运行所有内容,并在循环变热(运行超过几次)时开始记录该循环的跟踪。
只跟踪热点循环有一个重要的后果:只运行几次的代码不会在 TraceMonkey 中加速。请注意,这在实践中通常无关紧要,因为只运行几次的代码通常运行速度太快,以至于不会被注意到。另一个后果是,完全没有被采用的循环路径永远不需要编译,从而节省了编译时间。
最后,我们之前说过,TraceMonkey 通过观察执行来找出值的类型,但众所周知,过去的性能不能保证未来的结果:下次运行代码时类型可能不同,或者第 500 次运行时类型可能不同。如果我们尝试运行为数字编译的代码,而这些值实际上是字符串,就会发生非常糟糕的事情。因此,TraceMonkey 必须在编译的代码中插入类型检查。如果检查不通过,TraceMonkey 必须离开当前跟踪并为新类型编译新的跟踪。这意味着,具有许多分支或类型更改的代码在 TraceMonkey 中运行速度会略慢一些,因为它需要时间来编译额外的跟踪并在它们之间跳转。
TraceMonkey 在行动
现在,我们将通过一个示例程序来展示跟踪在行动中的情况,该程序将前 N 个整数加到一个起始值中
function addTo(a, n) {
for (var i = 0; i < n; ++i)
a = a + i;
return a;
}
var t0 = new Date();
var n = addTo(0, 10000000);
print(n);
print(new Date() - t0);
TraceMonkey 始终在 *解释器* 中开始运行程序。每次程序开始循环迭代时,TraceMonkey 会短暂进入 *监控* 模式,以增加该循环的计数器。在 FF3.5 中,当计数器达到 2 时,该循环被认为是热的,此时需要进行跟踪。
现在,TraceMonkey 在解释器中继续运行,但开始在代码运行时 *记录* 跟踪。跟踪只是运行到循环结束的代码,以及使用的类型。类型是通过查看实际值来确定的。在我们的示例中,循环执行以下 JavaScript 语句序列,该序列成为我们的跟踪
a = a + i; // a is an integer number (0 before, 1 after)
++i; // i is an integer number (1 before, 2 after)
if (!(i < n)) // n is an integer number (10000000)
break;
这就是跟踪在类似 JavaScript 的表示法中的样子。但 TraceMonkey 需要更多信息才能编译跟踪。真正的跟踪看起来更像这样
trace_1_start:
++i; // i is an integer number (0 before, 1 after)
temp = a + i; // a is an integer number (1 before, 2 after)
if (lastOperationOverflowed())
exit_trace(OVERFLOWED);
a = temp;
if (!(i < n)) // n is an integer number (10000000)
exit_trace(BRANCHED);
goto trace_1_start;
此跟踪表示一个循环,它应该作为循环进行编译,因此我们使用 goto 来直接表达这一点。此外,整数加法可能会溢出,这需要特殊处理(例如,用浮点加法重新执行),而这反过来又需要退出跟踪。因此,跟踪必须包含一个溢出检查。最后,如果循环条件为假,跟踪将以相同的方式退出。退出代码告诉 TraceMonkey 退出跟踪的原因,以便 TraceMonkey 可以决定下一步该怎么做(例如,是否重做加法或退出循环)。请注意,跟踪以特殊的内部格式记录,该格式从未公开给程序员——上面使用的表示法只是为了说明目的。
记录完跟踪后,就可以将其 *编译* 成类型专用的机器代码。这种编译由一个小型 JIT 编译器(恰如其分地命名为 *nanojit*)执行,结果存储在内存中,准备由 CPU 执行。
下次解释器通过循环头时,TraceMonkey 将开始 *执行* 编译后的跟踪。现在,程序运行速度非常快。
在第 65537 次迭代时,整数加法将溢出。(2147450880 + 65537 = 2147516417,大于 2^31-1 = 2147483647,这是最大的有符号 32 位整数)。此时,跟踪将以 OVERFLOWED 代码退出。看到这一点,TraceMonkey 将返回解释器模式并重新执行加法。由于解释器会通用地执行所有操作,因此加法溢出将得到处理,一切正常。TraceMonkey 还将开始监控此退出点,如果溢出退出点曾经变热,将从该点开始新的跟踪。
但在这个特定程序中,实际发生的事情是,程序再次通过循环头。TraceMonkey 知道它在这个点有一个跟踪,但 TraceMonkey 也知道它不能使用该跟踪,因为该跟踪是针对整数值的,但 a 现在是浮点格式。因此,TraceMonkey 会记录一个新的跟踪
trace_2_start:
++i; // i is an integer number
a = a + i; // a is a floating-point number
if (!(i < n)) // n is an integer number (10000000)
exit_trace(BRANCHED);
goto trace_2_start;
然后,TraceMonkey 会编译新的跟踪,并在下一次循环迭代时开始执行它。这样,即使类型发生变化,TraceMonkey 也会使 JavaScript 以机器代码形式运行。最终,跟踪将以 BRANCHED 代码退出。此时,TraceMonkey 将返回解释器,解释器接管并完成程序的运行。
以下是该程序在我笔记本电脑(2.2GHz MacBook Pro)上的运行时间
| 系统 | 运行时间(毫秒) |
| SpiderMonkey (FF3) | 990 |
| TraceMonkey (FF3.5) | 45 |
| Java (使用 int) | 25 |
| Java (使用 double) | 74 |
| C (使用 int) | 5 |
| C (使用 double) | 15 |
该程序从跟踪中获得了巨大的 22 倍加速,并且运行速度与 Java 相当!在循环中执行简单算术运算的函数通常会从跟踪中获得很大的加速。许多 SunSpider 基准测试的位操作和数学运算,例如 bitops-3bit-bits-in-byte、ctrypto-sha1 和 math-spectral-norm,获得了 6 倍到 22 倍的加速。
使用更复杂操作的函数,例如对象操作,速度提升幅度较小,通常在 2-5 倍之间。这从阿姆达尔定律和复杂操作耗时较长的事实可以数学推导出来。回顾时间图,考虑一个更复杂的操作,其绿色部分耗时为 30T。橙色和棕色部分的总时长仍然约为 30T,因此消除它们可以带来 2 倍的提速。SunSpider 基准测试中的 string-fasta 就是这种程序的示例:大部分时间都花在了字符串操作上,而这些操作的绿色框部分耗时相对较长。
以下是在浏览器中可以尝试的示例程序版本。
数值结果:
运行时间:
平均运行时间:
理解和解决性能问题
我们的目标是使 TraceMonkey 始终足够快,以便您能够以最能表达您想法的方式编写代码,而不必担心性能。如果 TraceMonkey 没有加速您的程序,我们希望您能将其报告为错误,以便我们改进引擎。当然,您可能需要您的程序在当今的 FF3.5 中运行得更快。在本节中,我们将解释一些工具和技术,用于解决在启用跟踪 JIT 后没有获得良好(2 倍或更多)提速的程序的性能问题。(您可以通过转到 **about:config** 并将首选项 **javascript.options.jit.content** 设置为 false 来禁用 JIT。)
第一步是理解问题的原因。最常见的原因是 *跟踪中止*,这仅仅意味着 TraceMonkey 无法完成跟踪记录,并且放弃了。通常的结果是包含中止的循环将在解释器中运行,因此您不会在该循环上获得提速。有时,循环中的一条路径会被跟踪,但在另一条路径上会发生中止,这会导致 TraceMonkey 在解释和运行本地代码之间来回切换。这可能会导致提速减少、没有提速,甚至变慢:切换模式需要时间,因此快速切换会导致性能低下。
使用浏览器的调试版本或 JS shell(我自己 构建 的 - 我们不发布这些版本),您可以通过设置 TMFLAGS 环境变量来指示 TraceMonkey 打印有关中止的信息。我通常是这样做的
TMFLAGS=minimal,abort dist/MinefieldDebug.app/Contents/MacOS/firefox
minimal 选项打印出所有开始记录和成功完成记录的位置。这提供了有关跟踪器尝试执行的操作的基本了解。abort 选项打印出所有由于不支持的结构而导致记录中止的位置。(设置 TMFLAGS=help 将打印其他 TMFLAGS 选项列表,然后退出。)
(还要注意,TMFLAGS 是打印调试信息的最新方法。如果您使用的是 FF3.5 版本的调试版本,则环境变量设置是 TRACEMONKEY=abort。)
以下是一个在 TraceMonkey 中没有获得太多提速的示例程序。
function runExample2() {
var t0 = new Date;
var sum = 0;
for (var i = 0; i < 100000; ++i) {
sum += i;
}
var prod = 1;
for (var i = 1; i < 100000; ++i) {
eval("prod *= i");
}
var dt = new Date - t0;
document.getElementById(example2_time').innerHTML = dt + ' ms';
}
运行时间:
如果我们设置 TMFLAGS=minimal,abort,我们将得到以下内容
Recording starting from ab.js:5@23
recording completed at ab.js:5@23 via closeLoop
Recording starting from ab.js:5@23
recording completed at ab.js:5@23 via closeLoop
Recording starting from ab.js:10@63
Abort recording of tree ab.js:10@63 at ab.js:11@70: eval.
Recording starting from ab.js:10@63
Abort recording of tree ab.js:10@63 at ab.js:11@70: eval.
Recording starting from ab.js:10@63
Abort recording of tree ab.js:10@63 at ab.js:11@70: eval.
前两对行显示第一个循环(从第 5 行开始)跟踪良好。后面的行显示 TraceMonkey 开始跟踪第 10 行的循环,但每次都因 eval 而失败。
关于此调试输出的一个重要说明是,您通常会看到一些消息提到 *内部树* 正在增长、稳定等。这些实际上不是问题:它们通常只表示由于 TraceMonkey 连接内部和外部循环的方式而导致完成跟踪循环的 *延迟*。事实上,如果您在这些中止之后进一步查看输出,您通常会看到循环最终确实被跟踪了。
否则,中止主要由跟踪尚不支持的 JavaScript 结构导致。对于像 + 这样的基本操作,跟踪记录过程比对于像 arguments 这样的高级功能更容易实现。我们在 FF3.5 版本发布之前没有时间对每个 JavaScript 功能进行健壮、安全的跟踪,因此在 FF3.5.0 中,一些更高级的功能(如 arguments)没有被跟踪。其他没有被跟踪的高级功能包括 getter 和 setter、with 和 eval。对闭包的支持是部分的,具体取决于它们的使用方式。重构以避免这些结构可以提高性能。
有两个特别重要的 JavaScript 功能没有被跟踪,它们是
- 递归。TraceMonkey 不将通过递归发生的重复视为循环,因此不会尝试跟踪它。重构为使用显式的
for或while循环通常会带来更好的性能。 - 获取或设置 DOM 属性。(DOM 方法调用是可以的。)通常不可能避免这些结构,但是将 DOM 属性访问移出热循环和性能关键部分的代码重构应该有所帮助。
我们正在积极地努力跟踪上面提到的所有功能。例如,对跟踪 arguments 的支持已经在夜间构建版本中可用。
以下是被重构为避免 eval 的慢速示例程序。当然,我可以简单地内联进行乘法运算。相反,我使用由 eval 创建的函数,因为这是重构 eval 的更通用方法。请注意,eval 仍然无法被跟踪,但它只运行一次,因此并不重要。
function runExample3() {
var t0 = new Date;
var sum = 0;
for (var i = 0; i < 100000; ++i) {
sum += i;
}
var prod = 1;
var mul = eval("(function(i) { return prod * i; })");
for (var i = 1; i < 100000; ++i) {
prod = mul(i);
}
var dt = new Date - t0;
document.getElementById('example3_time').innerHTML = dt + ' ms';
}
运行时间:
还有一些更加晦涩的场景也会影响跟踪性能。其中一个是 *跟踪爆炸*,它发生在循环有许多路径通过它时。考虑一个循环,其中有 10 个 if 语句排成一行:该循环有 1024 条路径,可能导致记录 1024 条跟踪。这将占用太多内存,因此 TraceMonkey 将每个循环限制为 32 条跟踪。如果循环少于 32 条热跟踪,它将表现良好。但是,如果每个路径的出现频率相同,那么只有 3% 的路径会被跟踪,性能就会下降。
这种问题最好用 TraceVis 来分析,TraceVis 会创建 TraceMonkey 性能的可视化视图。目前,构建系统只支持为 shell 构建启用 TraceVis,但基本系统也可以在浏览器中运行,并且有 正在进行的工作 在浏览器中以方便的形式启用 TraceVis。
关于 TraceVis 的 博客文章 目前是对图表含义以及如何使用它们诊断性能问题的最详细解释。这篇文章还包含对图表的详细分析,这有助于理解 TraceMonkey 的总体工作原理。
比较性 JIT 文献
在这里,我将对其他 JavaScript JIT 设计进行一些比较。我将更多地关注假设设计,而不是竞争引擎,因为我对它们的详细信息并不了解——我已经阅读了发布信息,并略读了一些代码。另一个重大警告是,实际性能至少与工程细节一样取决于引擎架构。
一种设计选择可以称为 *每方法非专门化 JIT*。我的意思是,一个一次编译一个方法并生成通用代码的 JIT 编译器,就像解释器所做的那样。因此,我们图表中的棕色框被裁掉了。这种 JIT 不需要花费时间来记录和编译跟踪,但它也不进行类型专门化,因此橙色框仍然存在。这种引擎仍然可以通过精心设计和优化橙色框代码来获得相当快的速度。但是,在该设计中,无法完全消除橙色框,因此数字程序的最高性能不会像类型专门化引擎那样好。
据我所知,截至本文撰写之时,Nitro 和 V8 都是轻量级非专门化 JIT。(我听说 V8 确实尝试通过查看源代码来推测一些类型(例如,推测在 a >> 2 中 a 是一个整数),以便进行一些类型专门化。)看来 TraceMonkey 在数字基准测试中通常更快,如上所述。但是,TraceMonkey 在使用更多对象的基准测试中表现不佳,因为我们的对象操作和内存管理尚未优化得那么好。
基本 JIT 的进一步发展是 *每方法类型专门化 JIT*。这种 JIT 尝试根据调用方法时的参数类型来对方法进行类型专门化。与 TraceMonkey 一样,这需要一些运行时观察:基本设计在每次调用方法时都会检查参数类型,如果这些类型以前没有被看到过,则会编译方法的新版本。与 TraceMonkey 一样,这种设计可以对代码进行高度专门化,并删除棕色框和橙色框。
据我所知,还没有人将每方法类型专门化 JIT 用于 JavaScript,但我不会感到惊讶,如果有人正在研究它。
与跟踪 JIT 相比,每方法类型专门化 JIT 的主要缺点是,基本每方法 JIT 只能直接观察方法的输入类型。它必须尝试通过算法推断方法内部变量的类型,这对 JavaScript 来说很困难,尤其是如果方法读取对象属性。因此,我认为每方法类型专门化 JIT 必须对方法的某些部分使用通用操作。每方法设计的最大优势是,方法只需要针对每组输入类型编译一次,因此它不会受到跟踪爆炸的影响。反过来,我认为每方法 JIT 在路径较多的方法上往往更快,而跟踪 JIT 在高度类型专门化的方法上往往更快,尤其是在方法还读取许多属性值的情况下。
结论
到目前为止,您应该对什么使 JavaScript 引擎变快、TraceMonkey 如何工作以及如何分析和解决在 TraceMonkey 下运行 JavaScript 时可能出现的某些性能问题有了很好的了解。如果您遇到任何重大性能问题,请报告错误。错误报告也是我们提供额外调整建议的好地方。最后,我们一直在努力改进,因此如果您喜欢使用最新版本,请查看 TraceMonkey 夜间构建版本。
68 条评论