
这是 Mozilla 的身份团队在 Node.JS 假日季系列 中的第 5 集,共 12 集。在本篇文章中,我们将再次讨论 Node.JS 应用程序的扩展。
如何在面对不可能的负载下,构建一个能够持续运行的 Node.JS 应用程序?
本篇文章介绍了一种技术和一个实现该技术的库,所有内容都被浓缩到以下五行代码中
var toobusy = require('toobusy');
app.use(function(req, res, next) {
if (toobusy()) res.send(503, "I'm busy right now, sorry.");
else next();
});
为什么还要费心?
如果您的应用程序对人们很重要,那么花点时间考虑一下灾难场景是值得的。这些是好的灾难,您的项目会成为社交媒体的宠儿,您会从每天一万个用户变成一百万个用户。经过一些准备,您就可以构建一个服务,即使在流量峰值超过其容量数量级的期间也能保持运行。如果您放弃了这些准备,那么您的服务会在最不恰当的时候变得完全不可用 - 当每个人都在观看的时候。
另一个考虑合法流量峰值的好理由是恶意流量峰值:缓解 DoS 攻击 的第一步是构建不会过载的服务器。
服务器在负载下
为了说明没有考虑流量峰值的应用程序的行为方式,我 构建了一个应用程序服务器,它有一个 HTTP API,消耗 5ms 的处理器时间,分布在五个异步函数调用中。按照设计,该服务器的单个实例能够每秒处理 200 个请求。
这大致类似于一个典型的请求处理程序,它可能进行一些日志记录、与数据库交互、渲染模板并流出结果。以下是当我们线性增加连接尝试次数时,服务器延迟和 TCP 错误的图表
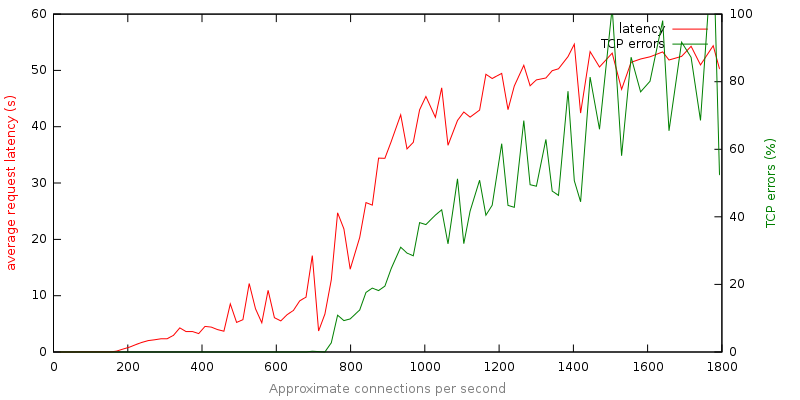
对这次运行数据的分析讲述了一个清晰的故事
该服务器没有响应:在最大容量的 6 倍(1200 个请求/秒)下,服务器变得笨拙,平均请求延迟为 40 秒。
这些故障很糟糕:超过 80% 的 TCP 故障和高延迟,用户将在长达一分钟的等待后看到一个令人困惑的故障。
优雅地失败
接下来,我在 同一个应用程序中加入了本文开头提供的代码。这段代码使服务器能够检测到负载何时超过其容量,并主动拒绝请求。以下图表描述了该服务器在当我们线性增加连接尝试次数时的性能
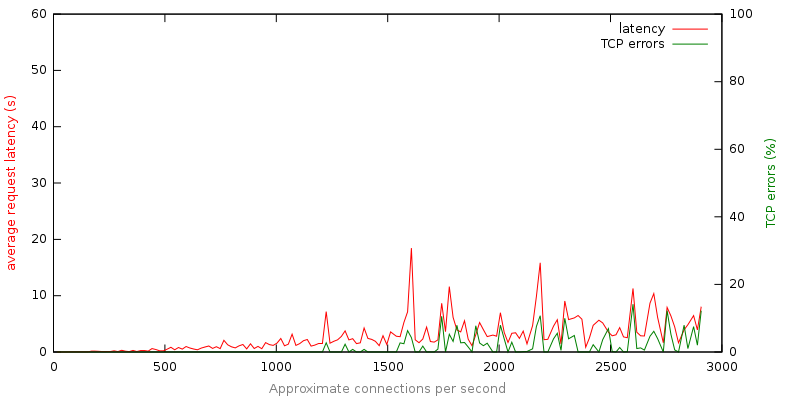
图表中没有描述的一件事是在这次运行中返回的 503(服务器太忙)响应的数量,它随着连接尝试次数的增加而稳定地增加。那么我们从该图表和基础数据中学到了什么呢?
主动限制增加了鲁棒性:在负载超过其容量数量级的条件下,应用程序仍然能够保持合理的行为。
成功和失败都很迅速:平均响应时间在大多数情况下保持在 10 秒以下。
这些故障并不糟糕:通过主动限制,我们有效地将缓慢的笨拙故障(TCP 超时)转换为快速的有意的故障(立即的 503 响应)。
需要说明的是,构建一个返回 HTTP 503 响应(“服务器太忙”)的服务器,要求您的接口向用户呈现一个合理的提示信息。通常这只是一项非常简单的任务,而且应该很熟悉,因为许多流行的网站都这样做。
如何使用它
node-toobusy 在 npm 和 github 上可用。安装完成后 (npm install toobusy),只需引入它即可
var toobusy = require('toobusy');
在引入该库的时刻,它将开始主动监控进程,并确定进程何时“太忙”。然后,您可以在应用程序的关键点检查进程是否过载
// The absolute first piece of middle-ware we would register, to block requests
// before we spend any time on them.
app.use(function(req, res, next) {
// check if we're toobusy() - note, this call is extremely fast, and returns
// state that is cached at a fixed interval
if (toobusy()) res.send(503, "I'm busy right now, sorry.");
else next();
});
这种对 node-toobusy 的应用为您提供了基本的负载鲁棒性,您可以 调整 和自定义它以适合您的应用程序设计。
它是如何工作的
我们如何可靠地确定一个 Node 应用程序是否太忙?
事实证明,这比您想象的要有趣,尤其是在您考虑到 node-toobusy 试图开箱即用地为任何 Node 应用程序工作时。为了理解所采用的方法,让我们回顾一下一些不起作用的方法
查看当前进程的处理器使用率:我们可以使用像你在 top 中看到的那样的数字 - Node 进程在处理器上执行的时间百分比。一旦我们有了确定这一点的方法,我们就可以说使用率超过 90% 就是“太忙”。当机器上有多个进程正在消耗资源,而你的 Node 应用程序没有一个完整的单处理器可用时,这种方法就会失效。在这种情况下,您的应用程序永远不会被注册为“太忙”,并且会以上面解释的方式严重失败。
将系统负载与当前使用率结合起来:为了解决这个问题,我们可以检索当前的系统负载,并在我们的“太忙”判定中考虑这一点。我们可以获取系统负载,并考虑可用处理核心的数量,然后确定我们的 Node 应用程序有多少个处理器的百分比可用!这种方法很快就变得复杂起来,需要系统特定的扩展,并且没有考虑到诸如进程优先级之类的事情。
我们想要的是一个更简单的解决方案,它可以正常工作。该解决方案应该得出这样的结论:当 Node.js 进程无法及时地处理请求时,它就是太忙了 - 这是一个与服务器上运行的其他进程的细节无关的标准。
node-toobusy 采取的方法是测量事件循环延迟。请记住,Node.JS 的核心是一个事件循环。要完成的工作会排队,并且在每次循环迭代中都会被处理。当 Node.js 进程变得过载时,队列会增长,并且有更多要完成的工作,而不是能够完成的工作。可以通过确定完成一小部分工作通过事件队列需要多长时间来了解 Node.js 进程的过载程度。node-toobusy 库为 libuv 提供了一个回调,该回调应该每 500 毫秒调用一次。从调用之间实际经过的时间中减去 500ms,就可以得到一个简单的事件循环延迟的度量。
简而言之,node-toobusy 通过测量事件循环延迟来确定主机进程的繁忙程度,这是一种简单而强大的技术,无论主机上运行的其他进程是什么,它都能正常工作。
当前状态
node-toobusy 是一个非常新的库,它通过测量事件循环延迟来简化构建不会过载的服务器:试图解决确定 Node.js 应用程序是否太忙的通用问题。此处描述的所有测试服务器以及文章中使用的负载生成工具都在 github 上可用。
在 Mozilla,我们目前正在评估将这种方法应用于 Persona 服务,并希望随着我们学习而对其进行改进。我期待着您的反馈 - 可以在本文的评论区、身份邮件列表 或 github 问题 中发表。
系列中的以前的文章
这是 关于 Node.js 的 12 篇文章系列 的第五部分。以前的文章是
33 条评论