
音乐对我来说不仅仅是日常生活的一部分,更是必不可少的一部分。它帮助我集中注意力,改善我的情绪,分散我的注意力和/或帮助我放松。这对大多数(如果不是全部)人来说都是如此。缺乏音乐或选择错误的曲调会产生完全相反的效果,它对我们的感受有很大的影响。它还在塑造我们的身份方面发挥着关键作用。音乐,就像大多数(如果不是全部)类型的文化一样,不是附属品,不是我们可以选择忽略的东西,而是我们作为人类的需求。
互联网已成为文化传播有史以来最有效的媒介。如今,比以往任何时候都更容易获得种类繁多的文化,来自世界任何地方。同时,您可以立即将您的音乐传播到全世界,只需在一个您可以找到的众多音乐发行网站之一注册即可。正如“旅行开阔视野”一样,音乐分享丰富了文化,并且由于互联网,文化如今比以往任何时候都更加活跃。
不久前,唱片公司是判断什么是好音乐(以他们的标准)和什么不是好音乐的评判者。他们控制着唯一的全球规模分销渠道,因此要使用它,您需要与他们达成协议,这通常意味着放弃您文化作品的大部分权利。创建和维护这样一个渠道既不容易也不便宜,他们提供的服务是必要的,即使他们的目标不是传播文化而是盈利(像每个公司一样),但双方,行业和社会都从中受益。
时代变了,这种模式现在已经过时了;国王死了,所以有一些公司正在争夺这个空缺。商业模式也发生了变化。现在不仅仅是音乐——还包括限制对它的访问并收集(和出售)关于听众的私人信息。换句话说,DRM 和隐私。这就是 Shiva 发挥作用的地方。
什么是 Shiva?
从技术上讲,Shiva 是您音乐收藏的 RESTful API。它索引您的音乐并公开包含文件元数据的 API,以便您可以对其执行查询并根据您的意愿对其进行组织。
然而,在更高层次上,Shiva 旨在成为流行音乐服务的免费(如自由和啤酒)替代方案。它的诞生是为了将对音乐和隐私的控制权交还给用户,保护他们免受行业对控制的痴迷。
它并非旨在与在线音乐服务直接竞争,而是成为您可以安装和修改以满足您需求的替代方案。您将在您的服务器上拥有音乐。除了您(或您授予权限的人)之外,没有人能够删除文件或修改文件的元数据以在错误时进行更正。当然,所有这些都将可供任何具有互联网连接的设备使用。
您还将拥有一个不受限制的、干净的 RESTful 音乐 API。您可以授予朋友访问权限并让他们使用该服务,或者,如果他们有自己的 Shiva 实例,则让两个服务器相互通信并透明地共享音乐。
总之,Shiva 是一个用于共享音乐的分布式社交网络。
您自己的音乐服务器
Shiva-Server 是索引您的音乐并公开 RESTful API 的组件。以下是可用的资源
- /artists
- /artists/shows
- /albums
- /tracks
- /tracks/lyrics
它使用 SQLAlchemy 作为 ORM 和 Flask 用于 HTTP 通信,是用 Python 编写的。
索引您的音乐
安装过程非常简单。README 文件中有一个非常完整的指南,但我会在这里对其进行总结
- 获取源代码
- 从 requirements.pip 文件安装依赖项
- 将 /shiva/config/local.py.example 复制到 /shiva/config/local.py
- 编辑它并配置要扫描的目录
- 创建数据库(默认情况下为 sqlite)
- 运行索引器
- 运行开发服务器
有关任何步骤的详细信息,请查看文档。
音乐被索引后,所有元数据都存储在数据库中并从中查询。文件仅由文件服务器访问以进行流式传输。歌词在首次请求时被抓取,然后缓存。鉴于演出资源的变化性质,这是唯一一个未被缓存的资源;而是每次都进行查询。在撰写本文时,它仅使用一个来源,即 BandsInTown API。
服务器运行后,您就可以开始使用 Shiva 了。指向某个资源,例如 /artists,即可查看其运行情况。
抓取歌词
如前所述,歌词会被抓取,您可以为包含所需歌词的特定网站创建自己的抓取器。您只需要在 /shiva/lyrics 目录中创建一个包含继承自 LyricScraper 的类的 Python 文件即可。以下模板清楚地说明了它有多么容易。假设我们有一个文件 /shiva/lyrics/mylyrics.py
从 shiva.lyrics import LyricScraper
class MyLyricsScraper(LyricScraper):
“““ Fetches lyrics from mylyrics.com ”””
def fetch(self, artist, title):
# Magic happens here
if not lyrics:
return False
self.lyrics = lyrics
self.source = lyrics_url
return True
之后,您需要将全新的抓取器添加到本地 .py 配置文件中的 scrapers 列表中
SCRAPERS = {
‘lyrics’: (
‘mylyrics.MyLyricScraper’,
)
}
Shiva 将实例化您的抓取器并调用 fetch() 方法。如果它返回 True,则它将继续在 lyrics 属性中查找歌词,以及从 source 属性中抓取歌词的 URL
if scraper.fetch():
lyrics = Lyrics(text=scraper.lyrics, source=scraper.source,
track=track)
g.db.session.add(lyrics)
g.db.session.commit()
return lyrics
查看现有抓取器以获取实际示例。
仅当您请求特定曲目时才会获取歌词,而不是检索多个曲目时。这样做的原因是每个曲目的歌词可能需要两个或多个请求,并且我们不希望在检索艺术家的唱片目录时对网站进行 DoS 攻击。那不好。
设置文件服务器
开发服务器顾名思义,不应用于生产环境。事实上,这几乎是不可能的,因为它一次只能服务一个请求,并且音频元素将在文件播放期间保持连接打开,因此完全阻塞了 API。
Shiva 提供了一种将文件服务委托给专用服务器的方法。为此,您必须编辑 /shiva/config/local.py 文件,并编辑 MEDIA_DIRS 设置。此选项需要一个 MediaDir 对象元组,该元组提供定义要扫描的目录和通过套接字为文件提供服务的机制
MediaDir(‘/srv/music’, url=’https://:8080’)
这样,您的应用程序在哪个套接字中运行就无关紧要了,/src/music 目录中的文件将通过 url 属性中定义的 URL 提供服务。此对象还允许定义要扫描的子目录。例如
MediaDir(‘/srv/music’, dirs=(‘/pop’, ‘/rock’), url=’https://:8080’)
在这种情况下,只会扫描 /srv/music/pop 和 /srv/music/rock 目录。您可以根据需要定义任意数量的 MediaDir 对象。假设您有文件 /srv/music/rock/nofx-dinosaurs_will_die.mp3,一旦到位,该曲目的 download_uri 属性将为
{
"slug": "dinosaurs-will-die",
"title": "Dinosaurs Will Die",
"uri": "/track/510",
"id": 510,
"stream_uri": "https://:8080/nofx-dinosaurs_will_die.mp3"
}
您自己的音乐播放器
一旦您的音乐被扫描并且 API 运行,您就需要一个使用这些服务并播放您的音乐的客户端,例如 Shiva-Client。该客户端作为使用 AngularJS 和 HTML5 技术(如音频和拖放)的单页应用程序构建,将允许您浏览您的目录,将文件添加到播放列表并播放它们。
由于同源策略,您将需要一个充当 Web 应用程序和 API 之间代理的服务器。为此,您将在存储库中找到一个 server.py 文件,它将为您执行此操作。此文件唯一的依赖项是 Flask,但我假设您已经安装了它。现在只需执行它
python server.py
这将在 https://:9001/ 上运行服务器
访问该 URI 并检查服务器输出,您将不仅看到应用程序所需的媒体(如图像和 JavaScript 文件),还看到 /api/artists 调用。这就是代理。对 /api/ 的任何调用都将由服务器重定向到 https://:9002/
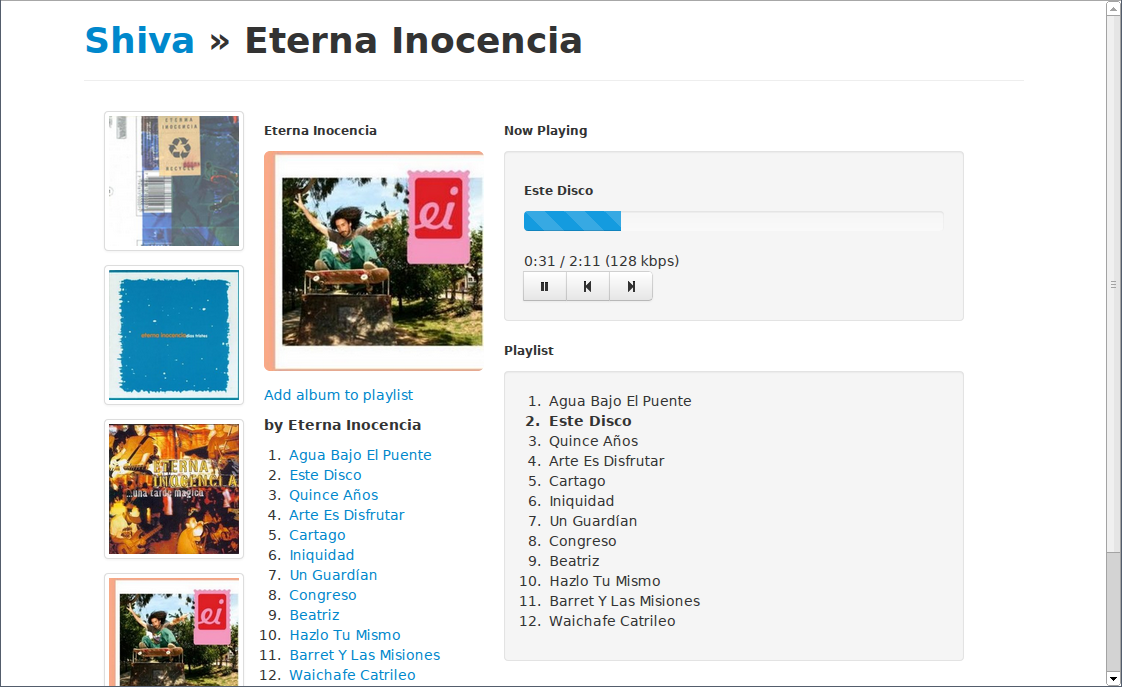
如果您打开一个控制台(如 Firebug),您将在全局命名空间中看到一个 Shiva 对象。在其内部,您将找到两个主要属性,Player 和 Playlist。这些对象封装了排队和播放音乐的所有逻辑。Player 仅保存当前曲目,充当 HTML5 的 Audio 元素的包装器。一开始可能看起来不自然的是,通常您不会与 Player 交互,而是与 Playlist 交互,后者充当外观,因为它知道所有曲目并指示 Player 加载和播放下一首曲目。
这些对象的源代码位于 js/controllers.js 文件中。您还将在其中找到 AngularJS 控制器,这些控制器执行对 API 的实际调用。它仅包含两个调用,一个用于获取艺术家列表,另一个用于获取艺术家的唱片目录。检查代码,非常简单。
因此,一旦曲目被添加到播放列表中,您就可以执行以下操作,例如播放它
Shiva.Playlist.play()
停止它
Shiva.Playlist.stop()
或跳过曲目
Shiva.Playlist.next()
进行了一些性能优化,以尽可能降低处理量。例如,您将在播放音乐时看到一个进度条,该进度条仅在需要显示时才会更新。事件将在不需要时被删除,以避免对不可见元素进行任何不必要的 DOM 操作
Shiva.Player.audio.removeEventListener('timeupdate', Shiva.Player.audio.timeUpdateHandler, false);
现在和未来
在撰写本文时,Shiva 处于可用状态并提供了核心功能,但它仍然很年轻并且缺少一些重要功能。这也是本文没有深入研究代码的原因,因为它将迅速发生变化。要了解当前状态,请查看文档。
如果您想做出贡献,有很多方法可以帮助该项目。首先,为服务器和客户端都创建分支,使用它们并将您的改进发送回上游。
请求功能。如果您认为“看起来不错,但我不会使用它”,请写下原因并发送这些想法,理想情况下还有一些关于如何解决这些想法的建议。缺乏功能的清单很长;您的帮助对于确定优先级至关重要。
但最重要的是;构建您自己的客户端。您知道您喜欢自己喜欢的音乐播放器的哪些功能,也知道哪些功能很糟糕。为现有客户端创建分支并进行修改,或从头开始创建自己的客户端,为音乐播放器的旧世界带来新的想法。为 API 提供新的和创造性的用途。
有很多工作要做,在许多不同的方面。未来的一些计划是
- Shiva-jslib:一个易于使用的 JavaScript 库,封装了 API 调用,因此您可以专注于构建 GUI 并忘记协议。
- Shiva 到 Shiva 通信:让两个(或更多)Shiva 实例相互通信,以允许在服务器之间透明地共享音乐。
- Shiva-FXOS:Firefox OS 的 Shiva 客户端。
以及您能想到的任何其他事情。编写代码,发送想法,编写您的客户端。
快乐地黑客攻击!
关于 Alvaro Mouriño
Alvaro 是一位来自乌拉圭的自由软件黑客活动家,目前居住在柏林。多年来一直作为活跃成员参与自由软件团体,组织了许多当地活动并在南锥体地区参加了许多其他活动。
关于 Robert Nyman [荣誉编辑]
Mozilla Hacks 的技术布道师和编辑。发表演讲和博客文章,内容涉及 HTML5、JavaScript 和开放网络。Robert 坚定地相信 HTML5 和开放网络,自 1999 年以来一直从事 Web 前端开发工作——在瑞典和纽约市。他还在 http://robertnyman.com 上定期发表博客文章,并且喜欢旅行和结识新朋友。
26 条评论