
asm.js 是 JavaScript 的一个简单子集,非常容易优化,适合作为来自 C 和 C++ 等语言的编译器目标。今年早些时候,Firefox 可以以大约原生速度的一半运行 asm.js 代码 - 也就是说,由 emscripten 生成的 C++ 代码可以以大约原生编译的相同 C++ 代码速度的一半运行 - 我们认为通过改进 emscripten(从 C++ 生成 asm.js 代码)和 JS 引擎(运行 asm.js 代码),可以更接近原生速度。
从那时起,许多加速已经出现,其中很多是小型和特定的,但也有一些大型功能。例如,Firefox 最近获得了优化某些浮点运算的能力,使其能够使用 32 位浮点数进行运算,而不是 64 位双精度数,在某些情况下可以提供显著的加速,如该链接所示。这种优化工作是通用的,适用于任何碰巧以这种方式可优化的 JavaScript 代码。在完成这项工作并实现加速之后,没有理由不将 float32 添加到 asm.js 类型系统中,以便 asm.js 代码可以专门从中受益。
在 emscripten 和 SpiderMonkey 中实现这一点的工作最近已经完成,以下是性能数据
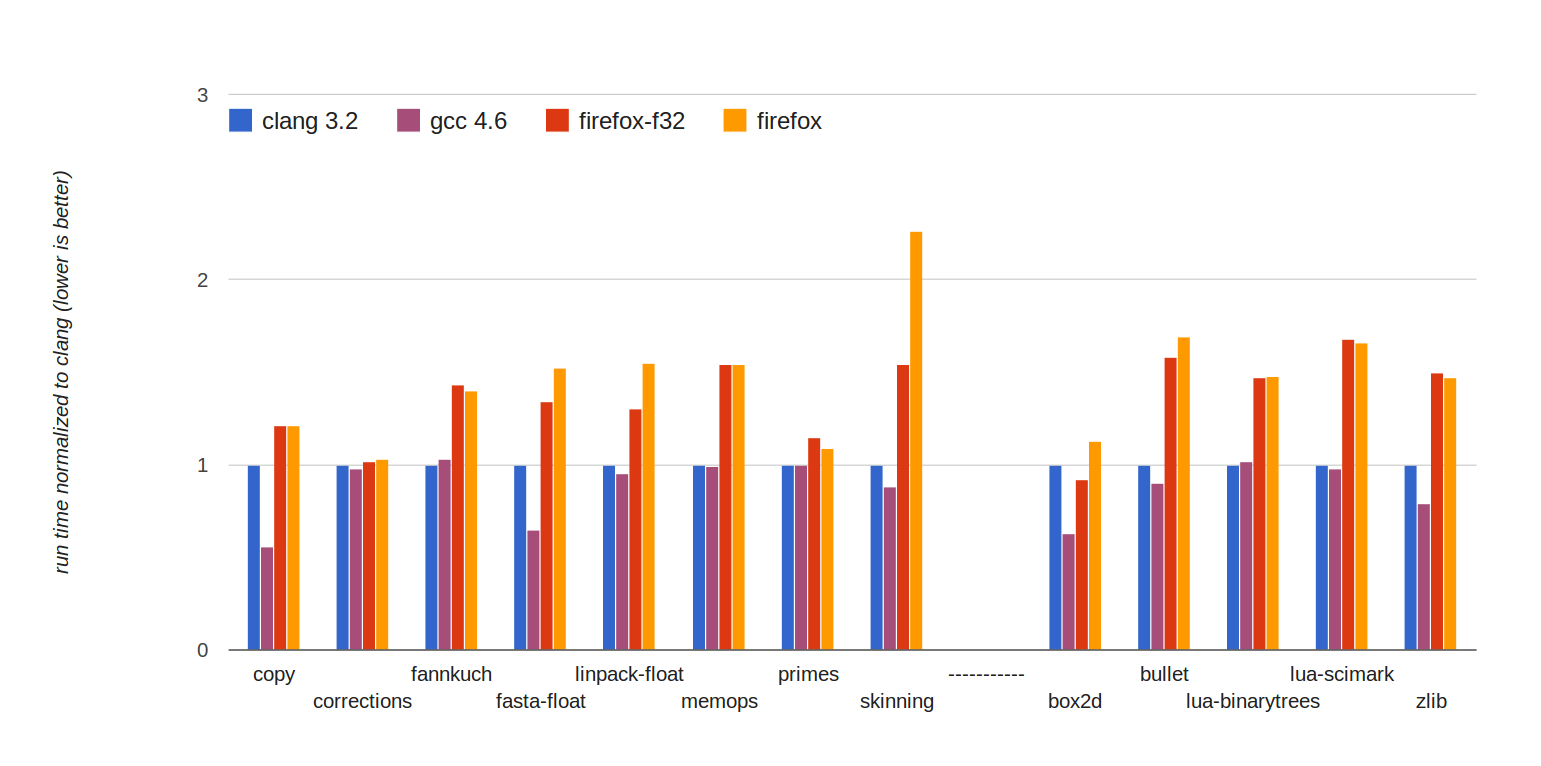
运行时间归一化为 clang,因此越低越好。红色条(firefox-f32)代表 Firefox 在使用 float32 的 emscripten 生成的代码上运行。如图表所示,具有 float32 优化的 Firefox 可以以比原生速度快 1.5 倍或更快的速度运行所有这些基准测试。这是对今年早些时候的重大改进,当时正如之前提到的,事情更接近原生速度的两倍慢。您还可以通过将其与旁边的橙色条(firefox)进行比较,来查看由于 float32 优化带来的具体改进 - 在诸如蒙皮、linpack 和 box2d 这样的浮点密集型基准测试中,加速非常明显。
关于这些数字,还需要注意的一点是,不仅显示了一个原生编译器,而是两个,clang 和 gcc。在一些基准测试中,clang 和 gcc 之间的差异很大,这表明虽然我们经常谈论“比原生速度慢多少倍”,但“原生速度”是一个有点宽泛的术语,因为原生编译器之间存在差异。
事实上,在一些基准测试中,比如 box2d、fasta 和 copy,asm.js 与 clang 一样接近,甚至比 clang 更接近 gcc。甚至有一个例子,asm.js 在 box2d 上略微超过了 clang(gcc 也在该基准测试中超过了 clang,幅度更大,因此 clang 的后端代码生成可能只是碰巧有点不幸)。
总的来说,这表明“原生速度”不是一个单一数字,而是一个范围。看起来 Firefox 上的 asm.js 非常接近该范围 - 也就是说,虽然它平均比 clang 和 gcc 慢,但它慢的程度与原生编译器之间的差异并不远。
请注意,emscripten 中默认情况下关闭了 float32 代码生成。这是故意的,因为它既可以提高性能,又可以确保正确的 C++ 浮点数语义,但它也会增加代码大小 - 由于添加了 Math.fround 调用 - 这在某些情况下可能是有害的,尤其是在尚未支持 Math.fround 的 JavaScript 引擎中。
有一些方法可以解决这个问题,例如轮廓选项,它可以减少最大函数大小。我们还有一些其他关于如何在 emscripten 中改进代码生成的想法,因此我们将继续尝试这些方法,以及关注 Math.fround 在浏览器中的支持情况(目前 Firefox 和 Safari 支持)。希望在不久的将来,我们可以默认在 emscripten 中启用 float32 优化。
总结
总之,上面的图表显示了 asm.js 性能越来越接近原生速度。虽然由于上述原因,我不建议人们现在就使用 float32 优化进行构建 - 希望很快就能实现!- 但这是一个令人兴奋的性能提升。甚至目前的性能数据 - 比原生速度快 1.5 倍或更快的速度 - 也不是可以达到的极限,因为无论是在 emscripten 还是在 JavaScript 引擎中,都还有很多重大改进正在进行或正在计划中。
关于 Alon Zakai
Alon 是 Mozilla 研究团队的一员,他在那里主要负责 Emscripten,这是一个将 C 和 C++ 编译为 JavaScript 的编译器。Alon 于 2010 年创立了 Emscripten 项目。
关于 Robert Nyman [荣誉编辑]
Mozilla Hacks 的技术布道师和编辑。进行演讲和博客文章,主题包括 HTML5、JavaScript 和开放网络。Robert 是 HTML5 和开放网络的坚定支持者,从 1999 年开始从事 Web 前端开发工作 - 在瑞典和纽约市。他还在http://robertnyman.com 定期撰写博客,喜欢旅行和结识新朋友。
20 条评论