
WebGL 将硬件加速的 3D 图形带到了 Web。许多 WebGL 2 的功能今天都可以作为 WebGL 扩展使用。在这篇文章中,我们描述了如何使用 WEBGL_draw_buffers 扩展来创建一个包含大量动态灯光场景,该场景使用了一种称为延迟着色的技术,该技术在顶级游戏中很受欢迎。

如今,大多数 WebGL 引擎使用前向着色,其中光照是在几何体变换的同一通道中计算的。这使得难以支持大量动态灯光和不同类型的灯光。
前向着色可以使用每个灯光一个通道。渲染场景看起来像
foreach light {
foreach visible mesh {
if (light volume intersects mesh) {
render using this material/light shader;
accumulate in framebuffer using additive blending;
}
}
}
这需要为每个材质/灯光类型组合使用不同的着色器,这会累加起来。从性能的角度来看,每个网格需要针对每个灯光渲染一次(顶点变换、光栅化、片段着色器的材质部分等),而不是只渲染一次。此外,最终未通过深度测试的片段仍然会被着色,但由于早期 Z 和 Z 剔除硬件优化以及从前往后的排序或 Z 预通道,这不像添加灯光那样糟糕。
为了优化性能,通常使用具有有限影响的灯光源。与现实世界中的灯光不同,我们允许来自点光源的光线只传播有限距离。但是,即使灯光的有效范围与网格相交,它也可能只影响网格的一小部分,但整个网格仍然会被渲染。
在实践中,前向着色器通常会尝试在单个通道中尽可能多地完成工作,从而导致需要在单个着色器中将灯光连接在一起的复杂系统。例如
foreach visible mesh {
find lights affecting mesh;
Render all lights and materials using a single shader;
}
最大的缺点是所需的着色器数量,因为需要为每个材质/灯光(而不是灯光类型)组合使用不同的着色器。这使得着色器更难编写,增加了编译时间,通常需要运行时编译,并增加了需要排序的着色器数量。虽然网格只渲染一次,但对于未通过深度测试的片段来说,这也会产生与多通道方法相同的性能缺陷。
延迟着色
延迟着色采用了一种与前向着色不同的方法,它将渲染分为两个通道:g 缓冲区通道,它变换几何体并将位置、法线和材质属性写入称为 g 缓冲区的纹理,以及灯光累积通道,它将灯光作为一系列屏幕空间后处理效果执行。
// g-buffer pass
foreach visible mesh {
write material properties to g-buffer;
}
// light accumulation pass
foreach light {
compute light by reading g-buffer;
accumulate in framebuffer;
}
这将灯光与场景复杂度(三角形数量)分离,并且每个材质和每种灯光类型只需要一个着色器。由于光照发生在屏幕空间,因此未通过 Z 测试的片段不会被着色,这实际上将深度复杂度降低到 1。但也有一些缺点,例如其高内存带宽使用率,并且使得半透明和抗锯齿变得困难。
直到最近,WebGL 在实现延迟着色方面一直存在障碍。在 WebGL 中,片段着色器只能写入一个纹理/渲染缓冲区。对于延迟着色来说,g 缓冲区通常由多个纹理组成,这意味着场景需要在 g 缓冲区通道中多次渲染。
WEBGL_draw_buffers
现在,借助 WEBGL_draw_buffers 扩展,片段着色器可以写入多个纹理。要在 Firefox 中使用此扩展,请浏览到 about:config 并启用 webgl.enable-draft-extensions。然后,要确保您的系统支持 WEBGL_draw_buffers,请浏览到 webglreport.com 并验证它是否在页面底部的扩展列表中。

要使用此扩展,首先对其进行初始化
var ext = gl.getExtension('WEBGL_draw_buffers');
if (!ext) {
// ...
}
我们现在可以将多个纹理(下面示例中的 tx[])绑定到不同的帧缓冲区颜色附件。
var fb = gl.createFramebuffer();
gl.bindFramebuffer(gl.FRAMEBUFFER, fb);
gl.framebufferTexture2D(gl.FRAMEBUFFER, ext.COLOR_ATTACHMENT0_WEBGL, gl.TEXTURE_2D, tx[0], 0);
gl.framebufferTexture2D(gl.FRAMEBUFFER, ext.COLOR_ATTACHMENT1_WEBGL, gl.TEXTURE_2D, tx[1], 0);
gl.framebufferTexture2D(gl.FRAMEBUFFER, ext.COLOR_ATTACHMENT2_WEBGL, gl.TEXTURE_2D, tx[2], 0);
gl.framebufferTexture2D(gl.FRAMEBUFFER, ext.COLOR_ATTACHMENT3_WEBGL, gl.TEXTURE_2D, tx[3], 0);
为了进行调试,我们可以通过调用 gl.checkFramebufferStatus 来检查附件是否兼容。此函数很慢,不应该在发布代码中频繁调用。
if (gl.checkFramebufferStatus(gl.FRAMEBUFFER) !== gl.FRAMEBUFFER_COMPLETE) {
// Can't use framebuffer.
// See http://www.khronos.org/opengles/sdk/docs/man/xhtml/glCheckFramebufferStatus.xml
}
接下来,我们将颜色附件映射到片段着色器将使用 gl_FragData 写入的绘图缓冲区槽位。
ext.drawBuffersWEBGL([
ext.COLOR_ATTACHMENT0_WEBGL, // gl_FragData[0]
ext.COLOR_ATTACHMENT1_WEBGL, // gl_FragData[1]
ext.COLOR_ATTACHMENT2_WEBGL, // gl_FragData[2]
ext.COLOR_ATTACHMENT3_WEBGL // gl_FragData[3]
]);
传递给 drawBuffersWEBGL 的数组的最大大小取决于系统,可以通过调用 gl.getParameter(gl.MAX_DRAW_BUFFERS_WEBGL) 来查询。在 GLSL 中,这也可以作为 gl_MaxDrawBuffers 获得。
在延迟着色几何体通道中,片段着色器会写入多个纹理。一个简单的直通片段着色器是
#extension GL_EXT_draw_buffers : require
precision highp float;
void main(void) {
gl_FragData[0] = vec4(0.25);
gl_FragData[1] = vec4(0.5);
gl_FragData[2] = vec4(0.75);
gl_FragData[3] = vec4(1.0);
}
即使我们在 JavaScript 中使用 gl.getExtension 初始化了扩展,GLSL 代码仍然需要包含 #extension GL_EXT_draw_buffers : require 才能使用该扩展。使用该扩展后,输出现在是映射到帧缓冲区颜色附件的 gl_FragData 数组,而不是 gl_FragColor,传统上是输出。
g 缓冲区
在我们的延迟着色实现中,g 缓冲区由四个纹理组成:眼空间位置、眼空间法线、颜色和深度。位置、法线和颜色使用浮点 RGBA 格式,通过 OES_texture_float 扩展实现,深度使用无符号短整型 DEPTH_COMPONENT 格式。
位置纹理

法线纹理

颜色纹理

深度纹理

使用 g 缓冲区进行灯光累积

此 g 缓冲区布局对于我们的测试来说很简单。虽然四个纹理对于完整的延迟着色引擎来说很常见,但优化的实现会尝试通过降低精度、从深度重建位置、将值打包在一起、使用不同的分布等等来使用最少的内存。
借助 WEBGL_draw_buffers,我们可以使用单个通道来写入 g 缓冲区中的每个纹理。与使用每个纹理一个通道相比,这提高了性能并减少了 JavaScript 代码和 GLSL 着色器的数量。如下图所示,随着场景复杂度的增加,使用 WEBGL_draw_buffers 的好处也随之增加。由于增加场景复杂度需要更多 drawElements/drawArrays 调用,更多 JavaScript 开销,以及变换更多三角形,WEBGL_draw_buffers 通过在单个通道中写入 g 缓冲区而不是每个纹理一个通道来提供好处。

所有性能数据均使用 NVIDIA GT 620M(一款具有 96 个内核的低端 GPU)在 FireFox 26.0(Windows 8)上测量。在上图中,使用了 20 个点光源。灯光强度与当前位置和灯光位置之间距离的平方成反比下降。每个斯坦福龙都有 100,000 个三角形,需要五个绘制调用,因此,例如,当渲染 25 条龙时,会发出 125 个绘制调用(以及相关的状态更改),并总共变换 2,500,000 个三角形。

WEBGL_draw_buffers 测试场景,这里显示了 100 个斯坦福龙。
当然,当场景复杂度非常低时,例如只有一条龙,g 缓冲区通道的成本很低,因此使用 WEBGL_draw_buffers 节省的成本微不足道,尤其是在场景中存在大量灯光的情况下,这会导致灯光累积通道的成本增加,如下图所示。
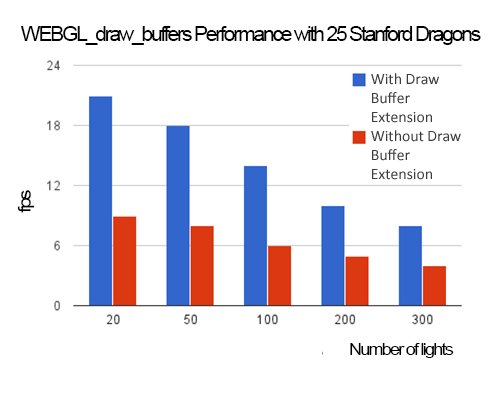
延迟着色需要大量的 GPU 内存带宽,这会影响性能并增加功耗。在 g 缓冲区通道之后,灯光累积通道的朴素实现将每个灯光渲染为一个全屏四边形,并读取每个 g 缓冲区的全部内容。由于大多数灯光类型(如点光源和聚光灯)都会衰减并具有有限的有效范围,因此可以使用世界空间包围盒或紧密的屏幕空间包围矩形来代替全屏四边形。我们的实现为每个灯光渲染了一个全屏四边形,并使用剪切测试将片段着色器限制在灯光的有效范围内。
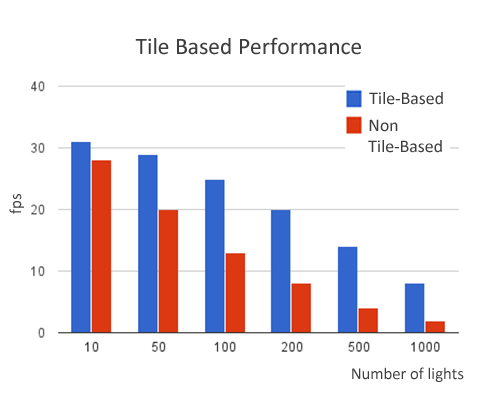
基于平铺的延迟着色
基于平铺的延迟着色将此方法更进一步,将屏幕分成平铺,例如 16×16 像素,然后确定哪些灯光影响每个平铺。然后将灯光-平铺信息传递给着色器,并且 g 缓冲区只读取一次,用于所有灯光。由于这极大地减少了内存带宽,因此提高了性能。下图显示了 sponza 场景(66,450 个三角形和 38 个绘制调用)在 1024×768 分辨率、32×32 个平铺下的性能。
平铺大小会影响性能。较小的平铺需要更多 JavaScript 开销来创建灯光-平铺信息,但在灯光着色器中需要较少的计算。较大的平铺则相反。因此,选择合适的平铺对于性能来说非常重要。下图显示了平铺大小与性能之间的关系,使用了 100 个灯光。

下面显示了每个平铺中灯光数量的可视化。黑色平铺表示没有灯光与它们相交,白色平铺表示灯光数量最多。


平铺可视化的着色版本。
结论
WEBGL_draw_buffers 是一个有用的扩展,可以提高 WebGL 中延迟着色的性能。查看 实时演示 以及我们在 github 上的 代码。
致谢
我们为课程 CIS 565:GPU 编程与架构(宾夕法尼亚大学 计算机图形程序 的一部分)实现了此项目。感谢 Liam Boone 的支持,以及 Eric Haines 和 Morgan McGuire 对本文的审阅。
参考文献
- Killzone 2 中的延迟渲染,作者:Michal Valient
- 灯光预通道,作者:Wolfgang Engel
- 用于小型 G 缓冲区的紧凑法线存储,作者:Aras Pranckevicius
- 平铺着色,作者:Ola Olsson 和 Ulf Assarsson
- 当前和未来渲染管线的延迟渲染,作者:Andrew Lauritzen
- Z 预通道被认为无关紧要,作者:Morgan McGuire
关于 田思洁
宾夕法尼亚大学的研究生。我正在学习计算机图形学和游戏技术。热衷于编码和游戏。期待进入游戏行业。
关于 Patrick Cozzi
Patrick 是 Analytical Graphics, Inc. 的首席图形架构师,也是宾夕法尼亚大学的讲师。
关于 Robert Nyman [荣誉编辑]
Mozilla Hacks 的技术布道者和编辑。关于 HTML5、JavaScript 和开放网络发表演讲和博客。Robert 是 HTML5 和开放网络的坚定支持者,自 1999 年起就从事网络前端开发工作 - 在瑞典和纽约市。他还经常在 http://robertnyman.com 上写博客,喜欢旅行和结识新朋友。
12 条评论