
PredictionIO 是一个开源机器学习服务器,软件开发人员可以使用它来创建预测功能,例如个性化、推荐和内容发现。构建一个用于预测用户偏好和个性化内容的生产级引擎曾经非常耗时。但现在有了 PredictionIO 的最新 v0.7 版本,这一切都变得简单了。
我们将向您展示 PredictionIO 如何简化数据处理过程,并使其对开发人员和生产部署更加友好。我们将使用电影推荐案例进行说明。我们希望为每个用户提供**“个性化电影推荐 Top 10”**。此外,我们还提供**“如果您喜欢这部电影,您可能还会喜欢以下 10 部电影……”**。
先决条件
首先,让我们解释一下 PredictionIO 中使用的一些术语。
应用 (Apps)
PredictionIO 中的应用并非指包含程序代码的应用程序。相反,它们对应于使用 PredictionIO 的软件应用程序。应用可以被视为不同数据集之间的逻辑隔离。一个应用可以有多个引擎,但每个引擎只能与一个应用关联。
引擎 (Engines)
引擎是外部应用程序可以通过 API 与之交互的逻辑标识。在撰写本文时,引擎有两种类型:项目推荐和项目相似性。每个引擎都提供独特的设置以满足不同的需求。一个引擎在任何时间只能部署一个算法。
算法 (Algorithms)
算法是生成预测模型的实际计算代码。每个引擎都带有一个默认的通用算法。如果您有任何特定需求,您可以用另一个算法替换它,甚至可以微调其参数。
动手实践
准备环境
假设已安装了最新的 64 位 Ubuntu Linux,第一步是安装 Java 7 和 MongoDB。Java 7 可以通过以下命令安装:sudo apt-get install openjdk-7-jdk。MongoDB 可以按照在 Ubuntu 上安装 MongoDB中描述的步骤进行安装。
注意:任何最新的 64 位 Linux 都应该可以工作。诸如 ArchLinux、CentOS、Debian、Fedora、Gentoo、Slackware 等发行版都应该可以与 PredictionIO 良好地配合使用。Mac OS X 也受支持。
运行 PredictionIO 及其组件 Apache Hadoop 需要 Java 7。从 PredictionIO 0.7.0 开始,Apache Hadoop 为可选组件。
PredictionIO 分别需要 MongoDB 2.4.x 来读取和写入行为数据和预测模型。
安装 PredictionIO 及其组件
要安装 PredictionIO,只需下载二进制发行版并解压缩即可。在本文中,我们假设 PredictionIO 0.7.0 已安装在/opt/PredictionIO-0.7.0中。除非另有说明,否则本文后面使用相对路径时,它们将相对于此安装路径。
安装过程概述在在 Linux 上安装 PredictionIO中。
要启动和停止 PredictionIO,您可以分别使用bin/start-all.sh和bin/stop-all.sh。
微调 Apache Hadoop(可选)
PredictionIO 依赖于 Apache Hadoop 进行分布式数据处理和存储。它安装在 vendors/hadoop-1.2.1 中。以下是关于一些优化机会的概述。
vendors/hadoop-1.2.1/conf/hdfs-site.xml
dfs.name.dir和dfs.data.dir可以设置为指向大容量且持久化的存储。默认值通常指向临时存储(通常为/tmp),操作系统可能会定期清除此存储。
vendors/hadoop-1.2.1/conf/mapred-site.xml
mapred.tasktracker.map.tasks.maximum和mapred.tasktracker.reduce.tasks.maximum控制映射器和化简器作业(数据处理作业)的最大数量。一个好的开始是将第一个值设置为 CPU 内核数,并将第二个值设置为第一个值的一半。如果您没有在单独的机器上运行 Hadoop,则在生产环境中提供预测时,应稍微减少这些值以留出余量。
mapred.child.java.opts控制每个映射器和化简器作业的 Java 虚拟机选项。通常,即使所有映射器和化简器作业都在运行,也最好保留足够的内存。如果您最多有 4 个映射器和 2 个化简器,那么如果您的机器有超过 10GB 的 RAM,每个映射器和化简器分配 1GB 堆空间(-Xmx1g)(总共 6GB 最大)将是合理的。
io.sort.mb控制内部排序缓冲区的大小,通常设置为子进程堆空间的一半。如果您在上面将其设置为 1GB,则可以将其设置为 512MB。
在 PredictionIO 中创建应用
这可以通过登录位于服务器端口 9000 上的 PredictionIO Web UI 来完成。
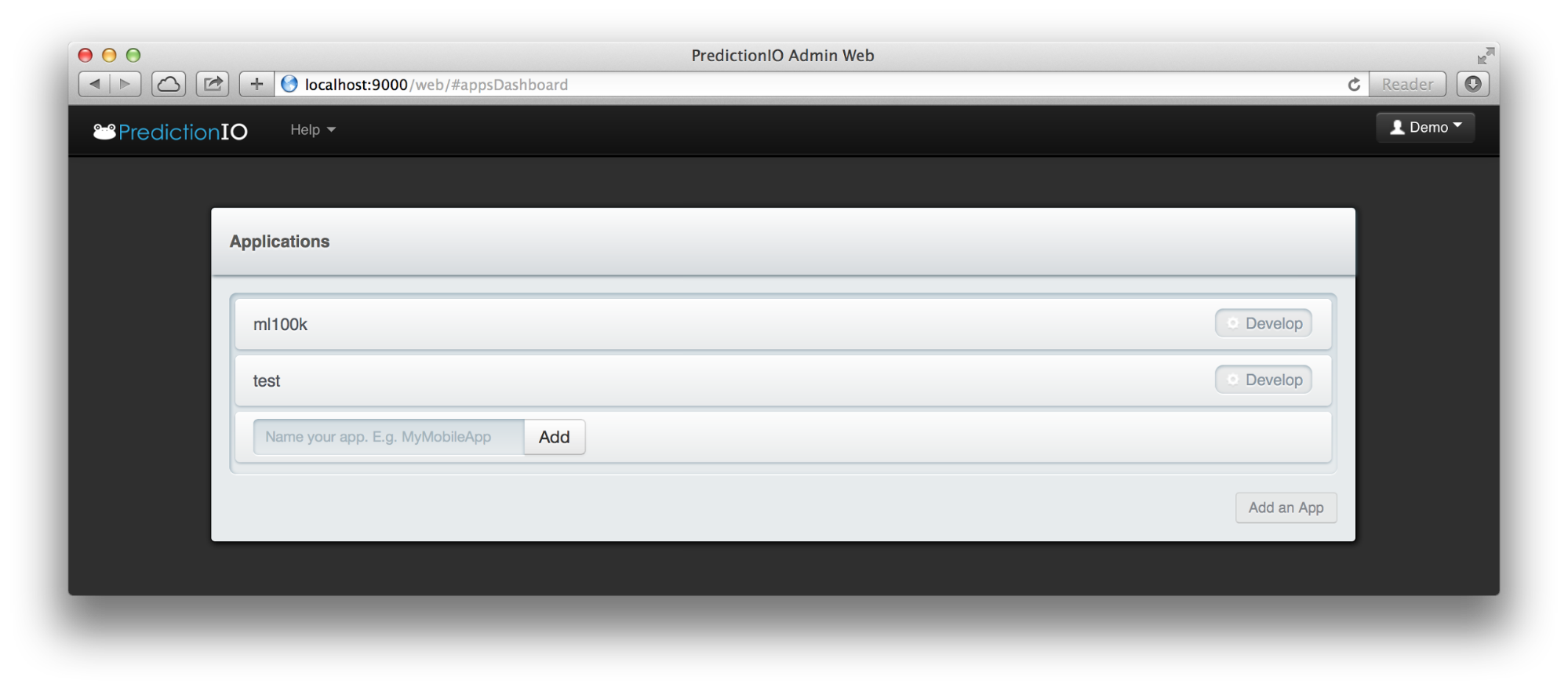
以下是登录并单击“添加应用”按钮后的第一个屏幕。要添加应用,只需输入应用名称并单击“添加”。
将数据导入 PredictionIO
在导入数据之前,必须获取目标应用的应用密钥。这可以通过单击应用旁边的“开发”来完成。以下是在此之后看到的屏幕。
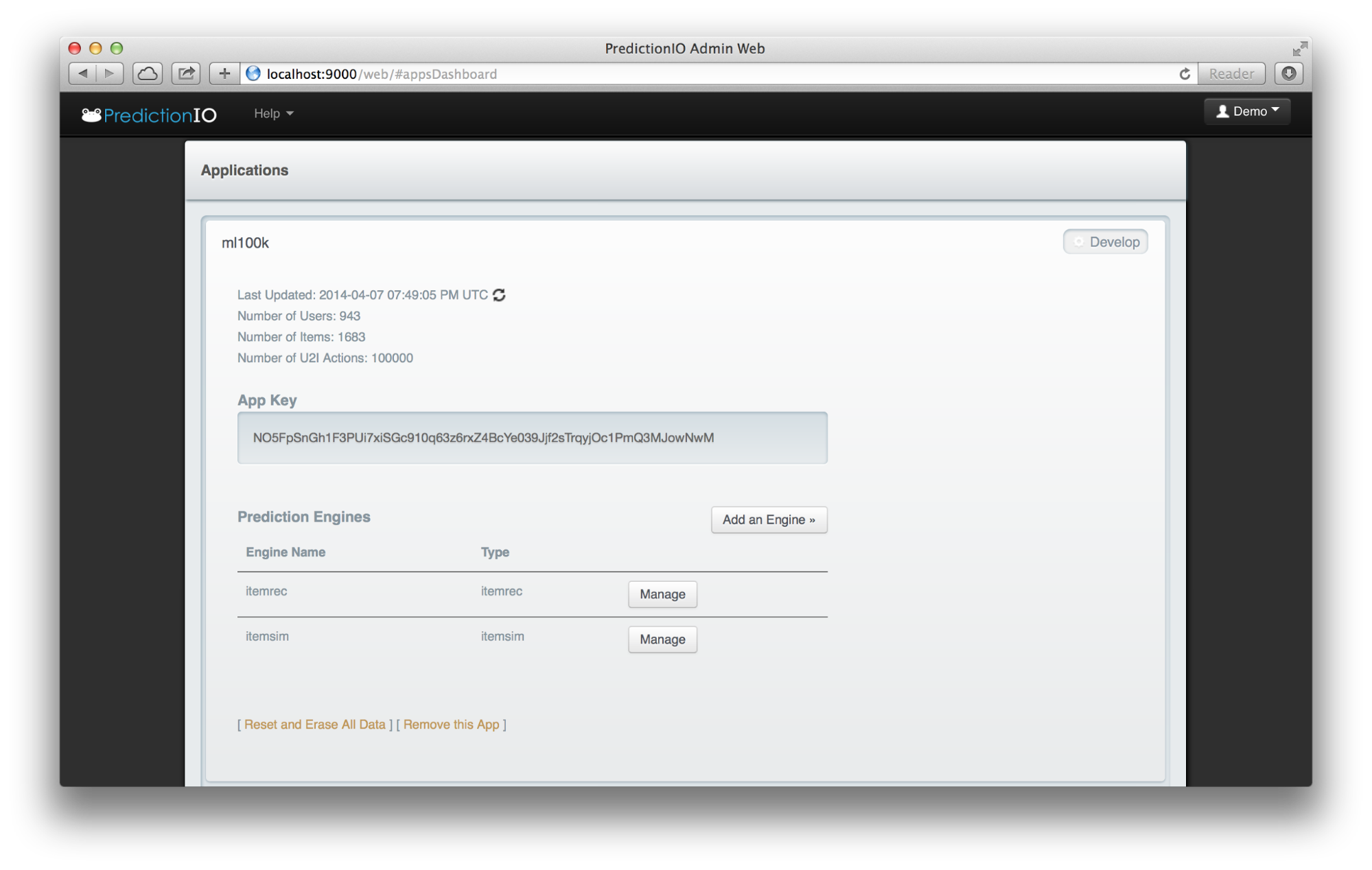
如上所示,“ml100k”应用的应用密钥为NO5FpSnGh1F3PUi7xiSGc910q63z6rxZ4BcYe039Jjf2sTrqyjOc1PmQ3MJowNwM。应用密钥是唯一的,您的应用密钥应该不同。
要解析 MovieLens 100k 数据集并将其导入 PredictionIO,可以使用import_ml.rb Gist。它需要 PredictionIO Ruby gem,可以通过以下命令安装:sudo gem install predictionio。
导入整个数据集很简单
ruby import_ml.rb NO5FpSnGh1F3PUi7xiSGc910q63z6rxZ4BcYe039Jjf2sTrqyjOc1PmQ3MJowNwM u.data
u.data是 MovieLens 100k 数据集中的一个文件,可以从GroupLens 网站获取。
添加引擎
只需单击“添加引擎”按钮即可添加两个引擎。在我们的案例中,我们添加了“itemrec”和“itemsim”引擎。添加后,它们将自动开始训练,并使用默认的小时计划。
获取预测结果
目前,您可以从以下两个示例 URL 访问预测结果(API 服务器在端口 8000 上)
“个性化电影推荐 Top 10”
https://:8000/engines/itemrec/itemrec/topn.json?pio_appkey=NO5FpSnGh1F3PUi7xiSGc910q63z6rxZ4BcYe039Jjf2sTrqyjOc1PmQ3MJowNwM&pio_n=10&pio_uid=1
“如果您喜欢这部电影,您可能还会喜欢以下 10 部电影……”
https://:8000/engines/itemsim/itemsim/topn.json?pio_appkey=NO5FpSnGh1F3PUi7xiSGc910q63z6rxZ4BcYe039Jjf2sTrqyjOc1PmQ3MJowNwM&pio_n=10&pio_iid=1
您可以更改上面的pio_uid和pio_iid参数以查看其他用户/项目的結果。建议您利用这些端点来验证这些结果。您还可以利用我们的官方和社区驱动的 SDK来简化此过程。贡献的 SDK也可供使用。
PredictionIO v0.7 的新功能
通过对 GraphChi(一个基于磁盘的大规模图计算框架)的扩展支持,开发人员现在可以在同一个平台上评估和部署 GraphChi 和 Apache Mahout 中的算法!
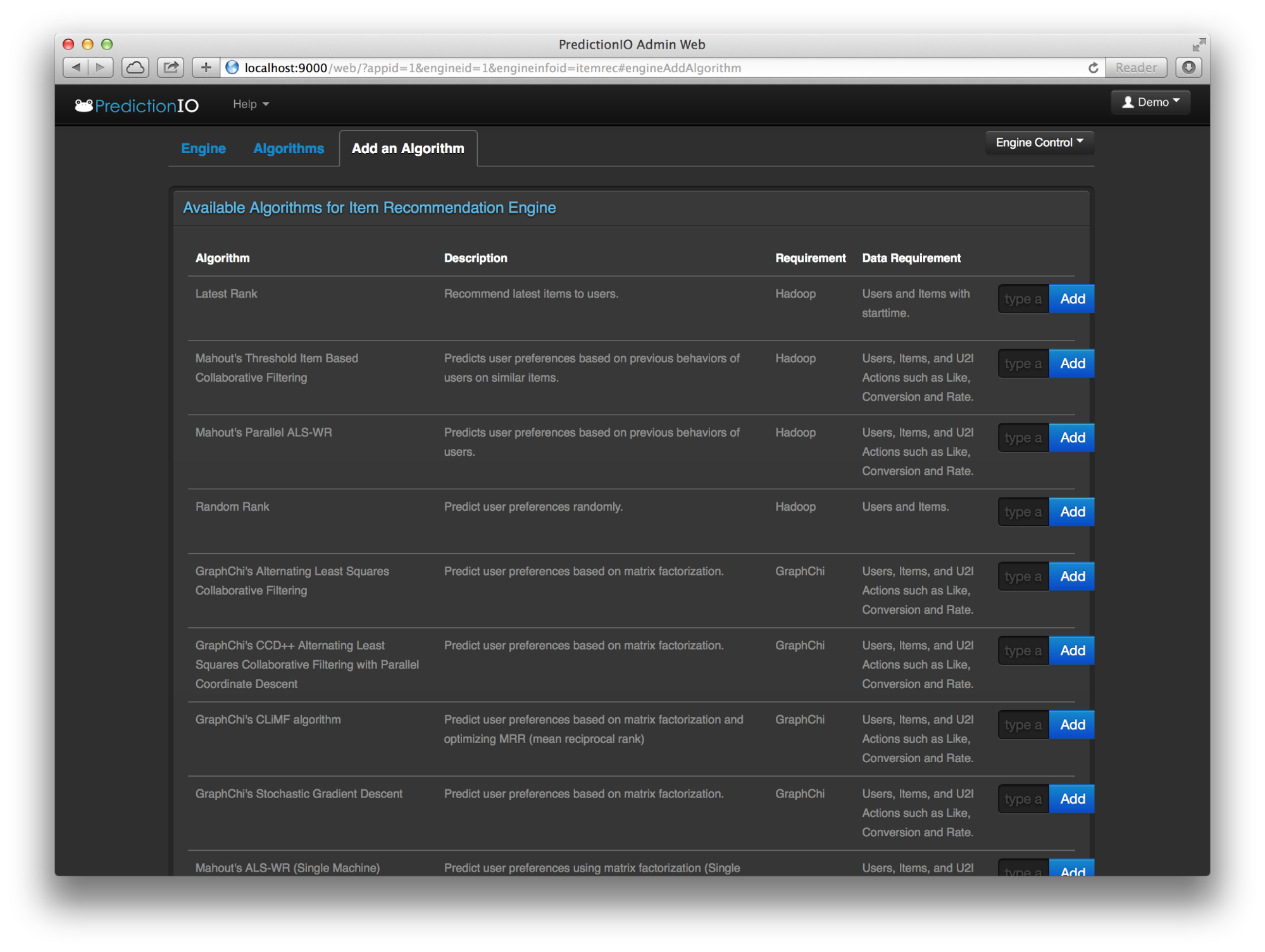
尽情享受!
关于 Donald Szeto
作为 PredictionIO(一个开源机器学习服务器)的联合创始人兼 CTO,运用 10 多年的并发软件和硬件工程经验。
关于 Robert Nyman [荣誉编辑]
Mozilla Hacks 的技术布道师和编辑。发表有关 HTML5、JavaScript 和开放网络的演讲和博客文章。Robert 坚定地相信 HTML5 和开放网络,自 1999 年以来一直从事 Web 前端开发工作 - 在瑞典和纽约市。他还定期在http://robertnyman.com上发表博客文章,并且热爱旅行和结识新朋友。
8 条评论