
大家好,我叫 Thorben,我在奥斯陆的 Opera Software 工作,不是 Mozilla。那么,我怎么会为 Mozilla Hacks 写文章呢?也许你知道 Opera 浏览器没有默认的 PDF 阅读器,这是我们想改变的事情。但如何添加一个呢?从 Adobe 或 Foxit 购买?自己开发?
介绍 PDF.js
在我们调查选项时,我们很快发现了 PDF.js。该项目的目的是使用 JavaScript 和 Canvas 在浏览器中创建一个功能齐全的 PDF 阅读器。是的,这听起来有点疯狂,但它是有道理的:浏览器需要擅长处理文本、图像、字体和矢量图形 - 这正是 PDF 阅读器必须擅长的。PDF 中的绘图命令是 Postscript 的一个子集,它们与 Canvas 提供的功能并没有太大区别。此外,安全性几乎不是问题:使用 PDF.js 与打开任何其他网站一样安全。
参与 PDF.js 的开发
因此,Christian Krebs、Mathieu Henri 和我开始更详细地研究 PDF.js,并对此印象深刻:它设计良好,看起来很快,并且代码的大部分令人惊叹!
但我们也发现了一些问题,主要是非常大或图形密集型 PDF 的性能问题。我们认为,了解 PDF.js 的最佳方法,以及推动该项目进一步发展的方法,就是帮助该项目并解决我们发现的主要问题。这让我们对该项目及其巨大潜力有了相当好的了解。我们也对我们在开发过程中 PDF.js 的性能提升印象深刻。这是一个活跃且管理良好的项目。
对 PDF.js 进行基准测试
当然,我们的测试让我们对性能产生了错误的印象。我们试图找到超大、奇怪和难以渲染的 PDF,但这并不是大多数人想要查看的内容。您实际上想要在 PDF.js 中查看的大多数 PDF 都很好。但如何测试呢?
好吧,您可以查看互联网上最受欢迎的 PDF - 因为这些 PDF 可能是您想要查看的 - 并对它们进行基准测试。5 到 10k 个 PDF 的快照应该足够了……但如何获取它们呢?
我认为搜索引擎将是我的朋友。如果您告诉它们只搜索 PDF,它们会为您提供与该关键字最相关的 PDF,这些 PDF 也可能是最受欢迎的 PDF。如果您使用搜索次数最多的关键字,您最终会得到一个很好的近似值。
对如此多的 PDF 进行基准测试是一项大任务。所以我给自己弄了一小群旧电脑,并构建了一个不错的服务器应用程序,为它们提供任务。当前存储库中有近 7000 个 PDF,对一个版本的 PDF.js 进行基准测试大约需要 8 个小时。
结果
让我们直接跳到有趣的部分,也就是漂亮的图片。此图表
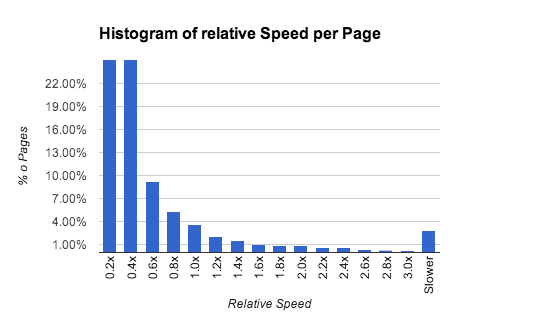
让我们一目了然地了解几乎所有有趣的结果。您会看到一个直方图,它显示了处理 PDF 中所有页面所需的时间与处理 Tracemonkey Paper(打开 PDF.js 时看到的默认 PDF)的平均页面所需时间的平均时间之间的关系。查看 Tracemonkey Paper 时的用户体验很好,根据我的测试,即使慢 3 到 4 倍仍然可以接受。这意味着从所有基准测试页面中,超过 96%(不包括崩溃的 PDF)将转化为良好的用户体验。这是一个非常好的消息!或者使用一个非常简单的饼图(以页面百分比表示)

您可能已经注意到一个小小的陷阱:在测试过程中,大约 0.8% 的 PDF 使 PDF.js 崩溃。我们仔细查看了其中大部分 PDF,至少三分之一实际上严重损坏,可能任何 PDF 阅读器都无法显示它们。
这让我们想到了另一个要点:我们必须记住,这些结果只是独立存在,没有比较。互联网上有一些 PDF 非常复杂,即使是原生 PDF 阅读器也不可能快速完美地显示它们。测试中最慢的 PDF 是里斯本公共交通系统的一张极其详细的矢量地图。尝试在 Adobe Reader 中打开它,那可不有趣!
结论
从这些结果中,我们得出结论,PDF.js 是一个非常有效的候选者,可以作为 Opera 浏览器的默认 PDF 阅读器。要将 PDF.js 很好地集成到其中,仍然需要做很多工作,但我们现在正在努力将其集成到实验性标志后面(顺便说一下:有一个 扩展程序 可以使用默认的 Mozilla 阅读器添加 PDF.js。我所说的“良好”集成将更深入,包括一个全新的阅读器)。感谢 Mozilla!我们期待与你们一起在 PDF.js 上合作!
附注:计算系统代码 和 结果 均公开可用。请查看并告诉我们您是否发现它们有用!
附注:如果有人在大型搜索引擎公司工作,并且可以给我一个包含实际使用最广泛的 10k 个 PDF 的列表,那就太棒了 :)
附录:接下来是什么?
我描述的语料库和计算框架可以用于做各种有趣的事情。在下一步中,我们希望通过使用的字体格式、图像格式等对 PDF 进行分类。这样,您就可以快速获得 PDF 来测试新功能。我们还想研究在 Postscript 中使用哪些绘图指令以及它们的频率,以便我们可以更好地优化非常常见的指令,就像我们在浏览器中对 HTML 所做的那样。让我们看看我们究竟能做些什么;)
关于 Thorben Bochenek
挪威奥斯陆 Opera Software 的 JavaScript 工程师。Thorben 在一家以 Java 为核心的公司实习并成为唯一的 JS 开发人员时,学会了喜欢 JavaScript 的精简本质。他在苏黎世联邦理工学院学习计算机科学,喜欢旅行,并且只在被要求时才写博客文章。
关于 Robert Nyman [荣誉编辑]
Mozilla Hacks 的技术布道者和编辑。发表演讲和撰写关于 HTML5、JavaScript 和开放网络的博客文章。Robert 是 HTML5 和开放网络的坚定支持者,自 1999 年以来一直在从事网络前端开发工作 - 在瑞典和纽约市。他还在 http://robertnyman.com 上定期撰写博客文章,喜欢旅行和结识新朋友。
37 条评论