
你是否曾经尝试在手机上输入优惠券代码,或者只是将会员卡号输入到网页表单中?
这只是两个例子,通过利用印刷条形码可以避免这些费时且容易出错的任务。这没什么新鲜的;许多解决方案可以通过普通摄像头读取条形码,例如 zxing,但它们需要 Android 或 iOS 等原生平台。我想要一个在网页上工作的解决方案,没有任何插件,并且 Firefox OS 也可以利用。
我对计算机视觉和网页技术的普遍兴趣激发了我对这样一种解决方案是否可行的好奇心。不仅仅是一个简单的扫描仪,而是一个配备了定位机制以实时查找条形码的扫描仪。
结果是一个名为 QuaggaJS 的项目,该项目托管在 GitHub 上。查看 演示页面,了解这个项目的全部内容。

它是如何工作的?
简单来说,流水线可以分为以下三个步骤:
第一步需要源代码是网络摄像头流或图像文件,然后将其转换为灰度并存储在 1D 数组中。之后,图像数据将传递给 **定位器**,它负责在图像中查找类似条形码的图案。最后,如果找到图案,**解码器** 尝试读取条形码并返回结果。您可以在 QuaggaJS 中的条形码定位工作原理 中详细了解这些步骤。
实时挑战
主要挑战之一是让流水线加速并足够快,以被视为实时应用程序。在谈论图像处理应用程序中的实时时,我认为每秒 25 帧 (FPS) 是下限。这意味着整个流水线必须在至少 40 毫秒内完成。
QuaggaJS 的核心部分由计算机视觉算法组成,这些算法往往对数组访问很重。正如我之前提到的,输入图像存储在 1D 数组中。这不是一个普通的 JavaScript 数组,而是一个 类型化数组。由于图像已经在第一步中转换为灰度,因此每个像素值的范围都设置为 0 到 255 之间。这就是为什么所有与图像相关的缓冲区都使用 Uint8Array。
内存效率
实现交互式应用程序实时速度的关键方法之一是创建内存效率高的代码,避免大的 GC(垃圾回收)暂停。这就是我通过简单地重复使用最初创建的缓冲区来删除大多数内存分配调用的原因。但是,这仅在您提前知道缓冲区的大小且大小不会随着时间的推移而改变时才有用,例如图像。
分析
如果您好奇为什么应用程序的某个特定部分运行得太慢,CPU 分析可能会有所帮助。
Firefox 包含一些很棒的工具,用于为正在运行的 JavaScript 代码创建 CPU 分析。在开发过程中,这被证明对于查明性能瓶颈和查找导致 CPU 负载最大的函数是可行的。以下分析是在 Intel Core i7-4600U 上使用网络摄像头进行的会话期间记录的。(配置:视频 640×480,半采样条形码定位)
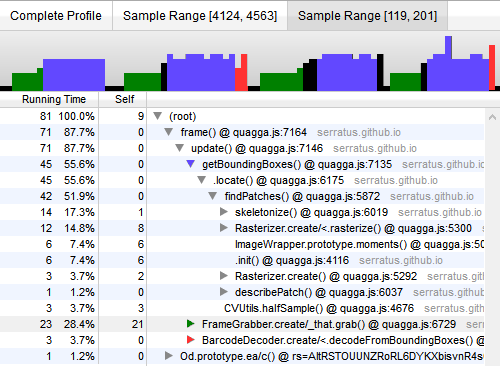
分析已放大,显示了四个后续帧。平均而言,流水线中的一帧在大约 20 毫秒内处理。即使在运行具有较弱 CPU 的机器(如手机和平板电脑)上,这也足够快。
我用不同的颜色标记了流水线的每个步骤;绿色是第一个,蓝色是第二个,红色是第三个。深入分析显示,定位步骤消耗了大部分时间 (55.6%),其次是读取输入流 (28.4%),最后是解码 (3.7%)。还值得注意的是,skeletonize 是 CPU 使用率方面最昂贵的函数之一。因此,我手动在 asm.js 中重新实现了整个骨架化算法,以查看它是否可以更快地运行。
asm.js
Asm.js 是 JavaScript 的一个高度可优化的子集,可以以接近本机速度执行。它承诺在用于计算密集型任务(看看 MASSIVE)时会带来很多性能提升,就像大多数计算机视觉算法一样。这就是我将整个 skeletonizer 模块移植到 asm.js 的原因。这是一项非常繁琐的任务,因为实际上您不应该手动编写 asm.js 代码。通常,asm.js 代码是在使用 emscripten 从 C/C++ 或其他 LLVM 语言交叉编译时生成的。但我还是做了,只是为了证明这一点。
首先需要解决的问题是如何将图像数据以及图像大小等参数一起输入到 asm.js 模块中。该模块旨在完全适合现有的实现,因此包含了一些约束,例如方形图像大小。但是,skeletonizer 仅应用于原始图像的块,这些块在定义上都是正方形的。不仅输入数据很重要,而且在处理过程中还需要三个临时缓冲区(腐蚀、temp、骨架)。
为了解决这个问题,创建了一个初始缓冲区,该缓冲区足够大,可以同时容纳所有四个图像。缓冲区在调用者和模块之间共享。由于我们正在使用单个缓冲区,因此我们需要保留对每个图像位置的引用。这就像在 C 中使用指针玩游戏。
function skeletonize() {
var subImagePtr = 0,
erodedImagePtr = 0,
tempImagePtr = 0,
skelImagePtr = 0;
erodedImagePtr = imul(size, size) | 0;
tempImagePtr = (erodedImagePtr + erodedImagePtr) | 0;
skelImagePtr = (tempImagePtr + erodedImagePtr) | 0;
// ...
}
为了更好地理解缓冲区结构背后的想法,请将其与以下插图进行比较:

绿色缓冲区表示分配的内存,该内存是在创建时传递到 asm.js 模块中的。然后将该缓冲区划分为四个蓝色块,每个块包含相应图像的数据。为了获得对正确数据块的引用,变量(以 Ptr 结尾)指向该确切的位置。
现在我们已经设置了缓冲区,是时候看看 erode 函数了,该函数是使用普通 JavaScript 编写的 skeletonizer 的一部分:
function erode(inImageWrapper, outImageWrapper) {
var v,
u,
inImageData = inImageWrapper.data,
outImageData = outImageWrapper.data,
height = inImageWrapper.size.y,
width = inImageWrapper.size.x,
sum,
yStart1,
yStart2,
xStart1,
xStart2;
for ( v = 1; v < height - 1; v++) {
for ( u = 1; u < width - 1; u++) {
yStart1 = v - 1;
yStart2 = v + 1;
xStart1 = u - 1;
xStart2 = u + 1;
sum = inImageData[yStart1 * width + xStart1] +
inImageData[yStart1 * width + xStart2] +
inImageData[v * width + u] +
inImageData[yStart2 * width + xStart1] +
inImageData[yStart2 * width + xStart2];
outImageData[v * width + u] = sum === 5 ? 1 : 0;
}
}
}
然后修改了此代码以符合 asm.js 规范。
"use asm";
// initially creating a view on the buffer (passed in)
var images = new stdlib.Uint8Array(buffer),
size = foreign.size | 0;
function erode(inImagePtr, outImagePtr) {
inImagePtr = inImagePtr | 0;
outImagePtr = outImagePtr | 0;
var v = 0,
u = 0,
sum = 0,
yStart1 = 0,
yStart2 = 0,
xStart1 = 0,
xStart2 = 0,
offset = 0;
for ( v = 1; (v | 0) < ((size - 1) | 0); v = (v + 1) | 0) {
offset = (offset + size) | 0;
for ( u = 1; (u | 0) < ((size - 1) | 0); u = (u + 1) | 0) {
yStart1 = (offset - size) | 0;
yStart2 = (offset + size) | 0;
xStart1 = (u - 1) | 0;
xStart2 = (u + 1) | 0;
sum = ((images[(inImagePtr + yStart1 + xStart1) | 0] | 0) +
(images[(inImagePtr + yStart1 + xStart2) | 0] | 0) +
(images[(inImagePtr + offset + u) | 0] | 0) +
(images[(inImagePtr + yStart2 + xStart1) | 0] | 0) +
(images[(inImagePtr + yStart2 + xStart2) | 0] | 0)) | 0;
if ((sum | 0) == (5 | 0)) {
images[(outImagePtr + offset + u) | 0] = 1;
} else {
images[(outImagePtr + offset + u) | 0] = 0;
}
}
}
return;
}
虽然基本代码结构没有发生重大变化,但魔鬼在于细节。不是传递到 JavaScript 对象的引用,而是使用输入和输出图像的相应索引,指向缓冲区。另一个显着的区别是使用 | 0 表示将值重复转换为整数,这对于安全的数组访问是必要的。还定义了一个额外的变量 offset,用作计数器来跟踪缓冲区中的绝对位置。这种方法取代了用于确定当前位置的乘法。一般来说,asm.js 不允许整数相乘,除非使用 imul 运算符。
最后,asm.js 中禁止使用三元运算符 ( ? : ),它只是被一个普通的 if.. else 条件替换了。
性能比较
现在是时候回答更重要的问题了:与普通的 JavaScript 相比,asm.js 实现快了多少?让我们看一下性能分析,第一个代表普通的 JavaScript 版本,第二个代表 asm.js。
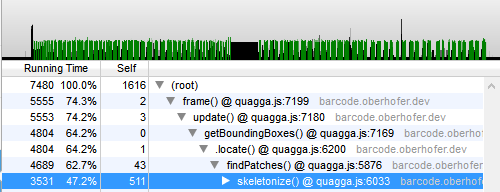
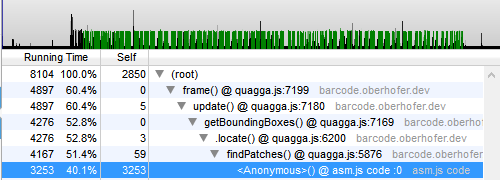
令人惊讶的是,两种实现之间的差异并不像你想象的那么大 (~10%)。显然,最初的 JavaScript 代码已经写得足够干净,因此 JIT 编译器已经可以充分利用它。如果有人使用 emscripten 在 C/C++ 中重新实现算法并将其交叉编译到 asm.js,则只能证明此假设是错误的还是正确的。我几乎可以肯定,结果将不同于我的简单移植,并且会生成更优化的代码。
getUserMedia
除了性能之外,还有许多其他部分必须配合才能获得最佳体验。其中一部分是通往用户世界的门户,即摄像头。众所周知,getUserMedia 提供了一个 API 来访问设备的摄像头。这里,难点在于所有主要浏览器厂商之间的差异,它们对约束、分辨率和事件的处理方式不同。
前后摄像头
如果您针对的是除普通笔记本电脑或计算机以外的设备,那么这些设备很可能提供不止一个摄像头。如今,几乎所有平板电脑或智能手机都具有后置摄像头和前置摄像头。使用 Firefox 时,无法以编程方式选择摄像头。每次用户确认访问摄像头时,都必须选择所需摄像头。这在 Chrome 中的处理方式有所不同,MediaStreamTrack.getSources 会公开可用的源,然后可以对其进行过滤。您可以在 W3C 草案 中找到定义的源。
以下代码片段演示了如何优先访问用户的后置摄像头:
MediaStreamTrack.getSources(function(sourceInfos) {
var envSource = sourceInfos.filter(function(sourceInfo) {
return sourceInfo.kind == "video"
&& sourceInfo.facing == "environment";
}).reduce(function(a, source) {
return source;
}, null);
var constraints = {
audio : false,
video : {
optional : [{
sourceId : envSource ? envSource.id : null
}]
}
};
});
在条形码扫描的用例中,用户最有可能使用设备的后置摄像头。这时,提前选择摄像头可以极大地改善用户体验。
分辨率
使用视频时另一个非常重要的主题是视频流的实际分辨率。这可以通过对视频流添加额外的约束来控制。
var hdConstraint = {
video: {
mandatory: {
width: { min: 1280 },
height: { min: 720 }
}
}
};
上述代码片段在添加到视频约束时,会尝试获取具有指定质量的视频流。如果没有任何摄像头满足这些要求,则在回调中返回 ConstraintNotSatisfiedError 错误。但是,这些约束并非与所有浏览器完全兼容,因为有些浏览器使用 minWidth 和 minHeight 来代替。
自动对焦
条形码通常很小,必须靠近摄像头才能被正确识别。内置自动对焦可以帮助提高检测算法的鲁棒性。但是,getUserMedia API 缺乏触发自动对焦的功能,大多数设备在浏览器模式下甚至不支持连续自动对焦。如果您拥有最新的 Android 设备,Firefox 很可能能够使用您摄像头的自动对焦功能(例如 Nexus 5 或 HTC One)。Android 上的 Chrome 尚未支持此功能,但已经有一个 问题 报告。
性能
还有一个问题是,从视频流中获取帧会对性能造成影响。结果已经在 **性能分析** 部分进行了展示。结果表明,仅仅为了获取图像并将其存储在 TypedArray 实例中,就消耗了大约 30% 的 CPU 时间,即 8 毫秒。从视频源读取数据的典型过程如下:
- 确保摄像头流已附加到视频元素
- 使用
ctx.drawImage将图像绘制到画布上 - 使用
ctx.getImageData从画布中读取数据 - 将视频转换为灰度并存储在
TypedArray中
var video = document.getElementById("camera"),
ctx = document.getElementById("canvas").getContext("2d"),
ctxData,
width = video.videoWidth,
height = video.videoHeight
data = new Uint8Array(width*height);
ctx.drawImage(video, 0, 0);
ctxData = ctx.getImageData(0, 0, width, height).data;
computeGray(ctxData, data);
如果有一种方法可以更低级别地访问摄像头帧,而无需经过绘制和读取每个图像的麻烦,将非常感谢。这在处理更高分辨率内容时尤为重要。
总结
创建一个以计算机视觉为中心的项目非常有趣,尤其是因为它将 Web 平台的许多部分联系在一起。希望移动设备上缺少自动对焦功能或读取摄像头流等限制将在不久的将来得到解决。尽管如此,现在仅使用 HTML 和 JavaScript 就能构建如此强大的功能,这仍然令人惊叹。
另一个经验教训是,如果您已经知道如何编写合适的 JavaScript 代码,那么手动实现 asm.js 既困难又没有必要。但是,如果您已经拥有现有的 C/C++ 代码库,并且想要移植它,那么 emscripten 做得非常出色。这就是 asm.js 的用武之地。
最后,我希望越来越多的人加入计算机视觉的行列,即使像 WebCL 这样的技术还处于起步阶段。Firefox 的未来甚至可能是将 ARB_compute_shader 纳入快速发展轨道。
关于 Christoph Oberhofer
我是一名应用开发人员,专注于 Web 技术和移动解决方案,在 @Netconomy 工作。任何 JavaScript、Java 或 CSS 代码都会让我兴奋。我的 Twitter 账号是 @overaldi。
7 条评论