
背景:SIMD.js
单指令多数据(SIMD)是一种在现代处理器中使用的技术,用于利用数据级并行性。 SIMD 引入了可以容纳多个数据元素的宽向量。 加载完成后,可以使用一个向量操作同时处理向量的所有元素。 这带来了更好的性能和能效的优势。 SIMD 提供的并行性可用于各种应用,包括科学计算、信号处理和 3D 图形。 随着 Web 演变成能够支持这些应用程序的平台,SIMD 成为一个非常理想的功能。
SIMD.js 是一个 JavaScript API,它将 Web 应用程序暴露给处理器中发现的 SIMD 功能。 它由 Google、英特尔、Mozilla 和微软共同开发。 介绍 SIMD.js 是一篇不错的文章,可以了解更多信息。
glMatrix 向量化
向量化是准备程序使用 SIMD 向量操作的过程。 矩阵计算是一种可以利用向量化的应用类型。 矩阵数学 在 JavaScript 中被广泛用于支持 WebGL 应用程序和高性能应用程序,如物理模拟和图像处理。 gl-matrix 是一个用于 JavaScript 的快速矩阵和向量数学库。 它提供了许多用于处理方阵和向量的函数。
在我们 Mozilla Research 的工作中,我们通过向量化操作四乘四矩阵的 mat4 函数,为 gl-matrix 做出了贡献。 Mat4 函数是向量化的正确选择,因为它们是最计算密集型的函数之一,并且在 3D 图形应用程序中被大量使用,在这些应用程序中,计算必须在每帧重复执行。 此外,对于大多数函数,我们能够充分利用 SIMD 向量并实现良好的加速。 到目前为止,我们已经使用 SIMD.js API 向量化了几个 mat4 函数:旋转、缩放、平移、乘法、平移、伴随矩阵和逆矩阵。
gl-matrix 函数期望将向量/矩阵参数存储在 JavaScript 类型化数组中。 SIMD.js API 包含用于从类型化数组加载和存储向量的函数。 这意味着我们能够对函数的向量化版本使用相同的函数签名。 我们将原始标量实现和向量化实现打包到两个类中:mat4.scalar 和 mat4.SIMD。 以下是 mat4.multiply 函数的标量和 SIMD 版本的签名
//Scalar implementation
mat4.scalar.multiply = function (out, a, b) { /* Scalar implementation*/}
//Vectorized implementation
mat4.SIMD.multiply = function (out, a, b) { /* SIMD implementation*/}
gl-matrix 检查浏览器是否支持 SIMD.js,并相应地设置 `glMatrix.SIMD_AVAIALABLE` 标志。 如果 SIMD.js 可用,可以通过将 `glMatrix.ENABLE_SIMD` 标志设置为 true 来选择 SIMD 实现。 以下代码片段展示了如何选择不同版本的 multiply 函数
glMatrix.USE_SIMD = glMatrix.ENABLE_SIMD && glMatrix.SIMD_AVAILABLE;//Select the SIMD implementation if SIMD is supported and enabled
mat4.multiply = glMatrix.USE_SIMD ? mat4.SIMD.multiply : mat4.scalar.multiply;
选择向量化友好的算法对于向量化至关重要。 例如,有各种方法可以计算 4×4 矩阵的逆矩阵,但最佳结果可以通过基于方法的克莱姆法则来实现。 此外,为了获得理论加速,应仔细选择 SIMD 指令,因为某些指令按顺序执行并且具有更长的延迟。 我们在这里没有应用循环展开,但这是一个值得考虑的技巧,可以暴露并发性并实现更高的加速。
实验结果
SIMD.js 已经标准化了一段时间,但直到最近,它的 API 才发展到第 3 阶段,在那里它将被视为稳定。 尽管目前正在进行的工作是在包括 Chromium 和 Microsoft Edge 在内的主要浏览器中支持 SIMD.js,但目前它仅在适用于 x64 和 x86 处理器系列的 Firefox Nightly 版本中可用。
我开发了一个小的基准测试,以评估使用 SIMD.js 的向量化 gl-matrix 的性能。 它测量了具有随机输入矩阵的 mat4 函数的标量和向量化实现的平均执行时间,迭代次数很多。
在我们深入研究结果之前,让我们先了解一下SpiderMonkey 引擎 如何执行 SIMD.js 程序。 在开始时,JavaScript 函数从解释器开始执行。 在此阶段,SIMD 对象存储在顺序数组中,对它们的所有操作都按顺序执行。 因此,在此阶段没有性能提升。 为了从 SIMD 中获益,JavaScript 程序需要编译成利用 SIMD 指令的优化机器代码。 但由于编译是一个耗时的过程,因此只有在花费大量时间执行函数时,才能注意到好处。
SIMD.js 应该是在 Intel SSE2 和 ARM NEON 中可用的 SIMD 内在函数的通用子集。 SIMD.js 中的向量具有 128 位的固定宽度,这可以用于存储四个整数、四个单精度浮点数或两个双精度浮点数。 由于 gl-matrix 使用单精度浮点数表示数字,因此向量最多可以容纳四个数据元素。 因此,并行性受四个限制。
我们在 X86-64 机器上使用Firefox Nightly 44 启动 gl-matrix 基准测试。 图 1 显示了基准测试报告的向量化加速。 Y 轴表示与标量版本相比,向量化实现的加速。 红色条形图表示与仅使用标量指令的汇编代码相比,使用 SIMD 指令的汇编代码的加速。 两种版本都是由IonMonkey JIT 编译器生成的。 它们揭示了我们对于每个函数可以从 SIMD.js 实现中期望获得的最大加速。
加速的程度取决于每个算法的理论并行化限制,以及包括编译器优化和底层硬件在内的实现细节。 但是,如前所述,生成优化的机器代码很昂贵,并且只有在花费足够的时间执行函数后才会发生。 蓝色条形图反映了这一事实。 蓝色条形图表示当函数被调用 500 万次时,向量化实现与标量实现相比的加速。 这些包括 JavaScript 执行的所有阶段,包括解释器模式和 JIT 编译。 增加迭代次数会导致在执行已编译代码上花费更多时间,从而更接近最大加速。
我们的测量结果表明,对于乘法和转置函数(大约 3 倍加速),以及其他六个函数(伴随矩阵、逆矩阵、绕轴旋转和缩放)具有显着的性能提升。 平移函数中可用的并行性有限,导致加速相对较低。
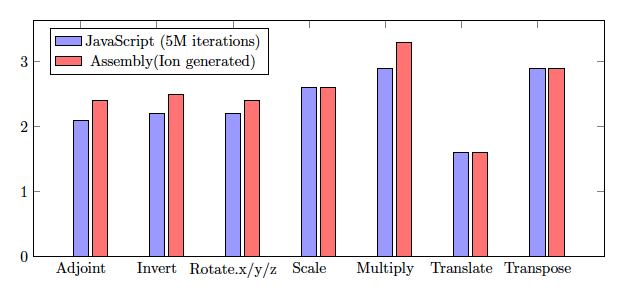
图 1. 使用 SIMD.js 的 gl-matrix Mat4 加速(越高越好)
结论
总之,SIMD.js 可以为高性能计算和多媒体领域的许多 JavaScript 程序带来重大加速。 我们评估了 SIMD.js 与 gl-matrix 的性能,并观察到性能有了显著提升。 我们对 SIMD.js 的潜力感到非常兴奋,并期待着 SIMD.js 在开放 Web 平台上的其他成功部署。
关于 Sajjad Taheri
加州大学欧文分校计算机科学博士生,前 Mozilla 实习生。
2 条评论