
作者注: 自本文发表以来,postMessage 的 API 已略有变化。 使用 postMessage 发送 SharedArrayBuffer 时,该缓冲区不再应出现在 postMessage 调用的传输列表参数中。 因此,如果 sab 是一个 SharedArrayBuffer 对象,w 是一个工作线程,则 w.postMessage(sab) 会将该缓冲区发送到工作线程。
您可以在 MDN 的 SharedArrayBuffer 文档 中找到更多详细信息。
简而言之 - 我们正在使用一个原语 API 扩展 JavaScript,它允许程序员使用 **多个工作线程** 和 **共享内存** 来实现 **JavaScript 中真正的并行算法**。
多核计算
JavaScript (JS) 已经成长起来,并且运行良好,以至于几乎所有现代网页都包含大量的 JS 代码,我们从不用担心 - 它只是自动运行。 JS 也被用于更具挑战性的任务:客户端图像处理(在 Facebook 和 Lightroom 中)是用 JS 编写的;像 Google Docs 这样的浏览器内办公套件是用 JS 编写的;以及 Firefox 的一些组件,例如内置的 PDF 查看器 pdf.js 和语言分类器,是用 JS 编写的。 事实上,这些应用程序中的一些采用的是 asm.js 的形式,asm.js 是一个简单的 JS 子集,是 C++ 编译器的常用目标语言;最初用 C++ 编写的游戏引擎正在被重新编译成 JS,以便作为 asm.js 程序在 Web 上运行。
JS 在这些任务以及许多其他任务中的常规使用,得益于 JS 引擎中使用即时 (JIT) 编译器带来的显著性能提升,以及不断更快的 CPU。
但是,JS JIT 的改进速度现在正在放缓,CPU 性能的提升也基本停滞不前。 除了更快的 CPU,所有消费类设备 - 从台式机系统到智能手机 - 现在都配备了多个 CPU(实际上是 CPU 内核),而且除了低端设备,它们通常拥有超过两个内核。 如果一位程序员想要提高其程序的性能,就必须开始并行使用多个内核。 对于使用多线程编程语言(Java、Swift、C# 和 C++)编写的“原生”应用程序来说,这不是问题,但对于 JS 来说,这是一个问题,因为 JS 在多个 CPU 上运行的能力非常有限(Web 工作线程、缓慢的消息传递以及很少的避免数据复制的方法)。
因此,JS 面临着一个问题:如果我们希望 Web 上的 JS 应用程序继续成为每个平台上原生应用程序的可行替代方案,我们必须赋予 JS 在多个 CPU 上良好运行的能力。
构建模块:共享内存、原子操作和 Web 工作线程
在过去的一年左右的时间里,Mozilla 的 JS 团队一直在领导一项标准化倡议,为 JS 添加多核计算的构建模块。 其他浏览器供应商一直在与我们合作进行这项工作,我们的 提案 正在经历 JS 标准化流程 的各个阶段。 我们在 Mozilla JS 引擎中的原型实现有助于设计,并在 Firefox 的某些版本中可用,如下所述。
本着 可扩展 Web 的精神,我们选择通过公开尽可能少限制程序的低级构建模块来促进多核计算。 这些构建模块是一个新的共享内存类型、对共享内存对象的原子操作,以及一种将共享内存对象分发到标准 Web 工作线程的方式。 这些想法并不新鲜;有关高级背景和一些历史,请参阅 Dave Herman 的博客文章。
新的共享内存类型称为 SharedArrayBuffer,它与现有的 ArrayBuffer 类型非常相似;主要区别在于,由 SharedArrayBuffer 表示的内存可以同时被多个代理引用。(代理可以是网页的主程序或其 Web 工作线程之一。)共享是通过使用 postMessage 将 SharedArrayBuffer 从一个代理传输到另一个代理来创建的。
let sab = new SharedArrayBuffer(1024)
let w = new Worker("...")
w.postMessage(sab, [sab]) // Transfer the buffer
工作线程在消息中接收 SharedArrayBuffer
let mem;
onmessage = function (ev) { mem = ev.data; }
这将导致以下情况:主程序和工作线程都引用同一内存,而该内存不属于它们中的任何一个
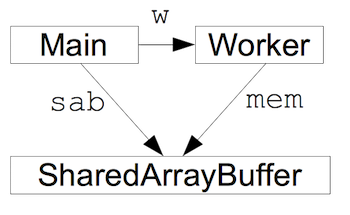
共享 SharedArrayBuffer 后,每个共享该缓冲区的代理都可以通过在缓冲区上创建 TypedArray 视图并在视图上使用标准数组访问操作来读取和写入其内存。 假设工作线程执行以下操作
let ia = new Int32Array(mem);
ia[0] = 37;
然后,主程序可以读取工作线程写入的单元格,如果它等到工作线程写入完成之后,它将看到值“37”。
对于主程序而言,“等到工作线程写入数据之后”实际上很棘手。 如果多个代理在不协调访问的情况下读取和写入同一位置,那么结果将是垃圾数据。 新的原子操作保证程序操作按可预测的顺序且不中断地执行,从而使这种协调成为可能。 原子操作作为新顶级 Atomics 对象上的静态方法存在。
速度和响应能力
我们可以通过 Web 上的多核计算来解决的两个性能方面是速度,即每单位时间可以完成多少工作,以及响应能力,即用户在浏览器进行计算时与浏览器交互的程度。
我们通过将工作分发到多个工作线程来提高速度,这些工作线程可以并行运行:如果我们可以将计算分成四部分,并在四个工作线程上运行,每个工作线程都获得一个专用的内核,那么我们有时可以将计算速度提高四倍。 我们通过将工作从主程序移到工作线程来提高响应能力,这样一来,即使计算正在进行,主程序也能对 UI 事件做出响应。
共享内存被证明是一个重要的构建模块,原因有两个。 首先,它消除了数据复制的成本。 例如,如果我们在许多工作线程上渲染场景,但必须从主程序显示场景,那么渲染的场景必须复制到主程序,这会增加渲染时间并降低主程序的响应能力。 其次,共享内存使代理之间的协调变得非常便宜,比 postMessage 便宜得多,这会减少代理在等待通信时处于空闲状态的时间。
没有免费的午餐
利用多个 CPU 内核并不总是容易。 为单个内核编写的程序通常需要进行大幅度的重构,而且通常很难确定重构后的程序的正确性。 如果工作线程需要频繁地协调其操作,则从多个内核获得加速也可能很困难。 并非所有程序都会从并行处理中获益。
此外,并行程序中存在全新的错误类型。 如果两个工作线程最终错误地相互等待,那么程序将不再继续执行:程序死锁。 如果工作线程在不协调访问的情况下读取和写入同一内存单元格,则结果有时(以及不可预测地、静默地)是垃圾数据:程序存在数据竞争。 存在数据竞争的程序几乎总是错误的且不可靠的。
示例
注意:要运行本文中的演示,您需要 Firefox 46 或更高版本。 您还必须在 about:config 中将首选项 javascript.options.shared_memory 设置为 true,除非您正在运行 Firefox Nightly。
让我们看一下如何将程序并行化到多个内核,以获得良好的加速。 我们将研究一个简单的 Mandelbrot 集动画,该动画将像素值计算到网格中,并在画布中显示该网格,以不断增加的缩放级别。(Mandelbrot 计算被称为“令人尴尬的并行”:获得加速非常容易。 事物通常并不像这样简单。)我们在这里不会进行技术深 dive;请参阅结尾处的指针,了解更深入的内容。
共享内存功能在 Firefox 中默认不启用,原因是它仍在 JS 标准化机构中进行考虑。 标准化过程必须按其流程进行,并且该功能可能在过程中发生变化;我们不希望 Web 上的代码依赖于该 API。
串行 Mandelbrot
让我们首先简要看一下没有并行性的 Mandelbrot 程序:计算是文档的主程序的一部分,并直接渲染到画布中。(当您运行下面的演示时,您可以提前停止它,但后面的帧渲染速度较慢,因此只有在您让它运行到结束时,您才能获得可靠的帧速率。)
如果您好奇,以下是源代码
并行 Mandelbrot
Mandelbrot 程序的并行版本将使用多个工作线程并行地将像素计算到共享内存网格中。 从原始程序进行的改编在概念上很简单:mandelbrot 函数被移到 Web 工作线程程序中,并且我们运行多个 Web 工作线程,每个工作线程都计算输出的水平条带。 主程序仍然负责在画布中显示网格。
我们可以将此程序的帧速率(每秒帧数,FPS)绘制在使用的核心数量上,得到下面的图。 用于测量的计算机是 2013 年末的 MacBook Pro,具有四个超线程核心; 我使用 Firefox 46.0 进行了测试。

当我们从一个核心到四个核心时,程序速度几乎呈线性增长,从 6.9 FPS 增长到 25.4 FPS。 之后,随着程序开始在已在使用的核心上的超线程而不是新核心上运行,增量变得更加适度。(同一核心上的超线程共享核心上的部分资源,并且这些资源会存在一定程度的争用。) 但即使如此,程序也为我们添加的每个超线程加速了 3 到 4 FPS,并且在使用 8 个工作线程时,程序计算了 39.3 FPS,比在单个核心上运行的速度提高了 5.7 倍。
这种加速显然非常好。 然而,并行版本比串行版本复杂得多。 复杂性来自多个来源。
- 为了使并行版本正常工作,它需要_同步_工作线程和主程序:主程序必须告诉工作线程何时(以及做什么)计算,而工作线程必须告诉主程序何时显示结果。 数据可以使用 `postMessage` 双向传递,但通常(即更快)通过共享内存传递数据,而正确有效地做到这一点相当复杂。
- 良好的性能需要一种策略来将计算分配到工作线程之间,以通过_负载均衡_最大限度地利用工作线程。 在示例程序中,输出图像因此被划分为比工作线程多得多的条带。
- 最后,共享内存是一个整数值的扁平数组,由此产生了一些混乱; 共享内存中更复杂的数据结构必须手动管理。
考虑同步:新的 `Atomics` 对象有两个方法,`wait` 和 `wake`,它们可以用来在一个工作线程之间发送信号:一个工作线程通过调用 `Atomics.wait` 等待信号,另一个工作线程使用 `Atomics.wake` 发送该信号。 但是,这些是灵活的低级构建块; 要实现同步,程序还必须使用_原子操作_,如 `Atomics.load`、`Atomics.store` 和 `Atomics.compareExchange` 来读取和写入共享内存中的状态值。
更进一步地,网页的主线程不允许调用 `Atomics.wait`,因为主线程_阻塞_不好。 因此,虽然工作线程可以使用 `Atomics.wait` 和 `Atomics.wake` 互相通信,但主线程必须在等待时监听事件,而想要_唤醒_主线程的工作线程必须使用 `postMessage` 发布该事件。
(那些急于测试的人应该知道,在 Firefox 46 和 Firefox 47 中,`wait` 和 `wake` 被称为 `futexWait` 和 `futexWake`。 有关更多信息,请参阅 Atomics 的 MDN 页面。)
可以构建良好的库来隐藏大部分复杂性,如果一个程序(或者通常是程序的一个重要部分)在多个核心上运行时可以显著优于在一个核心上运行,那么复杂性真的值得。 但是,对程序进行并行化不是解决性能不佳的速效药。
在上述免责声明的基础上,以下是并行版本的代码
更多信息
有关可用 API 的参考材料,请阅读 拟议规范,该规范现在基本稳定。 该提案的 Github 存储库 也有一些可能对您有帮助的讨论文档。
此外,Mozilla 开发者网络 (MDN) 有关 SharedArrayBuffer 和 Atomics 的文档。
关于 Lars T Hansen
我是一名 Mozilla 的 JavaScript 编译器工程师。 之前我在 Adobe 负责 ActionScript3,在 Opera 负责 JavaScript 和其他浏览器相关工作。
26 条评论