
这是关于 WebAssembly 以及是什么让它如此快的一系列文章的第二部分。如果您还没有阅读其他部分,我们建议您从开始。
JavaScript 最初速度很慢,但后来由于一种叫做 JIT 的东西而变得更快。但 JIT 是如何工作的呢?
JavaScript 在浏览器中是如何运行的
当您作为开发人员将 JavaScript 添加到页面时,您会有一个目标和一个问题。
目标:您希望告诉计算机该怎么做。
问题:您和计算机使用不同的语言。
您使用人类语言,而计算机使用机器语言。即使您不认为 JavaScript 或其他高级编程语言是人类语言,它们实际上确实如此。它们是为人类认知而设计的,而不是为机器认知而设计的。
因此,JavaScript 引擎的工作就是将您的语言转换为机器可以理解的东西。
我认为这就像电影《降临》一样,人类和外星人试图互相交谈。

在电影中,人类和外星人不仅仅进行逐字翻译。这两个群体对世界的思考方式不同。人类和机器也是如此(我会在下一篇文章中进一步解释这一点)。
那么,翻译是如何发生的?
在编程中,通常有两种方法可以将语言转换为机器语言。您可以使用解释器或编译器。
使用解释器,这种转换几乎是逐行进行的,即时进行。

另一方面,编译器不会即时转换。它会提前工作以创建该转换并将其写下来。

这两种处理转换的方法都有优缺点。
解释器优缺点
解释器可以快速启动和运行。您不必先进行整个编译步骤,就可以开始运行代码。您只需开始转换第一行并运行它。
因此,解释器似乎很适合 JavaScript 这样的东西。对于 Web 开发人员来说,能够快速启动并运行代码非常重要。
这就是浏览器一开始使用 JavaScript 解释器的原因。
但使用解释器的缺点是在您多次运行同一代码时出现。例如,如果您在一个循环中。那么您必须一遍又一遍地进行相同的转换。
编译器优缺点
编译器具有相反的权衡。
它需要更多的时间才能启动,因为它必须在开始时进行编译步骤。但随后循环中的代码运行速度更快,因为它不需要为循环的每次迭代重复转换。
另一个区别是,编译器有更多时间查看代码并对其进行编辑,以便它能够更快地运行。这些编辑称为优化。
解释器在运行时执行其工作,因此它在转换阶段无法花费太多时间来找出这些优化。
即时编译器:两全其美
为了消除解释器效率低下的问题——解释器必须在每次通过循环时都重新转换代码——浏览器开始将编译器混合在一起。
不同的浏览器以略微不同的方式执行此操作,但基本思想是相同的。它们在 JavaScript 引擎中添加了一个新部分,称为监视器(也称为分析器)。该监视器在代码运行时监视代码,并记录代码运行的次数以及使用的类型。
最初,监视器只是通过解释器运行所有内容。
如果代码的相同行运行了几次,则该代码段称为“暖”代码。如果它运行了很多次,那么它被称为“热”代码。
基线编译器
当一个函数开始变暖时,JIT 会将其发送出去进行编译。然后它会存储该编译结果。
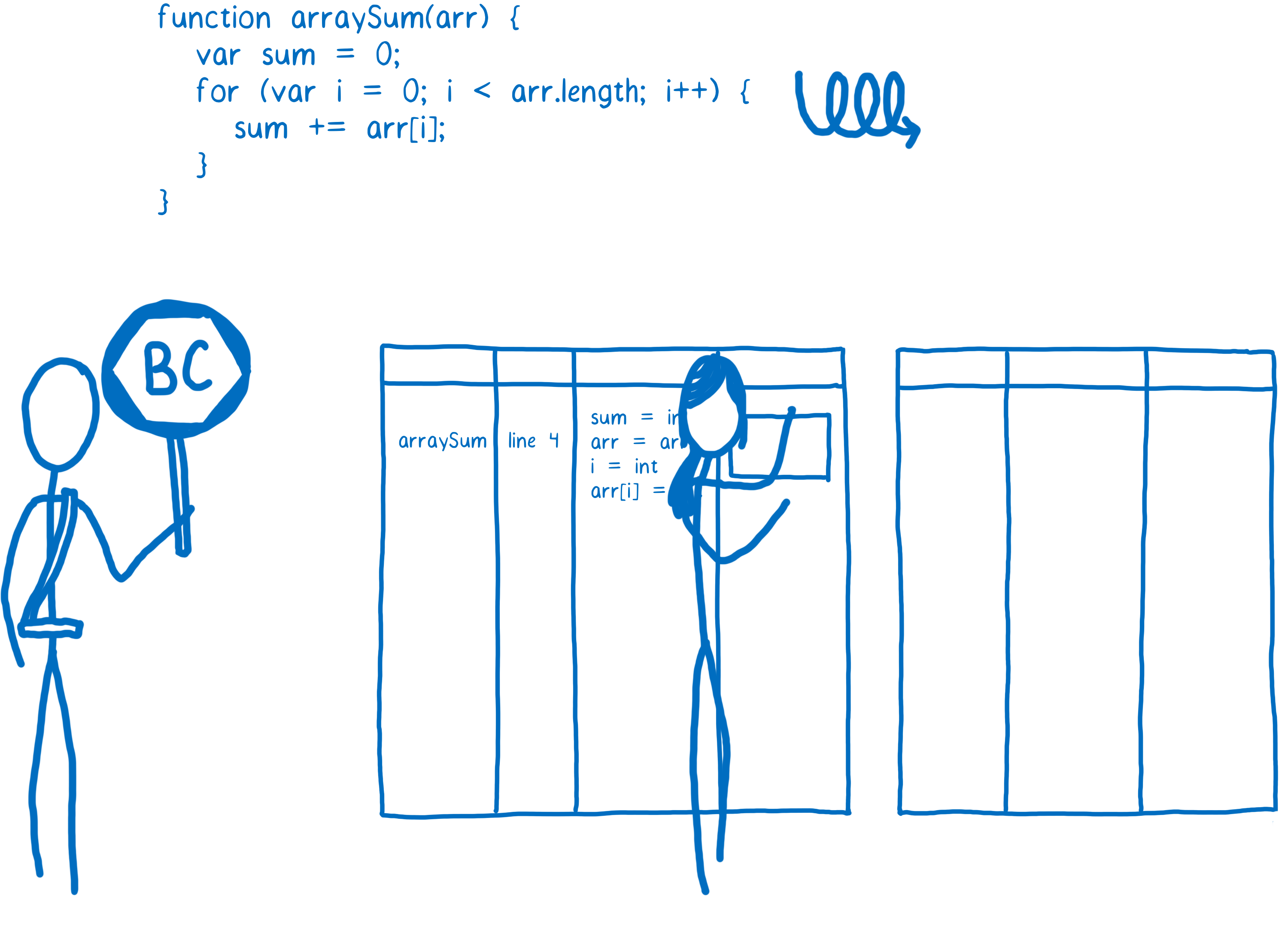
函数的每一行都会编译成一个“存根”。这些存根按行号和变量类型进行索引(稍后我会解释为什么这很重要)。如果监视器看到执行再次命中相同的代码以及相同的变量类型,它将只提取其已编译版本。
这有助于加快速度。但正如我所说,编译器还可以做更多事情。它可以花一些时间来找出最有效的方式来做事情……进行优化。
基线编译器将进行一些优化(我在下面提供了一个示例)。不过,它不想花费太多时间,因为它不想拖延执行时间太长。
但是,如果代码真的很热——如果它被运行了很多次——那么花额外的时间进行更多优化是值得的。
优化编译器
当代码的一部分非常热时,监视器会将其发送到优化编译器。这将创建另一个更快的函数版本,该版本也将被存储起来。
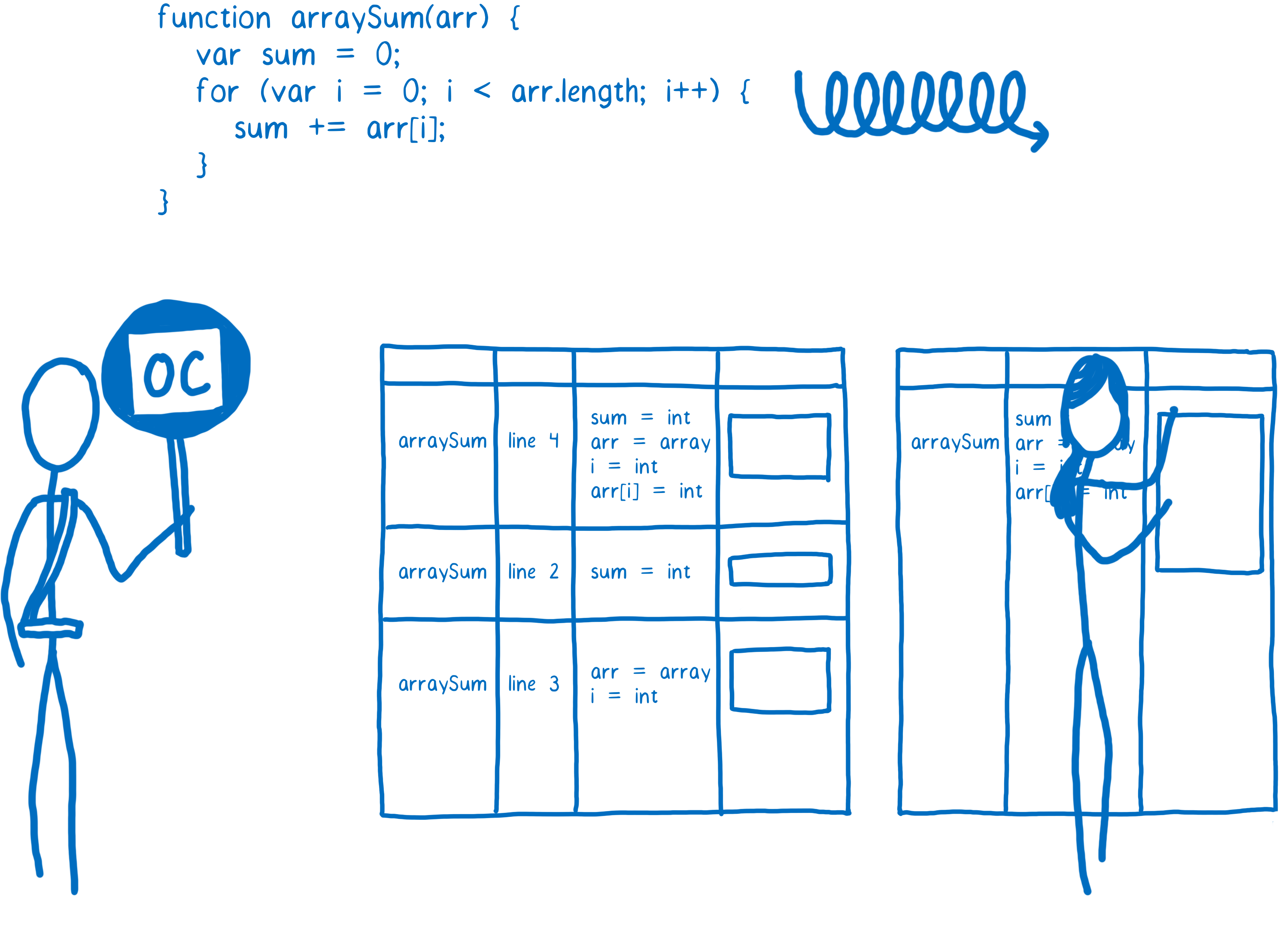
为了创建代码的更快版本,优化编译器必须做一些假设。
例如,如果它可以假设由特定构造函数创建的所有对象具有相同的形状——也就是说,它们始终具有相同的属性名称,并且这些属性按相同的顺序添加——那么它可以根据此假设做一些简化。
优化编译器使用监视器通过监视代码执行收集的信息来做出这些判断。如果在循环的前几次迭代中某件事一直是正确的,它就会假设它将继续是正确的。
但当然,在 JavaScript 中,没有任何保证。您可能有 99 个形状相同的对象,但第 100 个对象可能缺少一个属性。
因此,已编译代码需要在运行之前进行检查,以查看这些假设是否有效。如果有效,则已编译代码将运行。但如果无效,JIT 假设它做出了错误的假设,并丢弃了优化后的代码。
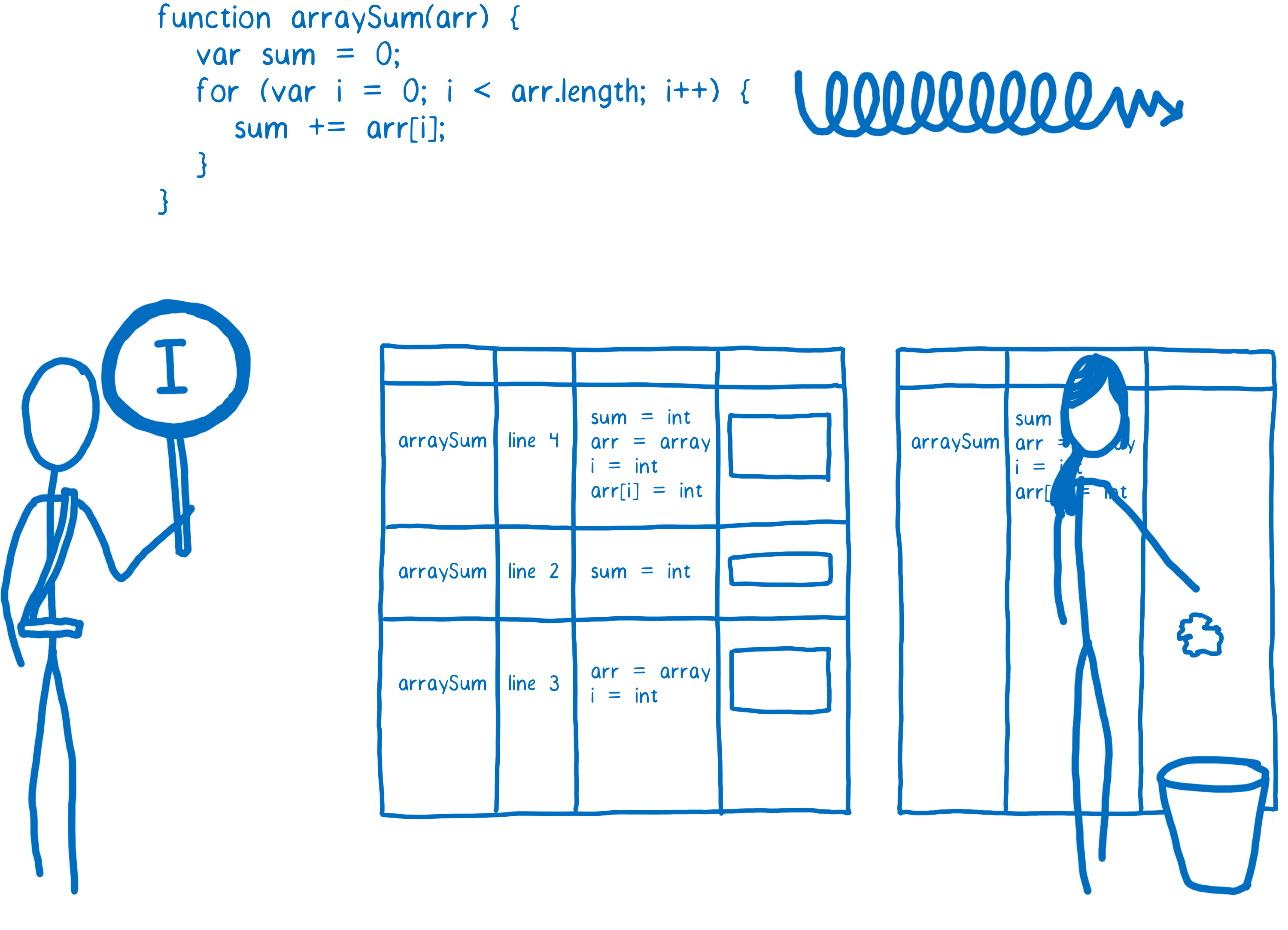
然后执行将返回到解释器或基线编译版本。此过程称为反优化(或跳出)。
优化编译器通常会使代码更快,但有时它们会导致意外的性能问题。如果您有代码不断被优化然后反优化,它最终会比只执行基线编译版本更慢。
大多数浏览器添加了限制,以便在发生这些优化/反优化循环时从中跳出。如果 JIT 尝试优化了超过 10 次,并且一直不得不将其丢弃,它将不再尝试。
优化示例:类型专门化
有很多不同的优化类型,但我希望看一看其中一种类型,这样您就可以了解优化是如何发生的。优化编译器中最大的收益之一来自称为类型专门化的东西。
JavaScript 使用的动态类型系统在运行时需要一些额外的操作。例如,考虑以下代码
function arraySum(arr) {
var sum = 0;
for (var i = 0; i < arr.length; i++) {
sum += arr[i];
}
}
循环中的+=步骤看似很简单。它似乎可以在一步中计算出来,但由于动态类型,它需要比您预期的更多步骤。
假设arr是一个包含 100 个整数的数组。一旦代码变暖,基线编译器将为函数中的每个操作创建一个存根。因此将有一个用于sum += arr[i]的存根,它将处理+=操作作为整数加法。
但是,sum和arr[i]不保证是整数。由于 JavaScript 中的类型是动态的,因此在循环的后续迭代中,arr[i]可能是一个字符串。整数加法和字符串连接是两个截然不同的操作,因此它们将编译成截然不同的机器代码。
JIT 处理此问题的办法是编译多个基线存根。如果一段代码是单态的(即始终以相同的类型调用),它将获得一个存根。如果它是多态的(从代码的一次迭代到另一次迭代以不同的类型调用),那么它将为通过该操作的每种类型组合获得一个存根。
这意味着 JIT 必须在选择一个存根之前问很多问题。

由于代码的每一行在基线编译器中都有自己的存根集,因此 JIT 需要在每次执行代码行时都检查类型。因此,在循环的每次迭代中,它都必须问相同的问题。
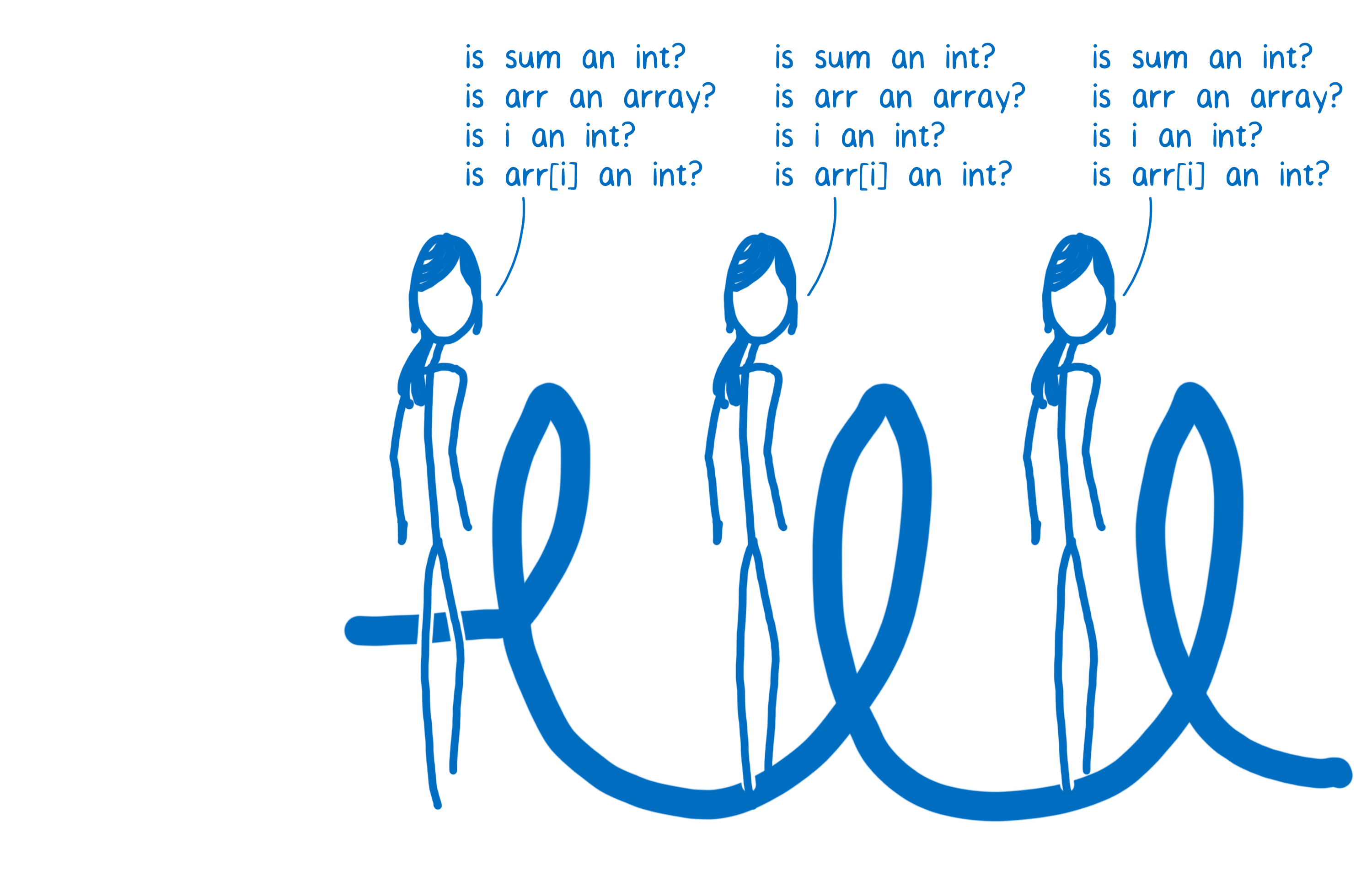
如果 JIT 不需要重复这些检查,代码将执行得快得多。这就是优化编译器所做的事情之一。
在优化编译器中,整个函数一起编译。类型检查已移动到循环之前执行。
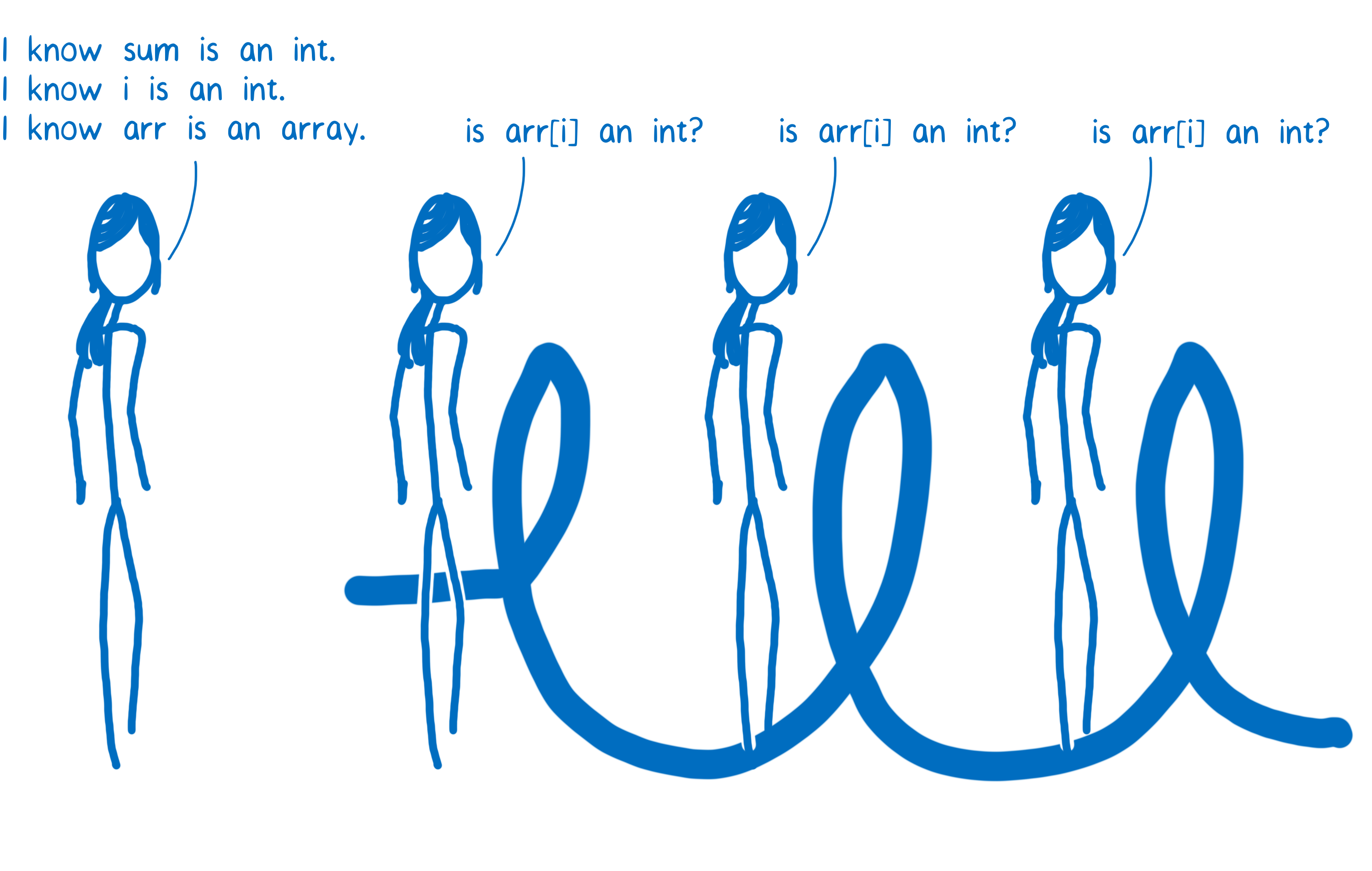
一些 JIT 进一步优化了这一点。例如,在 Firefox 中,有一个特殊的分类用于仅包含整数的数组。如果arr是其中一个数组,那么 JIT 不需要检查arr[i]是否是一个整数。这意味着 JIT 可以在进入循环之前完成所有类型检查。
结论
这就是 JIT 的简要介绍。它通过监视代码的运行并将热代码路径发送到优化来使 JavaScript 运行速度更快。这导致大多数 JavaScript 应用程序的性能提高了数倍。
尽管有这些改进,但 JavaScript 的性能仍然是不可预测的。为了使速度更快,JIT 在运行时添加了一些开销,包括
- 优化和反优化
- 监视器的簿记使用的内存以及跳出时恢复信息使用的内存
- 用于存储函数的基线版本和优化版本的内存
这里还有改进的空间:可以消除这些开销,从而使性能更具可预测性。这就是 WebAssembly 所做的工作之一。
在下一篇文章中,我将解释有关汇编以及编译器如何与其协作的更多信息。
关于 Lin Clark
Lin 在 Mozilla 的高级开发部门工作,专注于 Rust 和 WebAssembly。
14 条评论