
这是 3 部分系列中的第一篇文章
为了理解为什么 ArrayBuffer 和 SharedArrayBuffer 被添加到 JavaScript 中,你需要了解一些关于内存管理的知识。
你可以把机器中的内存想象成一组箱子。我把它想象成办公室里那些邮箱,或者幼儿园孩子们用来存放东西的储物柜。
如果你需要给其他孩子留东西,你就可以把它放在一个箱子里。

在每个箱子旁边,你都有一个数字,那就是内存地址。这就是你告诉别人在哪里找到你为他们留下的东西的方式。
每个箱子都一样大小,可以容纳一定的信息量。箱子的尺寸取决于机器。这个尺寸被称为字长。它通常是 32 位或 64 位。但为了便于展示,我将使用 8 位的字长。
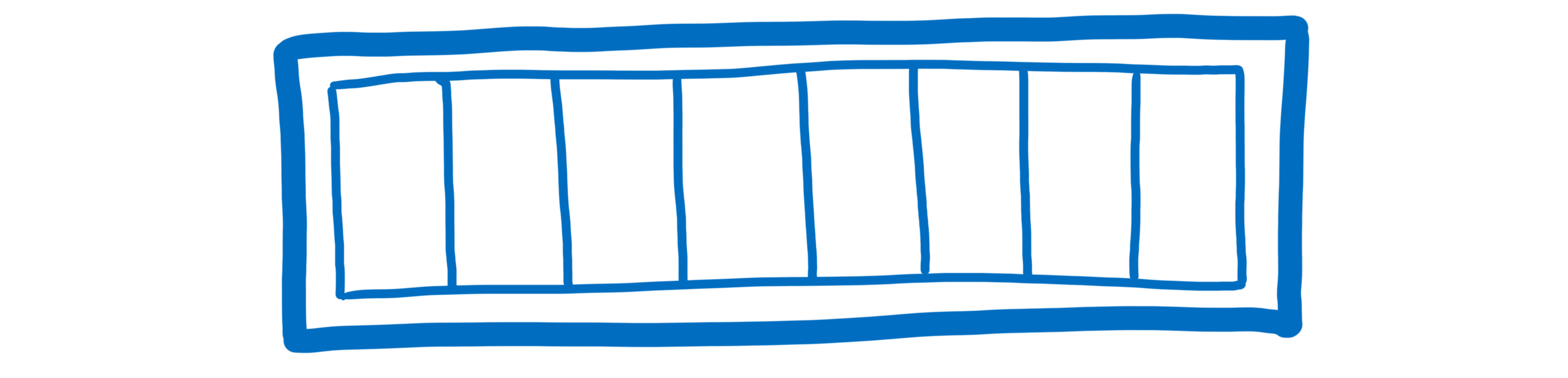
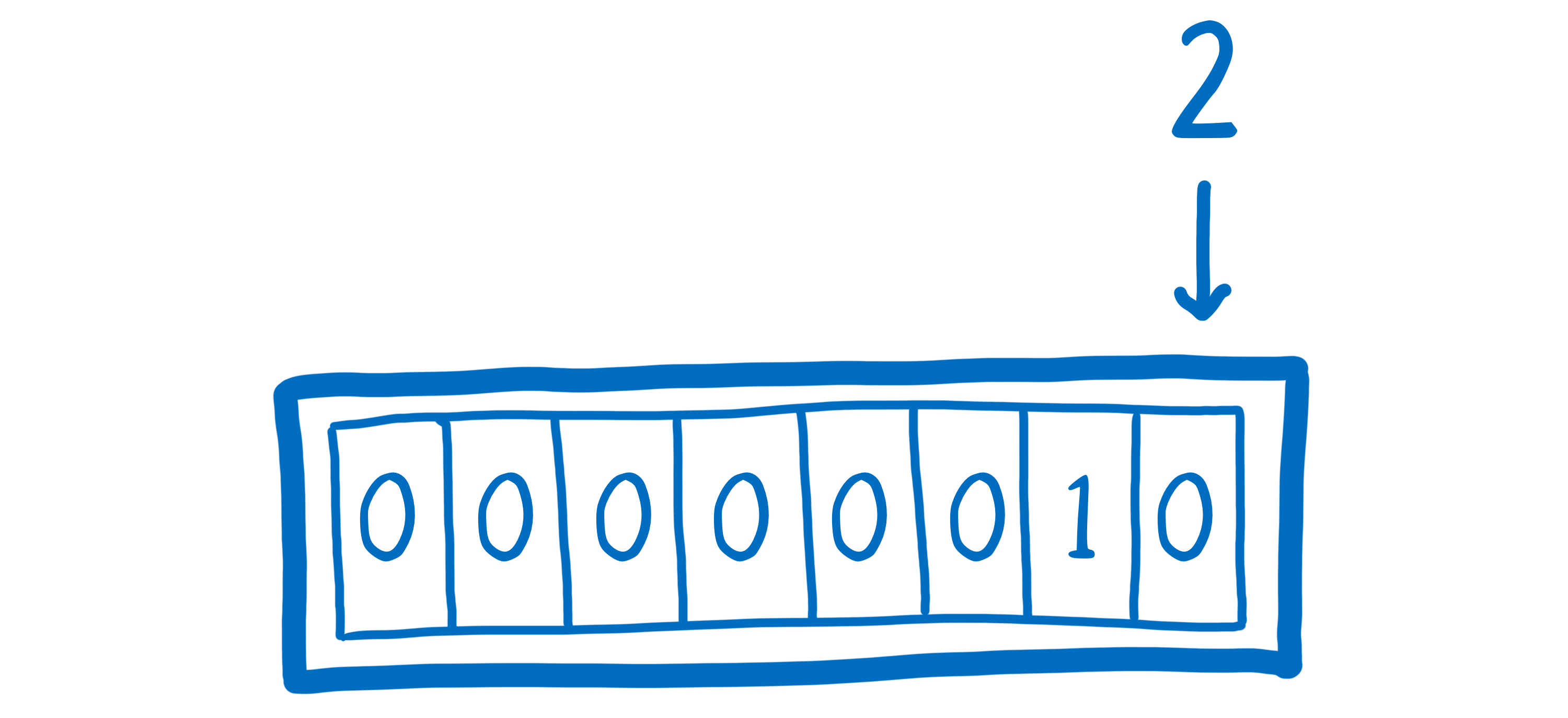
如果我们想把数字 2 放入这些箱子中的一个,我们可以很容易地做到。数字很容易用二进制表示。
但是,如果我们想要的是非数字的东西呢?比如字母 H?
我们需要一种方法将其表示为数字。为此,我们需要一种编码,比如 UTF-8。我们还需要一些东西将其转换为这个数字……比如一个编码环。然后我们就可以存储它了。

当我们想要把它从箱子里取出来时,我们需要把它通过解码器,将其翻译回 H。
自动内存管理
当你在 JavaScript 中工作时,你实际上不需要考虑内存。它对你来说是抽象的。这意味着你不会直接接触内存。
相反,JS 引擎充当中间人。它会为你管理内存。
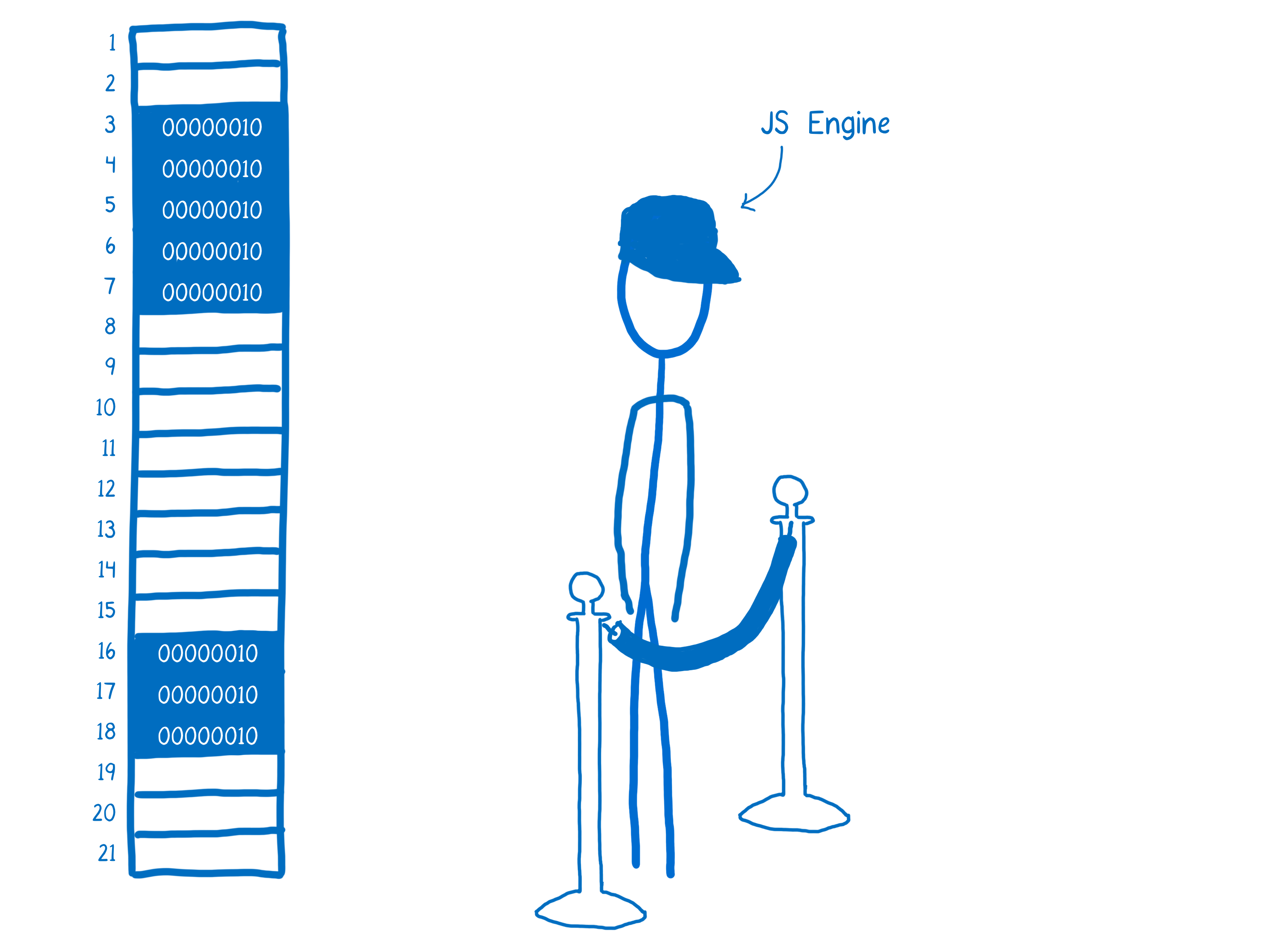
所以,假设一些 JS 代码,比如 React,想要创建一个变量。
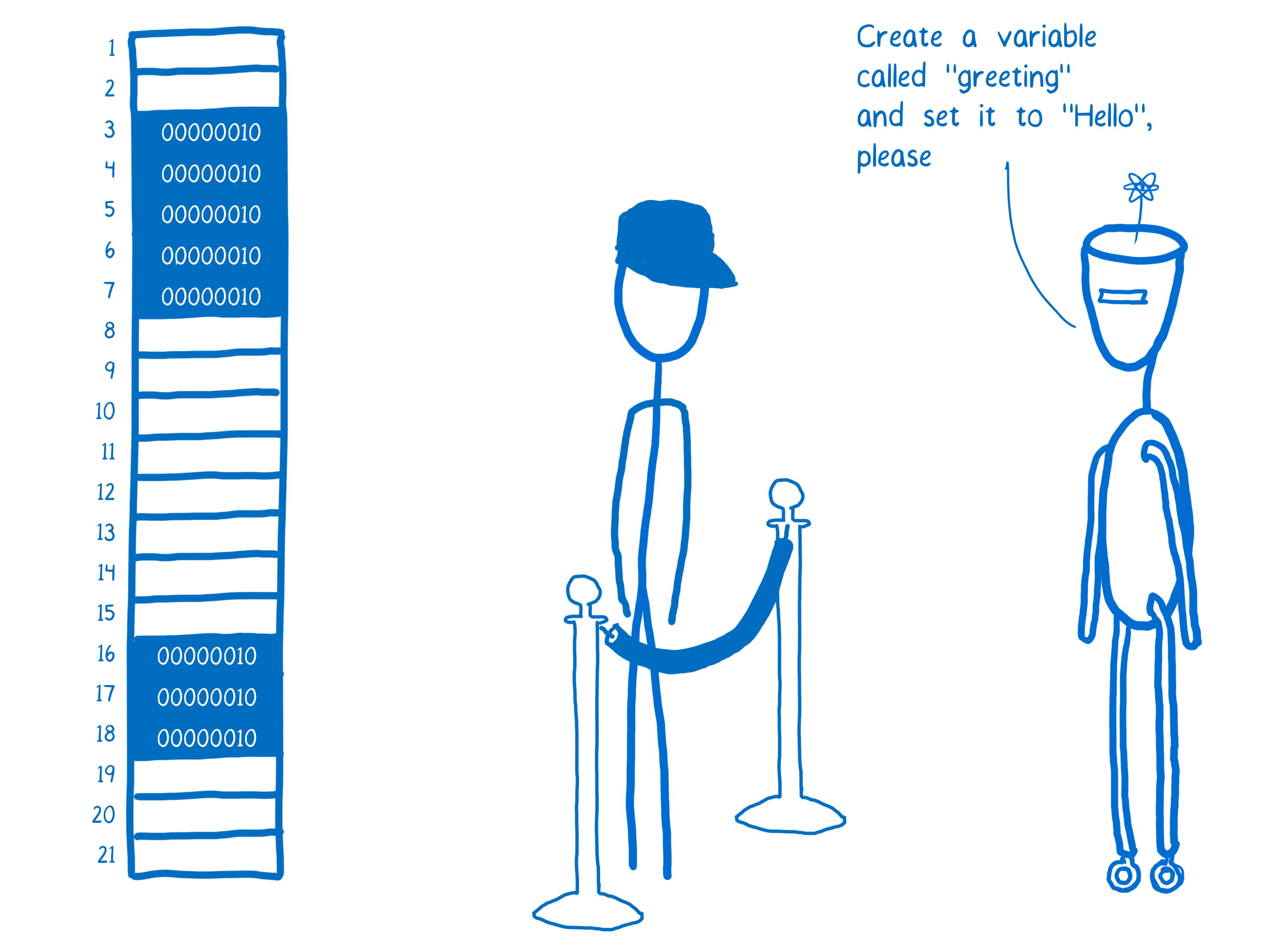
JS 引擎所做的是将该值通过编码器,获得该值的二进制表示。
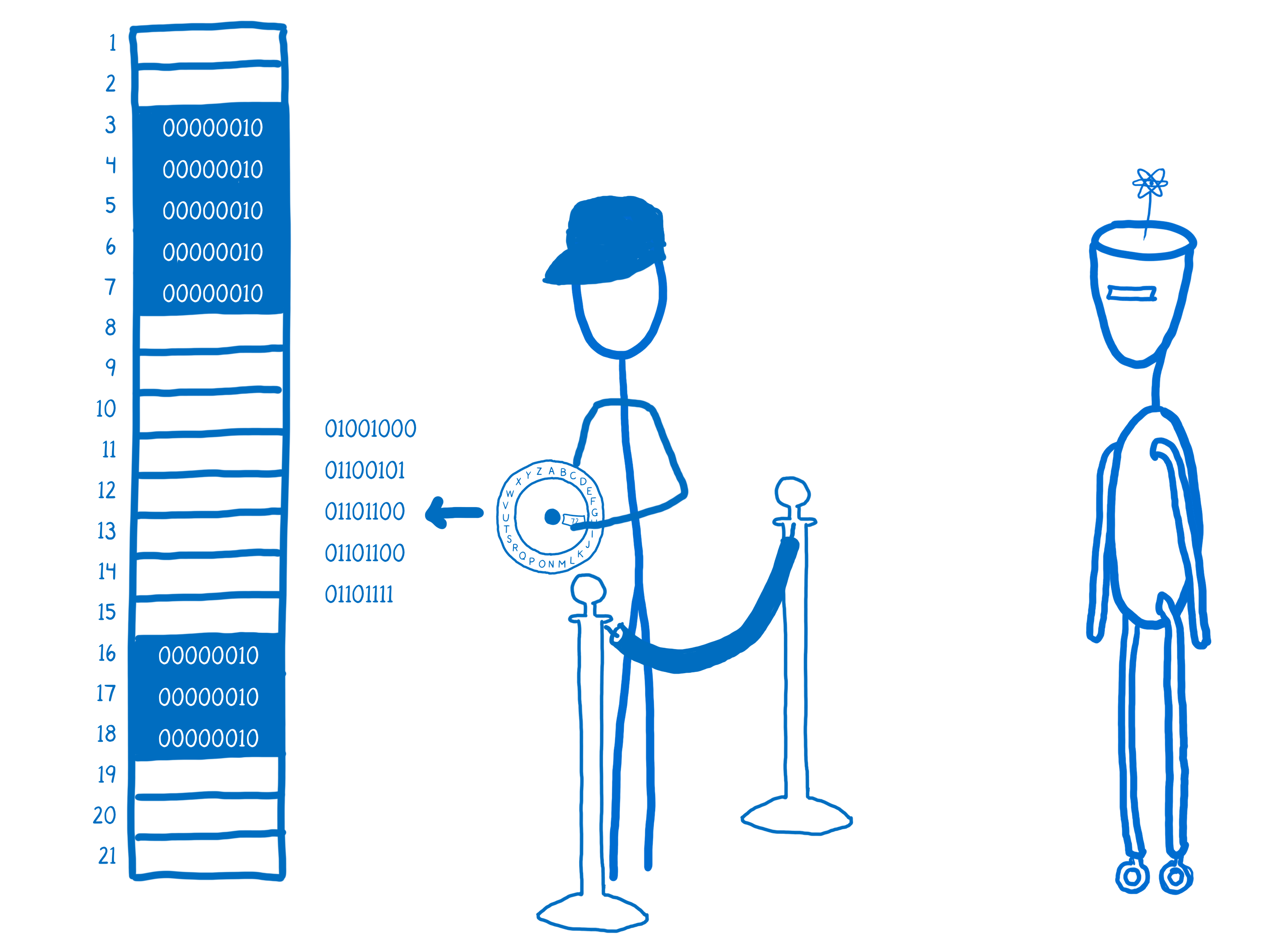
它会在内存中找到可以容纳这个二进制表示的空间。这个过程被称为分配内存。
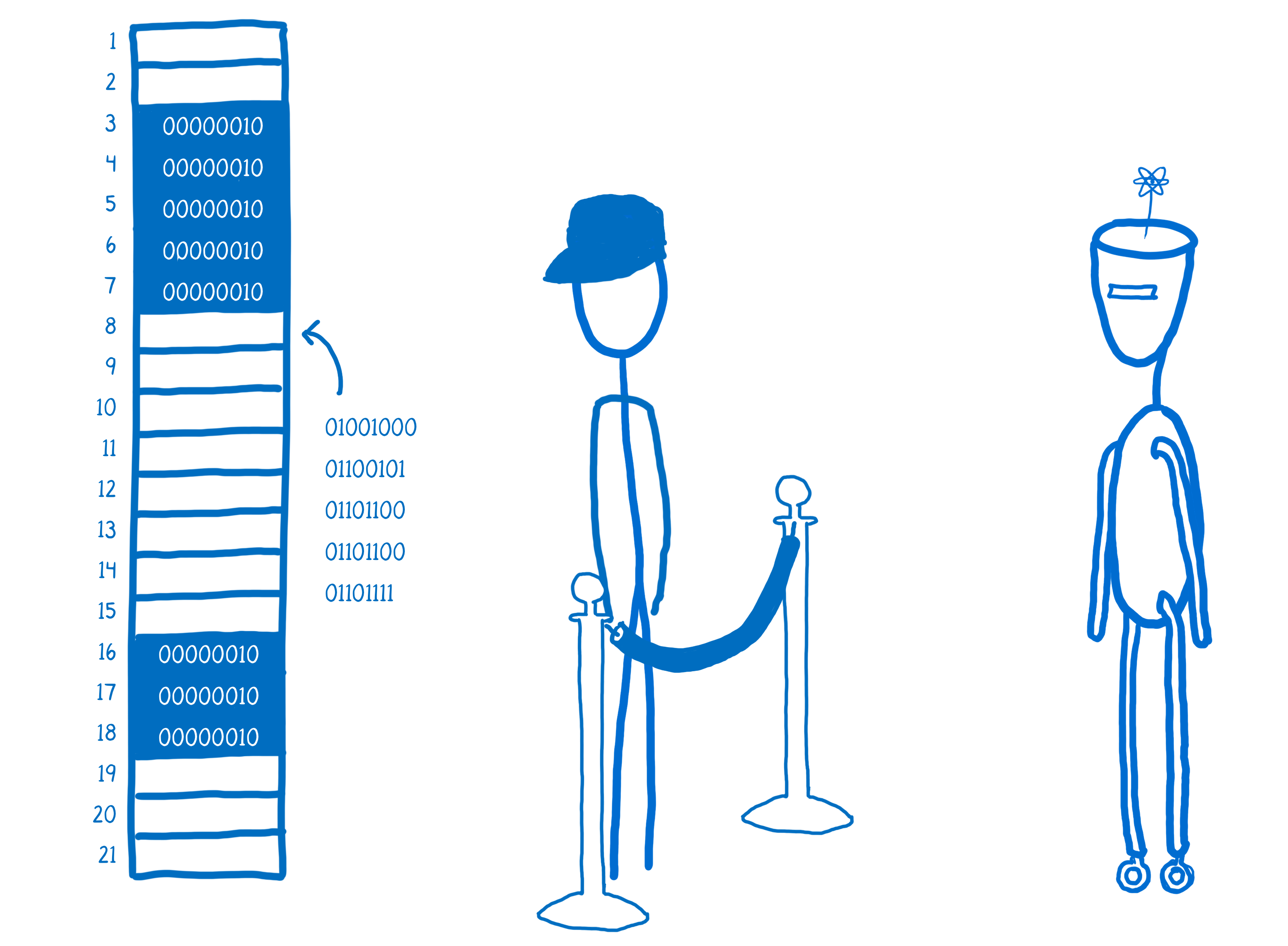
然后,引擎会跟踪这个变量是否仍然可以在程序中的任何地方访问。如果这个变量不再可以访问,内存将被回收,以便 JS 引擎可以将新的值放入其中。

这个观察变量(字符串、对象和其他存储在内存中的值)并在它们不再可以访问时清除它们的过程称为垃圾收集。
像 JavaScript 这样的语言,代码不直接处理内存,被称为内存管理语言。
这种自动内存管理可以使开发人员的生活更轻松。但它也增加了一些开销。而这些开销有时会使性能变得不可预测。
手动内存管理
手动管理内存的语言则不同。例如,让我们看看如果 React 是用 C 语言编写的,它将如何与内存交互(现在这已经可以实现了,使用WebAssembly)。
C 没有像 JavaScript 那样在内存上进行抽象。相反,你直接操作内存。你可以从内存中加载东西,也可以将东西存储到内存中。

当你将 C 或其他语言编译成 WebAssembly 时,你使用的工具会将一些辅助代码添加到你的 WebAssembly 中。例如,它会添加执行字节编码和解码的代码。这段代码被称为运行时环境。运行时环境将帮助处理 JS 引擎为 JS 做的一些事情。
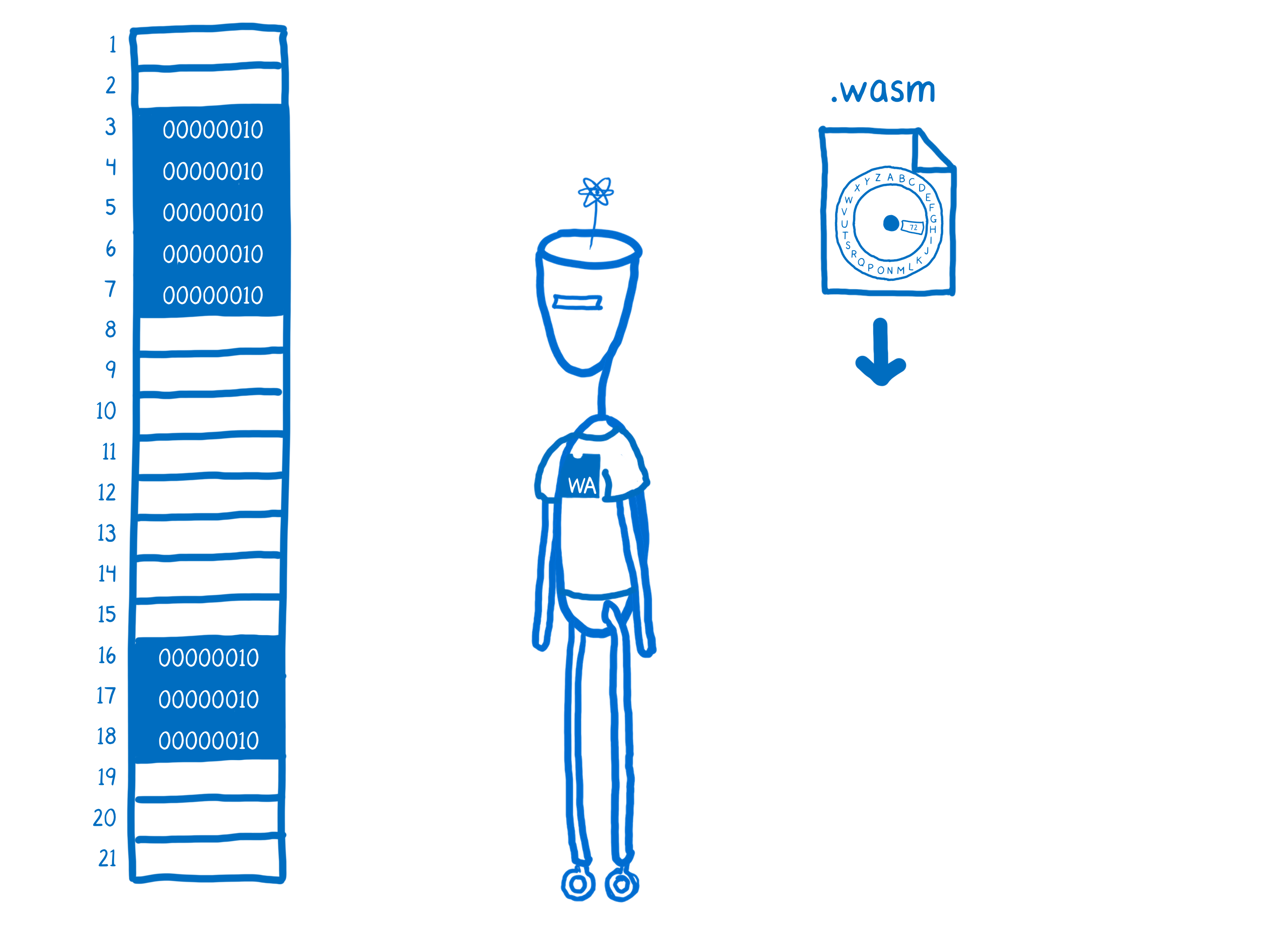
但是对于手动管理的语言,运行时环境将不包括垃圾收集。
这并不意味着你完全依靠自己。即使在手动管理内存的语言中,你通常也会得到来自语言运行时环境的帮助。例如,在 C 中,运行时环境会跟踪哪些内存地址是开放的,在一个叫做空闲列表的东西中。

你可以使用函数 malloc(memory allocate 的缩写)来请求运行时环境找到一些可以容纳你的数据的内存地址。这将从空闲列表中取出这些地址。当你完成了对这些数据的操作后,你需要调用 free 来释放内存。然后这些地址将被添加回空闲列表。
你需要自己弄清楚何时调用这些函数。这就是它被称为手动内存管理的原因——你自行管理内存。
作为一名开发者,弄清楚何时清除内存的不同部分可能很困难。如果你在错误的时间这样做,可能会导致错误,甚至会导致安全漏洞。如果你没有这样做,你就会耗尽内存。
这就是为什么许多现代语言使用自动内存管理的原因——为了避免人为错误。但这是以性能为代价的。我会在下一篇文章中对此进行更详细的解释。
关于 Lin Clark
Lin 在 Mozilla 的高级开发部门工作,专注于 Rust 和 WebAssembly。
19 条评论