
Firefox Quantum 版本即将发布,它带来了许多性能改进,包括我们从 Servo 移植过来的超高速 CSS 引擎。
但 Servo 还有另一个重要的技术尚未包含在 Firefox Quantum 中,不过很快就会发布。这就是 WebRender,它将作为 Quantum Render 项目的一部分添加到 Firefox 中。
WebRender 以其极快的速度而闻名。但 WebRender 的重点并非仅仅是加快渲染速度,而是让渲染更加流畅。
借助 WebRender,我们希望应用程序无论显示屏尺寸多大、页面帧与帧之间变化量多大,都能以丝般顺滑的每秒 60 帧 (FPS) 或更高速度运行。而且它确实做到了。在 Chrome 或当今版本的 Firefox 中以 15 FPS 运行的页面,在 WebRender 的帮助下,可以达到 60 FPS。
那么 WebRender 是如何做到的呢?它从根本上改变了渲染引擎的工作方式,使其更像一个 3D 游戏引擎。
让我们看看这意味着什么。但首先…
渲染器做什么?
在关于 Stylo 的文章中,我谈到了浏览器如何从 HTML 和 CSS 转变为屏幕上的像素,以及大多数浏览器如何通过五个步骤完成此过程。
我们可以将这五个步骤分为两个部分。前半部分基本上是在制定一个计划。为了制定这个计划,它会将 HTML 和 CSS 与视口大小等信息结合起来,以确定每个元素应该是什么样的——它的宽度、高度、颜色等。最终的结果是所谓的帧树或渲染树。
后半部分——绘制和合成——是渲染器的工作。它将该计划转化为像素,以便在屏幕上显示。
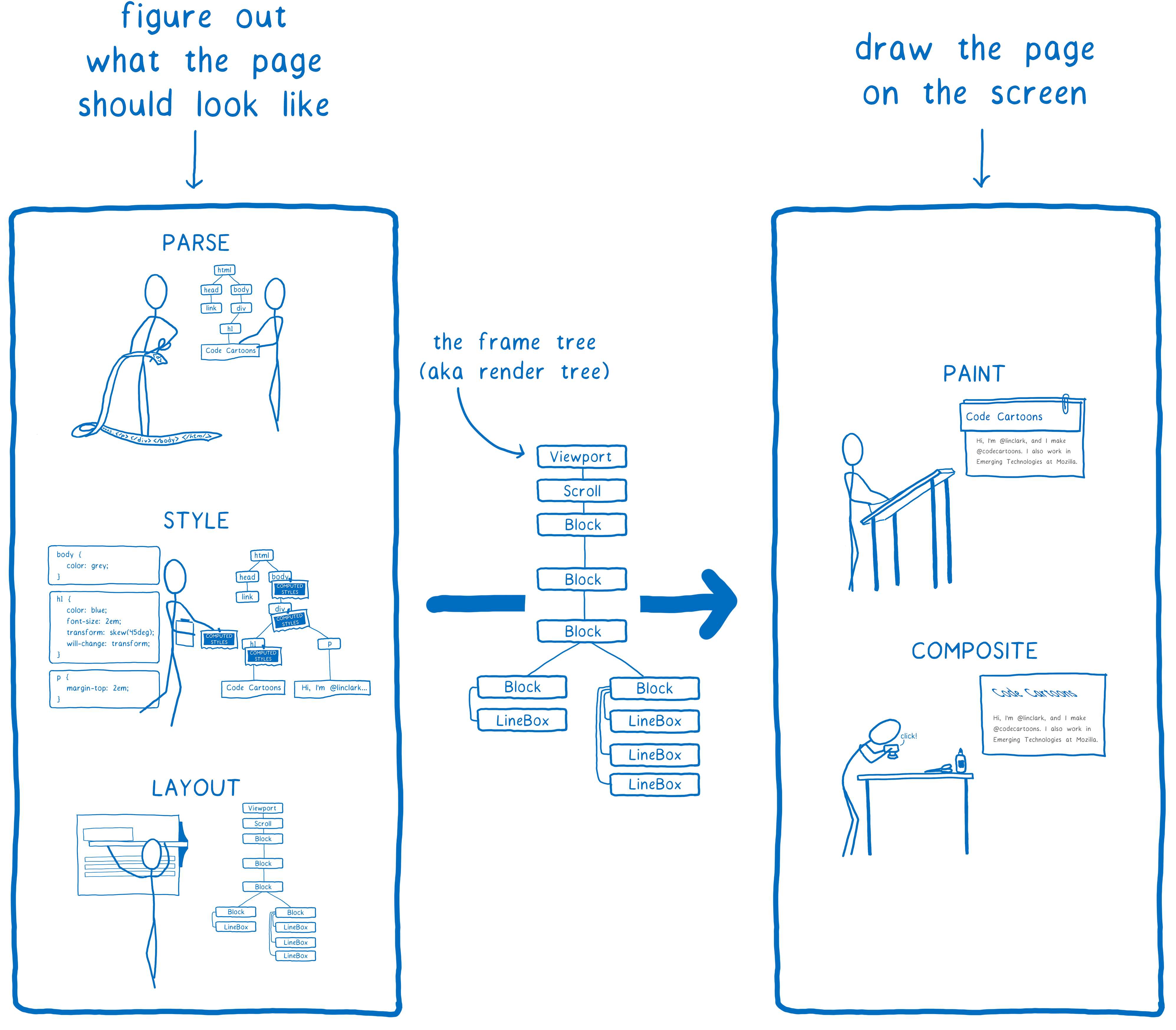
但浏览器不仅需要对网页执行一次此操作。它需要对同一个网页反复执行。只要该页面上的任何内容发生变化——例如,一个 div 被切换为打开——浏览器就必须执行很多这样的步骤。

即使在页面上没有任何实质性变化的情况下——例如,您正在滚动或在页面上突出显示一些文本——浏览器仍然需要至少重新执行第二部分的某些步骤,以在屏幕上绘制新的像素。

如果您希望滚动或动画等操作看起来流畅,它们需要以每秒 60 帧的速度运行。
您可能之前听说过这个词——每秒帧数 (FPS),但不确定它是什么意思。我认为这就像一本翻页书。它就像一本静止的绘图书,但你可以用拇指翻页,这样看起来页面就像动画一样。
为了使这本翻页书中的动画看起来流畅,您需要在动画的每一秒中包含 60 页。
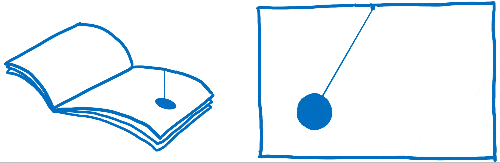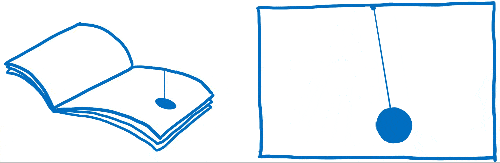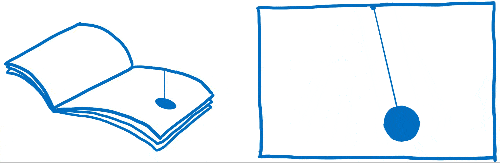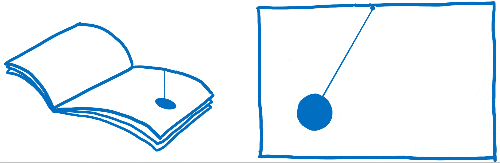
这本翻页书的页面是用方格纸做的。有许多小方块,每个方块只能包含一种颜色。
渲染器的任务是在这张方格纸上填色。一旦方格纸上的所有方格都填满,它就完成了帧的渲染。
当然,您的计算机内部并没有真正的方格纸。取而代之的是,计算机的内存中有一个部分叫做帧缓冲区。帧缓冲区中的每个内存地址就像方格纸中的一个方格……它对应于屏幕上的一个像素。浏览器会用代表 RGBA(红色、绿色、蓝色和 alpha)值的数字填充每个插槽。
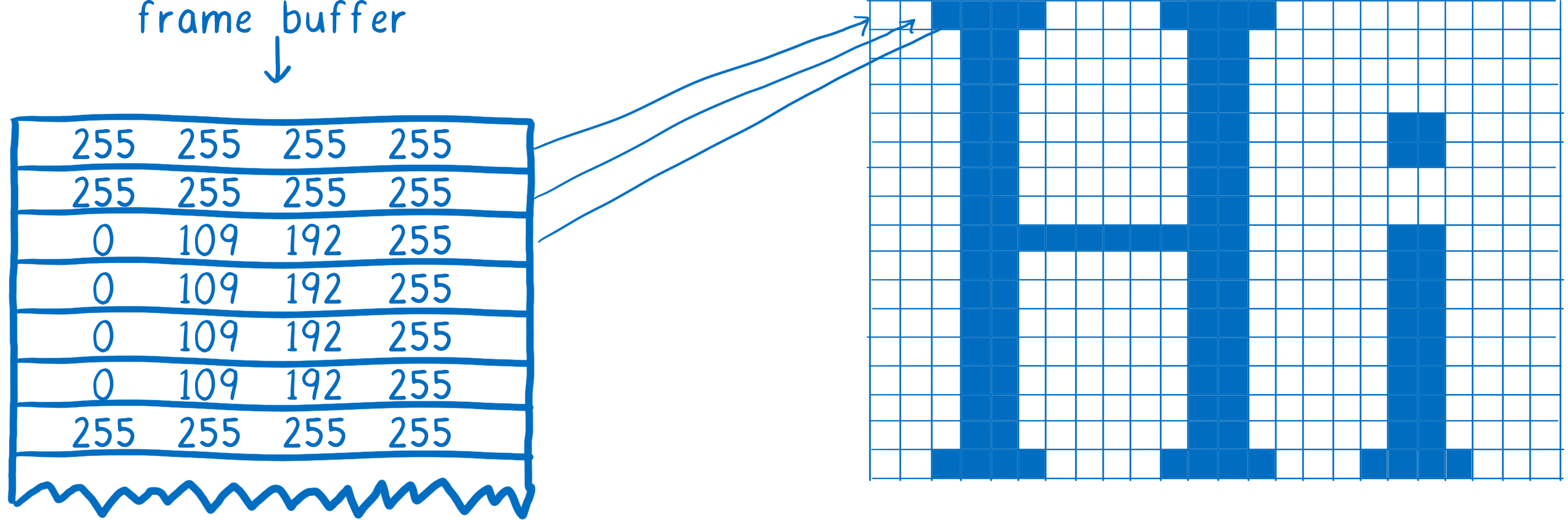
当显示器需要刷新时,它会查看内存中的这部分内容。
大多数计算机显示器每秒刷新 60 次。这就是浏览器尝试以每秒 60 帧的速度渲染页面的原因。这意味着浏览器有 16.67 毫秒的时间来完成所有设置——CSS 样式、布局、绘制——并在帧缓冲区的所有插槽中填充像素颜色。两次帧之间的这段时间(16.67 毫秒)被称为帧预算。
有时您会听到人们谈论掉帧。掉帧是指系统未能在帧预算内完成工作。显示器尝试在浏览器完成填充之前从帧缓冲区获取新帧。在这种情况下,显示器会再次显示旧版本的帧。
掉帧就像从翻页书中撕掉一页。它会导致动画看起来卡顿或跳跃,因为您错过了上一页到下一页的过渡。
因此,我们希望确保在显示器再次检查之前将所有这些像素都放入帧缓冲区中。让我们看看浏览器历来是如何做到的,以及随着时间的推移是如何改变的。然后我们可以看看如何让它变得更快。
绘制和合成的简要历史
注意:绘制和合成是浏览器渲染引擎之间差异最大的地方。单平台浏览器(Edge 和 Safari)的工作方式与多平台浏览器(Firefox 和 Chrome)的工作方式略有不同。
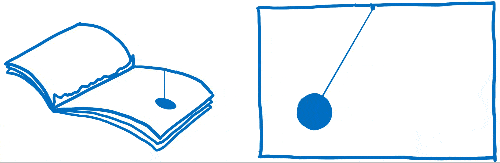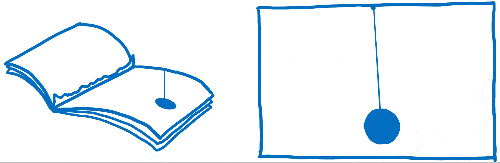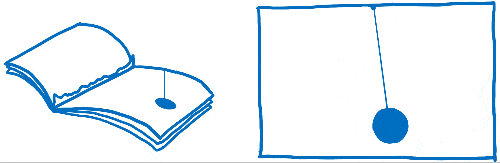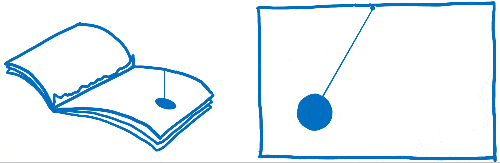
即使在最早的浏览器中,也有一些优化措施可以加快页面渲染速度。例如,如果您正在滚动内容,浏览器会保留仍然可见的部分并将其移动。然后它会在空白区域绘制新的像素。
这个确定哪些内容发生了变化,然后只更新发生变化的元素或像素的过程称为失效。
随着时间的推移,浏览器开始应用更多失效技术,例如矩形失效。使用矩形失效,您可以找出屏幕上每个发生变化的部分周围最小的矩形。然后,您只重新绘制这些矩形内部的内容。
这确实减少了页面变化不大的情况下需要执行的工作量……例如,当您只有一个闪烁的光标时。
但这在页面的大部分内容发生变化时帮助不大。因此,浏览器想出了新的技术来处理这些情况。
引入图层和合成
当页面的大部分内容发生变化时,使用图层可以帮助很多……至少在某些情况下是如此。
浏览器中的图层很像 Photoshop 中的图层,或者手工绘制动画中使用的洋葱皮图层。基本上,您在不同的图层上绘制页面的不同元素。然后将这些图层彼此叠放。
它们已经成为浏览器的一部分很久了,但它们并不总是用来加快速度。最初,它们只是用来确保页面正确渲染。它们对应于所谓的堆叠上下文。
例如,如果您有一个半透明元素,它将位于自己的堆叠上下文中。这意味着它拥有自己的图层,这样您就可以将它的颜色与下面的颜色混合。这些图层在帧完成后就会被丢弃。在下一帧中,所有图层都将被重新绘制。
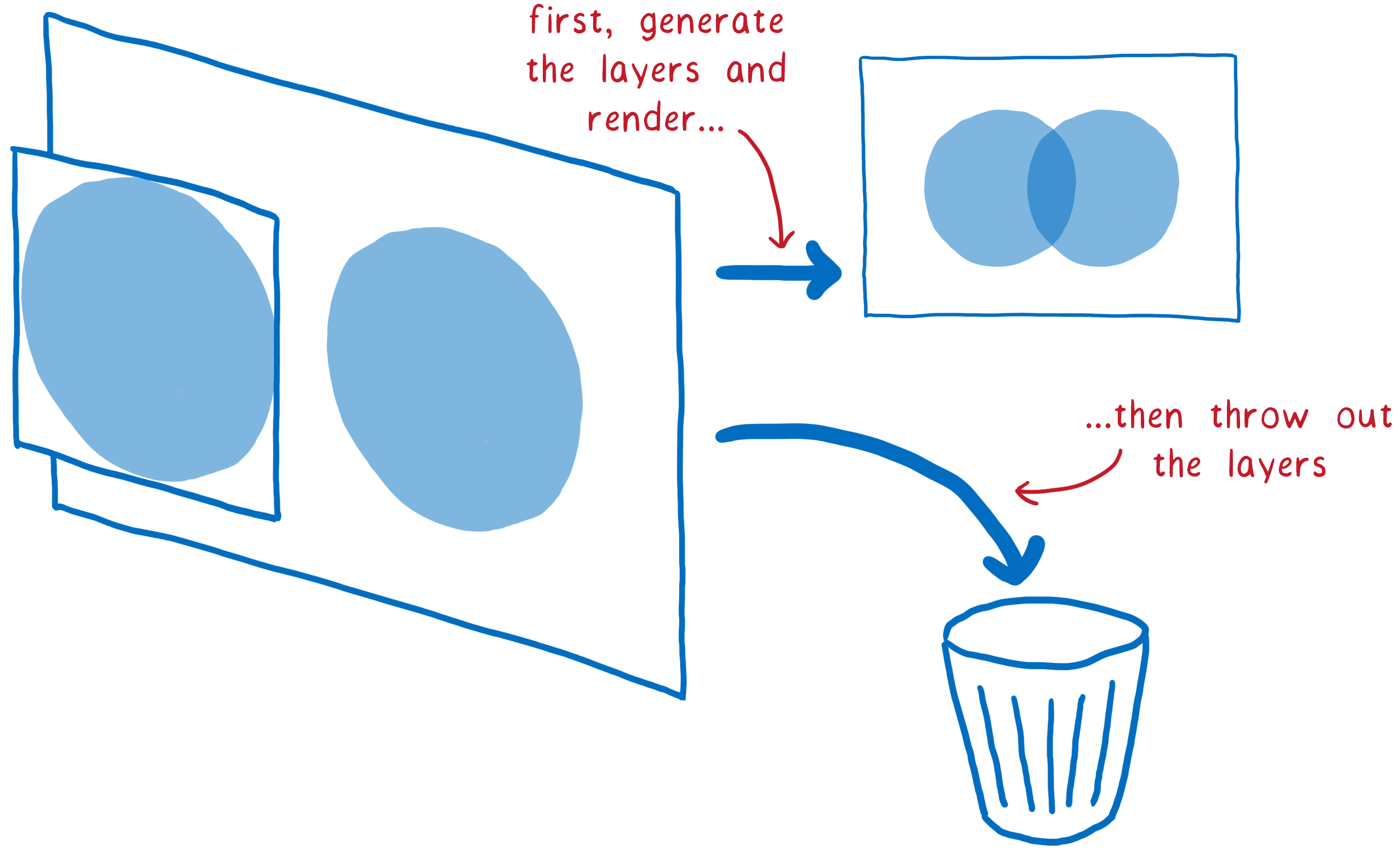
但这些图层上的内容通常不会在帧与帧之间发生变化。例如,想想传统的动画。即使前景中的角色发生变化,背景也不会改变。保留背景图层并重复使用它效率更高。
因此,浏览器就是这样做的。它们保留了图层。然后浏览器可以只重新绘制发生变化的图层。在某些情况下,图层甚至没有发生变化。它们只需要重新排列——例如,如果动画在屏幕上移动,或者某些内容被滚动。
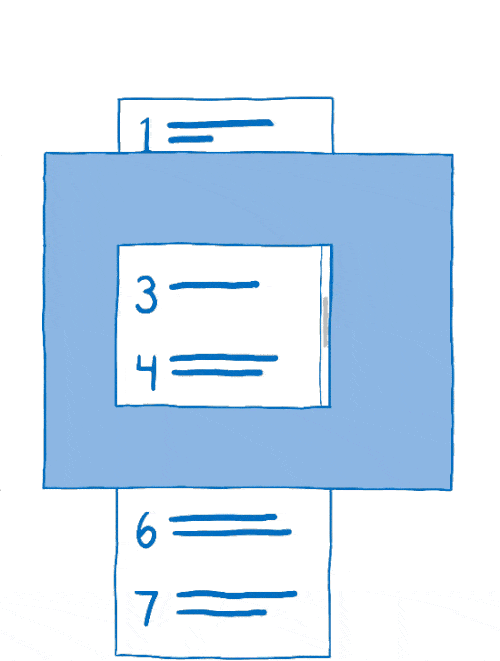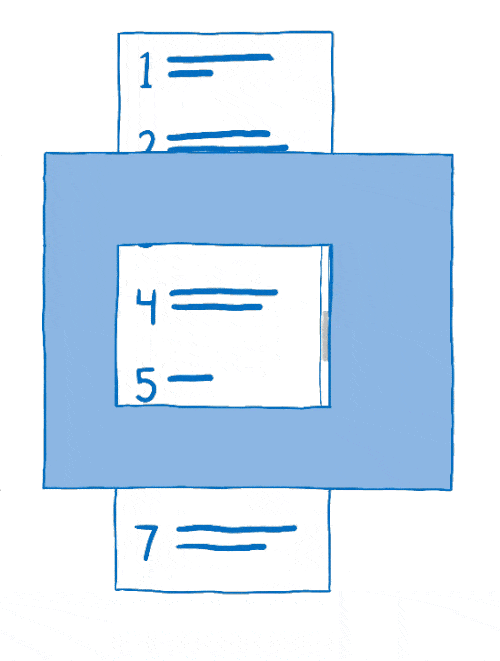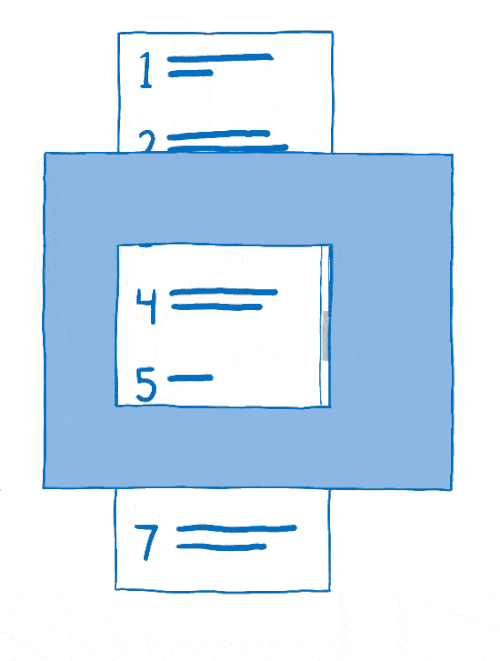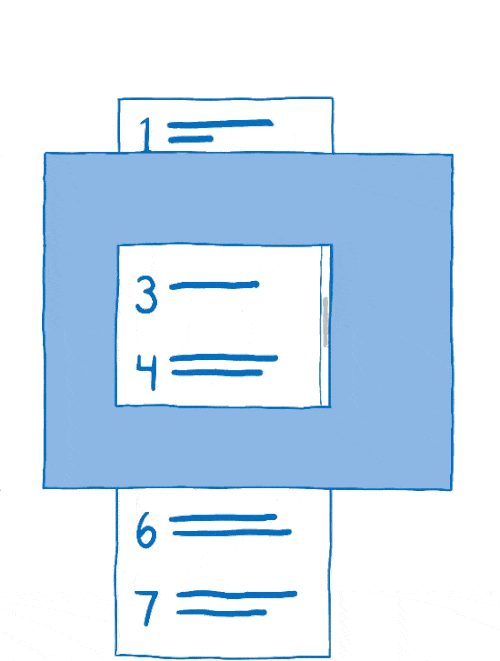
这个将图层组合在一起的过程称为合成。合成器从
- 源位图:背景(包括可滚动内容应位于其中的空白框)和可滚动内容本身
- 目标位图,它是在屏幕上显示的内容
首先,合成器会将背景复制到目标位图中。
然后它会确定可滚动内容的哪部分应该显示。它会将该部分复制到目标位图中。
这减少了主线程需要执行的绘制工作量。但它仍然意味着主线程在合成上花费了大量时间。而且有很多东西在争夺主线程的时间。
我之前已经谈过这个问题,但主线程就像一个全栈开发人员。它负责 DOM、布局和 JavaScript。而且它还负责绘制和合成。
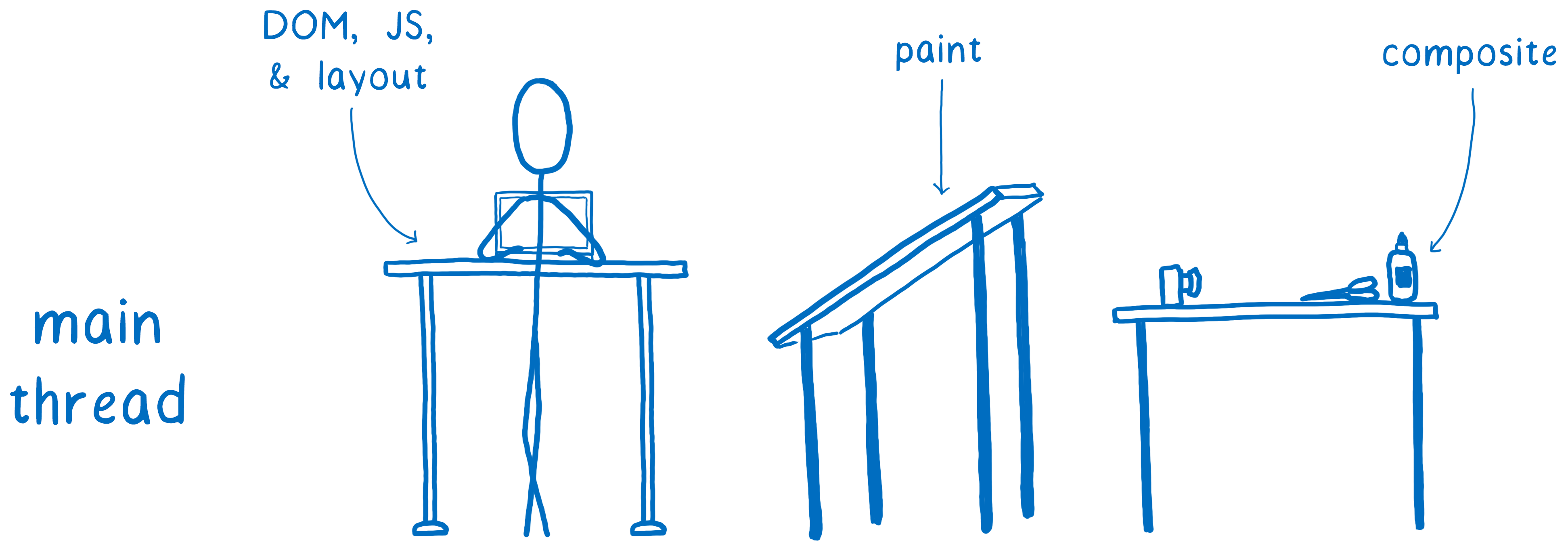
主线程每毫秒用于绘制和合成的时长,都是它不能用于 JavaScript 或布局的时长。

但硬件的另一个部分闲置着,没有多少工作要做。而且该硬件专门用于图形。那就是 GPU,从 90 年代末开始就被游戏用来快速渲染帧。而且从那以后,GPU 一直变得越来越大,功能越来越强大。
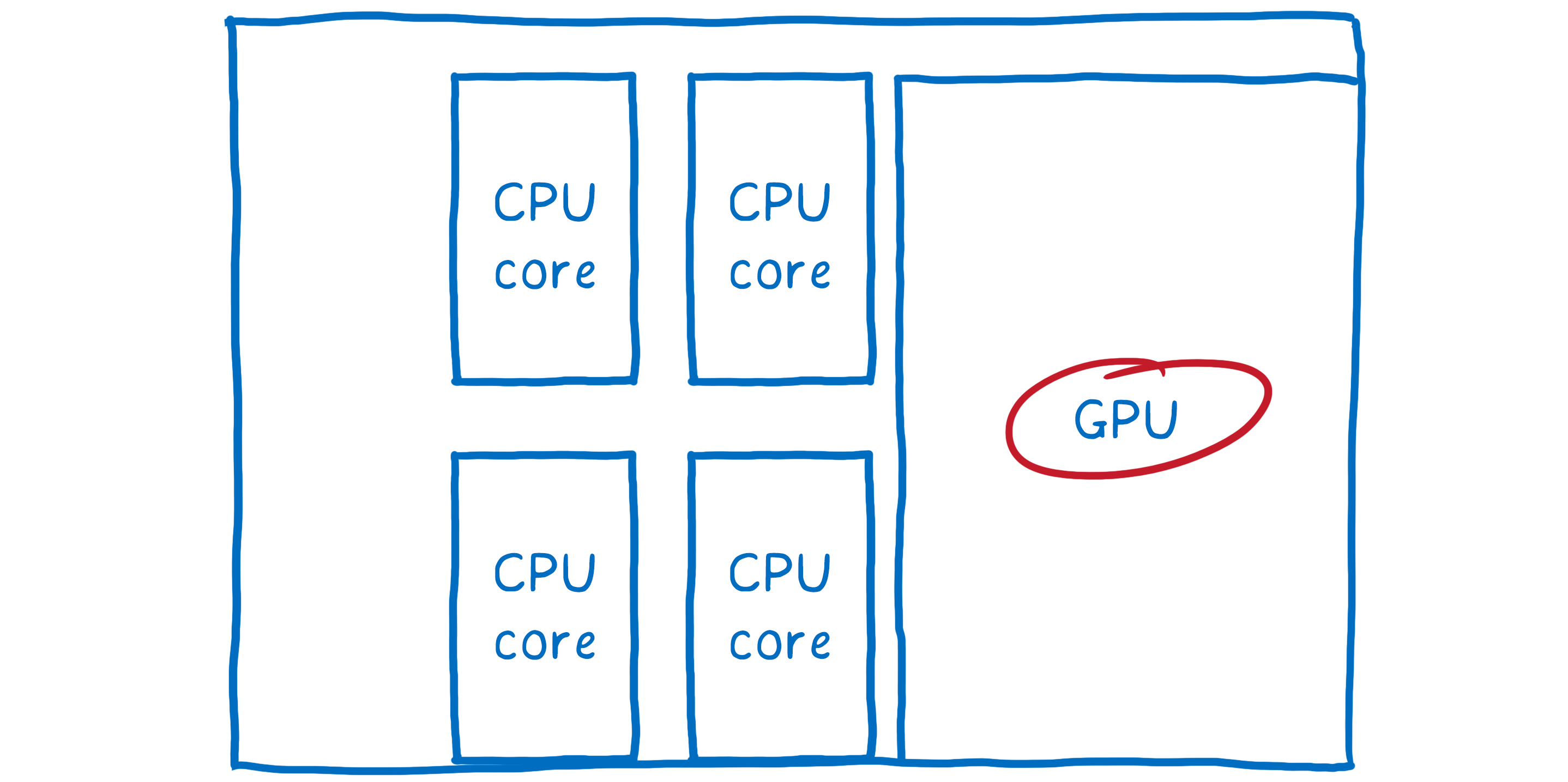
GPU 加速合成
因此,浏览器开发人员开始将一些东西迁移到 GPU 上。
有两项任务可以迁移到 GPU 上
- 绘制图层
- 将它们合成在一起
将绘制迁移到 GPU 上可能很困难。因此,大多数情况下,多平台浏览器仍然在 CPU 上进行绘制。
但合成是 GPU 可以非常快速地完成的操作,而且它很容易迁移到 GPU 上。
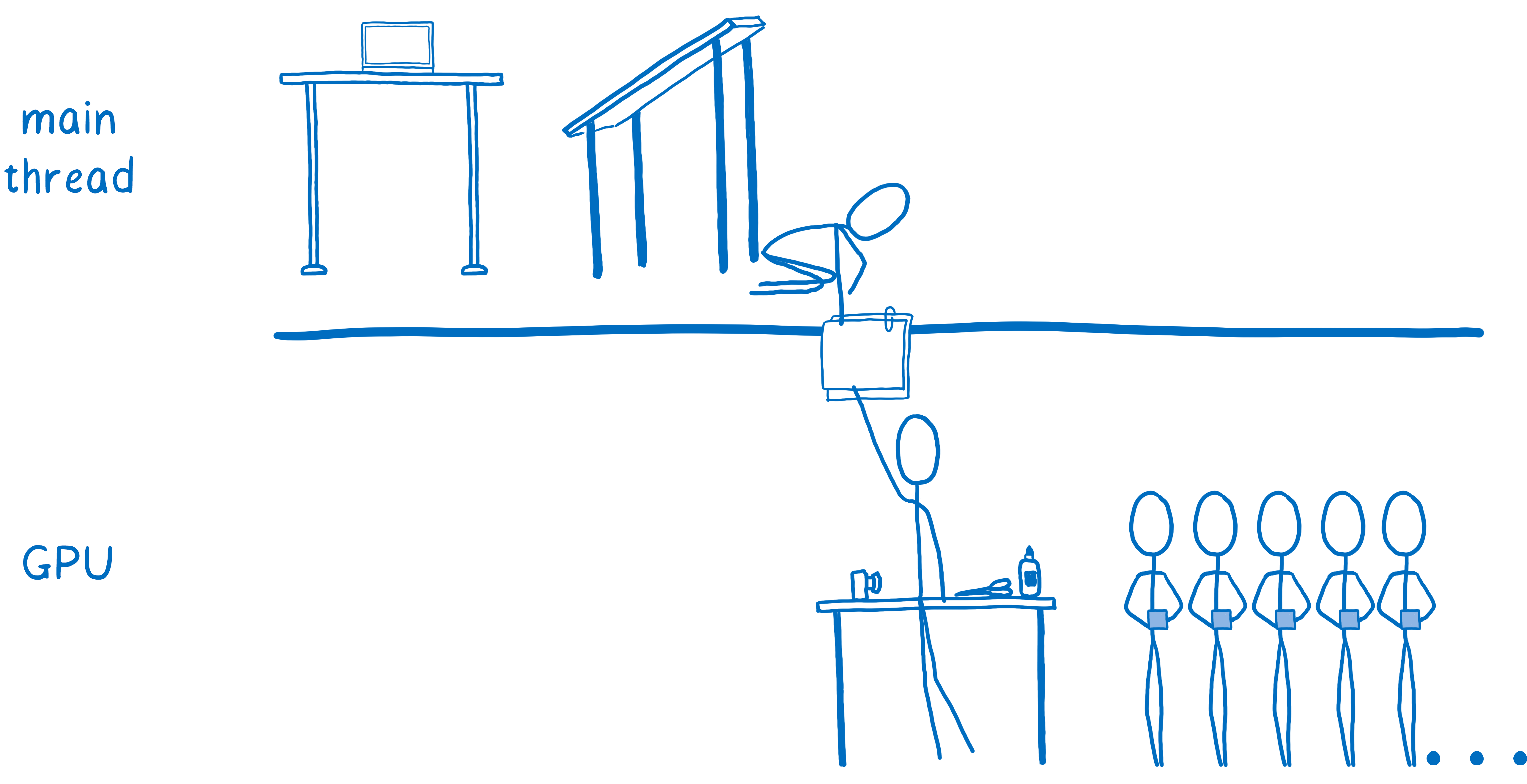
一些浏览器甚至更进一步,在 CPU 上添加了一个合成线程。它成为 GPU 上合成工作的管理器。这意味着,如果主线程正在执行某些操作(例如运行 JavaScript),合成线程仍然可以为用户处理一些事情,例如在用户滚动时向上滚动内容。
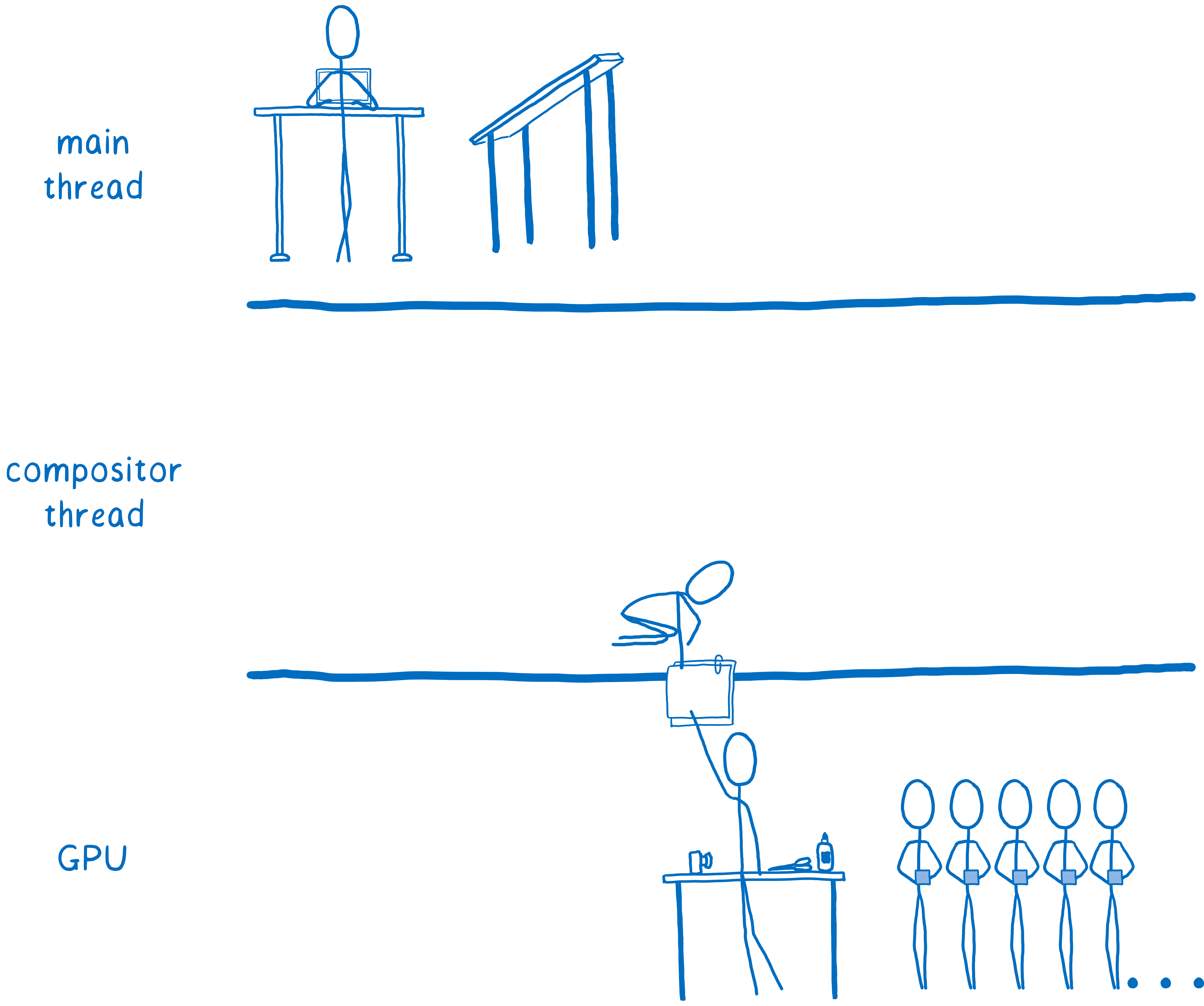
所以,这将所有合成工作移出主线程。不过,主线程上仍然留下了大量工作。每当我们需要重绘图层时,主线程都需要执行此操作,然后将该图层传输到 GPU。
一些浏览器将绘制转移到另一个线程(我们今天正在 Firefox 中进行这项工作)。但是,将最后一点工作(绘制)移到 GPU 上更快。
GPU 加速绘制
因此,浏览器也开始将绘制移到 GPU 上。

浏览器仍在进行这种转变。一些浏览器始终在 GPU 上进行绘制,而另一些浏览器仅在某些平台上进行绘制(例如,仅在 Windows 上或仅在移动设备上)。
在 GPU 上绘制会做几件事。它释放了 CPU,使其能够将所有时间用于执行 JavaScript 和布局等操作。此外,GPU 在绘制像素方面比 CPU 快得多,因此它加快了绘制速度。这也意味着从 CPU 到 GPU 的数据复制量更少。
但是,即使绘制和合成都在 GPU 上,在两者之间维护这种划分仍然会带来一些成本。这种划分也限制了您可以用来使 GPU 更快地完成工作的优化类型。
这就是 WebRender 的作用所在。它从根本上改变了我们渲染的方式,消除了绘制和合成之间的区别。这为我们提供了一种方法,可以根据今天的网络为您提供最佳的用户体验来调整渲染器的性能,并最佳地支持您将在明天的网络上看到的用例。
这意味着我们不仅希望使帧渲染得更快……我们希望使帧渲染得更一致,并且没有卡顿。即使有大量像素要绘制,例如在 4k 显示器或 WebVR 头显上,我们仍然希望体验保持平滑。
当前的浏览器何时会卡顿?
上面的优化已帮助页面在某些情况下更快地渲染。当页面上没有发生太多变化时(例如,当只有一个闪烁的光标时),浏览器将执行尽可能少的操作。
将页面分解成图层扩展了这些最佳情况场景的数量。如果您可以绘制几个图层,然后只需相对于彼此移动它们,那么绘制+合成架构就能很好地工作。
但是,使用图层也有权衡取舍。它们占用大量内存,实际上可能会降低速度。浏览器需要在有意义的地方组合图层……但很难判断在哪里有意义。
这意味着如果页面上有许多不同的东西在移动,最终可能会产生太多图层。这些图层会填满内存,并且将它们传输到合成器需要很长时间。
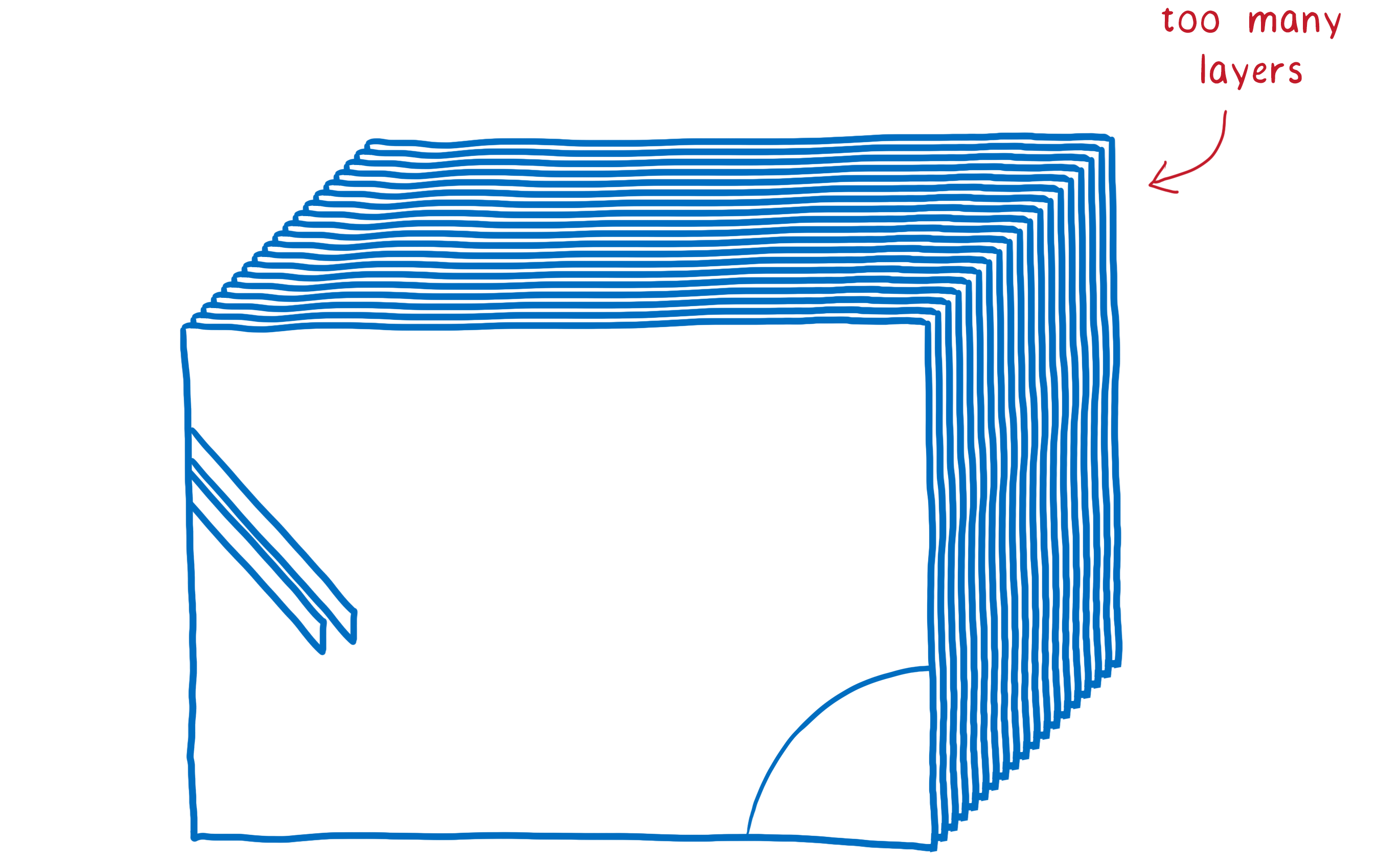
其他时候,您最终会得到一个图层,而您应该拥有多个图层。该单层将不断被重绘并传输到合成器,然后合成器对其进行合成而无需更改任何内容。
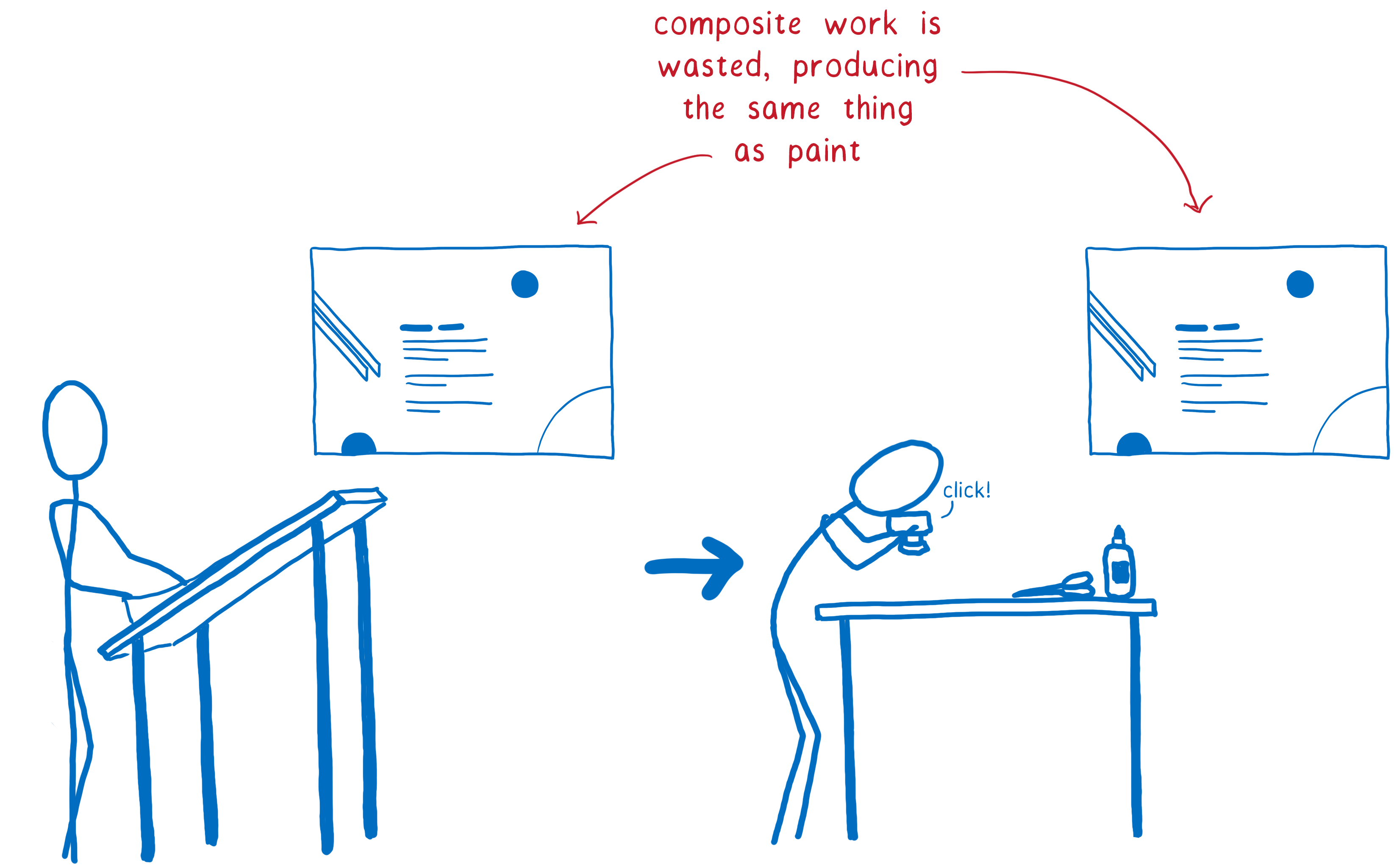
这意味着您必须执行两倍的绘制操作,触摸每个像素两次而没有任何好处。简单地直接渲染页面,而无需合成步骤,会更快。
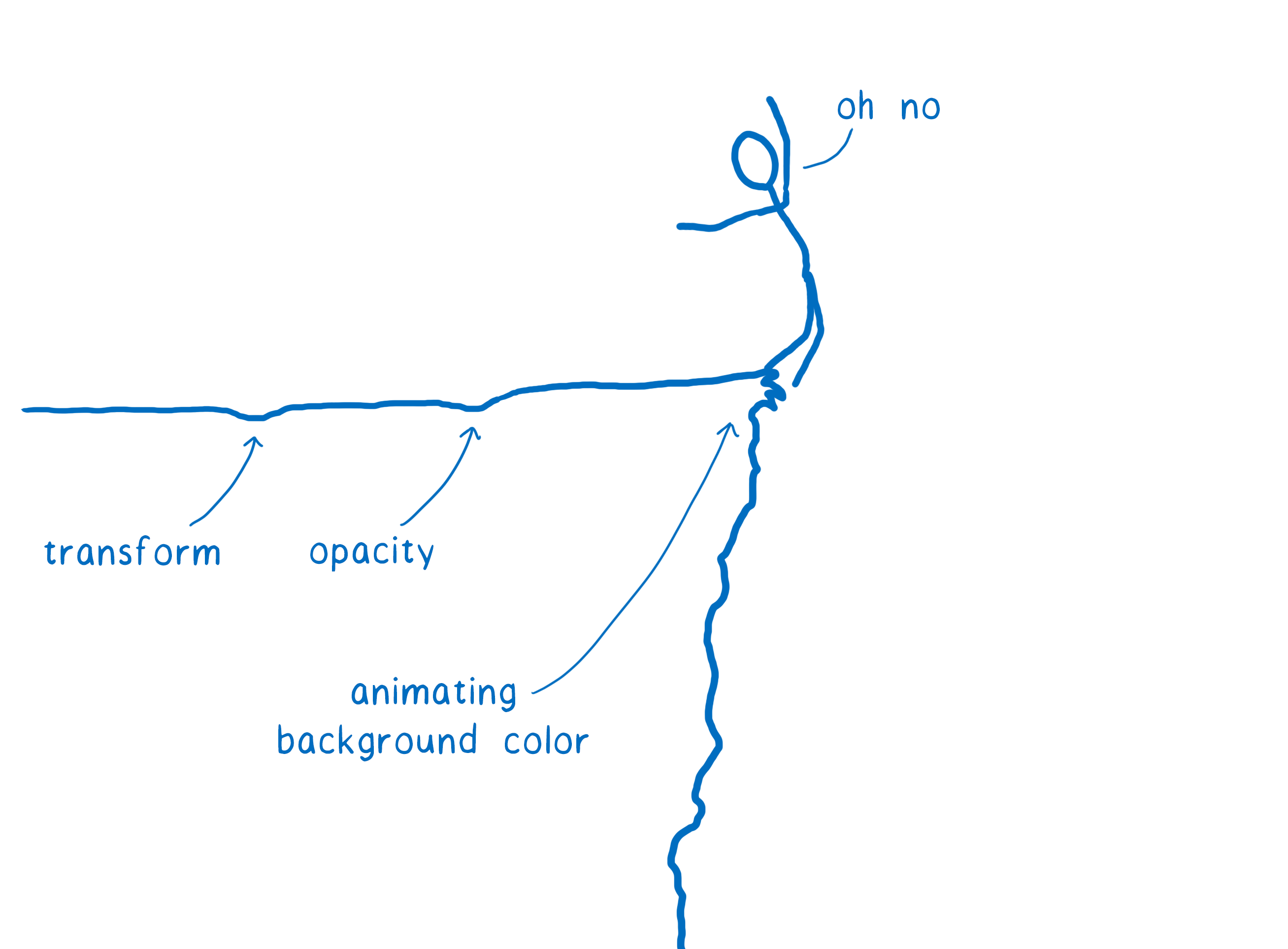
并且在许多情况下,图层并没有太大帮助。例如,如果您对背景颜色进行动画处理,则整个图层都必须重新绘制。这些图层仅对少数 CSS 属性有帮助。
即使您的大多数帧都是最佳情况场景(也就是说,它们只占帧预算的一小部分),您仍然会遇到不流畅的运动。对于可感知的卡顿,只需要几个帧出现最坏情况场景。

这些场景被称为性能悬崖。您的应用似乎正在正常运行,直到遇到其中一个最坏情况场景(例如对背景颜色进行动画处理),突然您的应用帧速率就会跌落悬崖。
但是我们可以摆脱这些性能悬崖。
我们该怎么做呢?我们遵循 3D 游戏引擎的领导。
像游戏引擎一样使用 GPU
如果我们停止尝试猜测我们需要哪些图层呢?如果我们消除了绘制和合成之间的边界,只是回到在每一帧上绘制每个像素呢?
这听起来可能很荒谬,但实际上有一定的先例。现代视频游戏重新绘制每个像素,并且它们比浏览器更可靠地保持 60 帧每秒。而且它们以一种意想不到的方式做到这一点……而不是创建这些失效矩形和图层以最大限度地减少需要绘制的内容,它们只是重新绘制整个屏幕。
像那样渲染网页会慢得多吗?
如果我们在 CPU 上绘制,那将是。但 GPU 是为这项工作而设计的。
GPU 是为极端并行性而构建的。我在关于 Stylo 的上一篇文章中谈到了并行性。通过并行性,机器可以同时做多件事。它一次可以做的事情数量受其拥有的核心数量限制。
CPU 通常有 2 到 8 个核心。GPU 通常至少有数百个核心,通常超过 1000 个核心。
不过,这些核心的工作方式略有不同。它们不能像 CPU 核心那样完全独立地运行。相反,它们通常一起处理某些事情,在数据的不同部分上运行相同的指令。
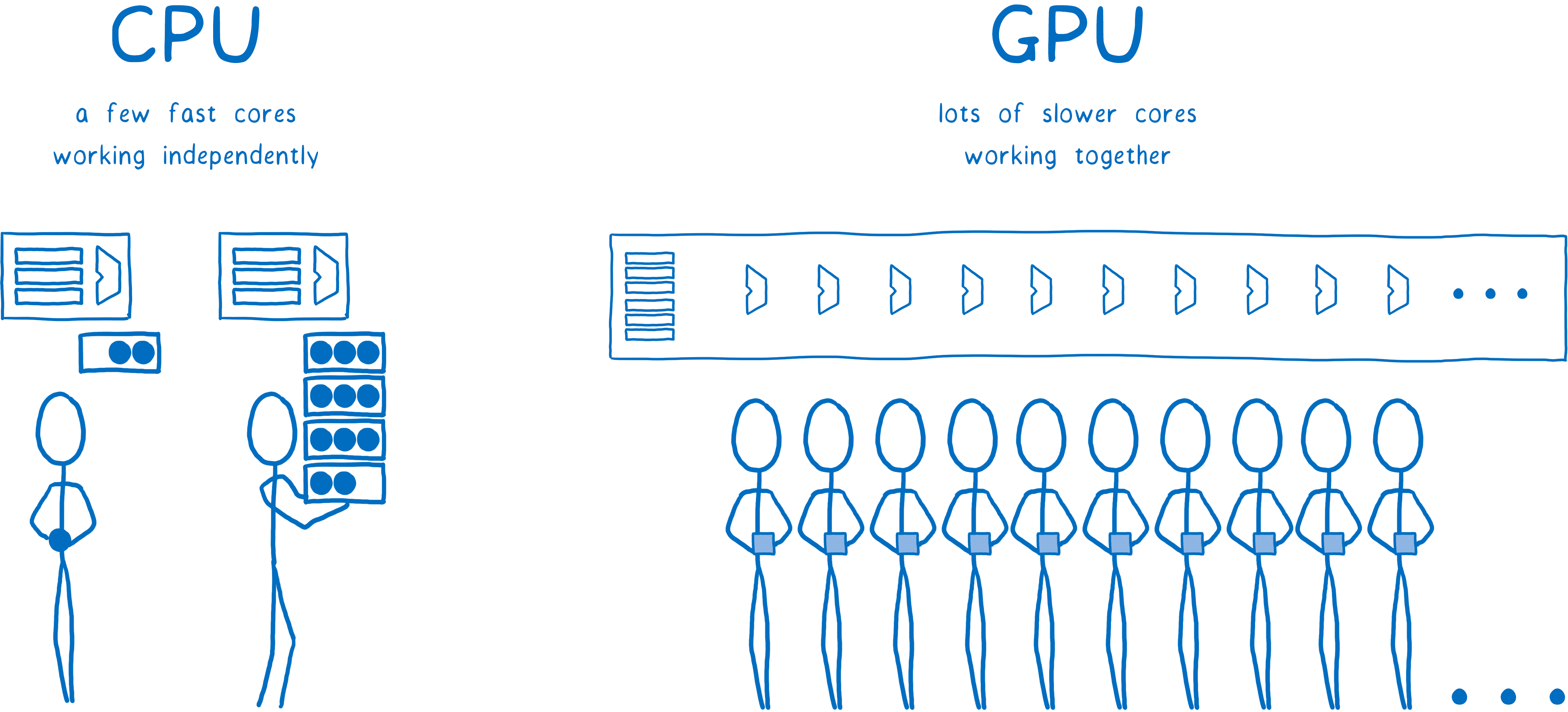
这正是您填充像素时所需要的。每个像素都可以由不同的核心填充。因为它可以一次处理数百个像素,所以 GPU 在填充像素方面比 CPU 快得多……但前提是您确保所有这些核心都有工作要做。
由于核心需要同时处理同一件事,因此 GPU 有一套非常严格的步骤要执行,并且它们的 API 受到很大限制。让我们看一下它是如何工作的。
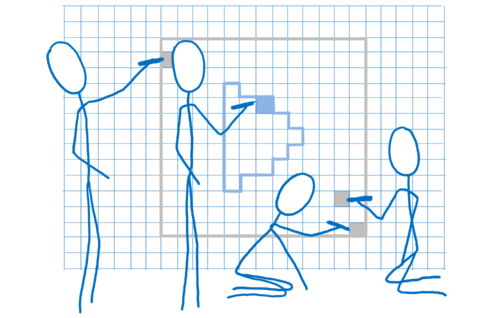
首先,您需要告诉 GPU 要绘制什么。这意味着为其提供形状并告诉它如何填充它们。
为此,您将绘制分解成简单的形状(通常是三角形)。这些形状位于 3D 空间中,因此一些形状可能在其他形状后面。然后,您将所有这些三角形的角点及其 x、y 和 z 坐标放入数组中。
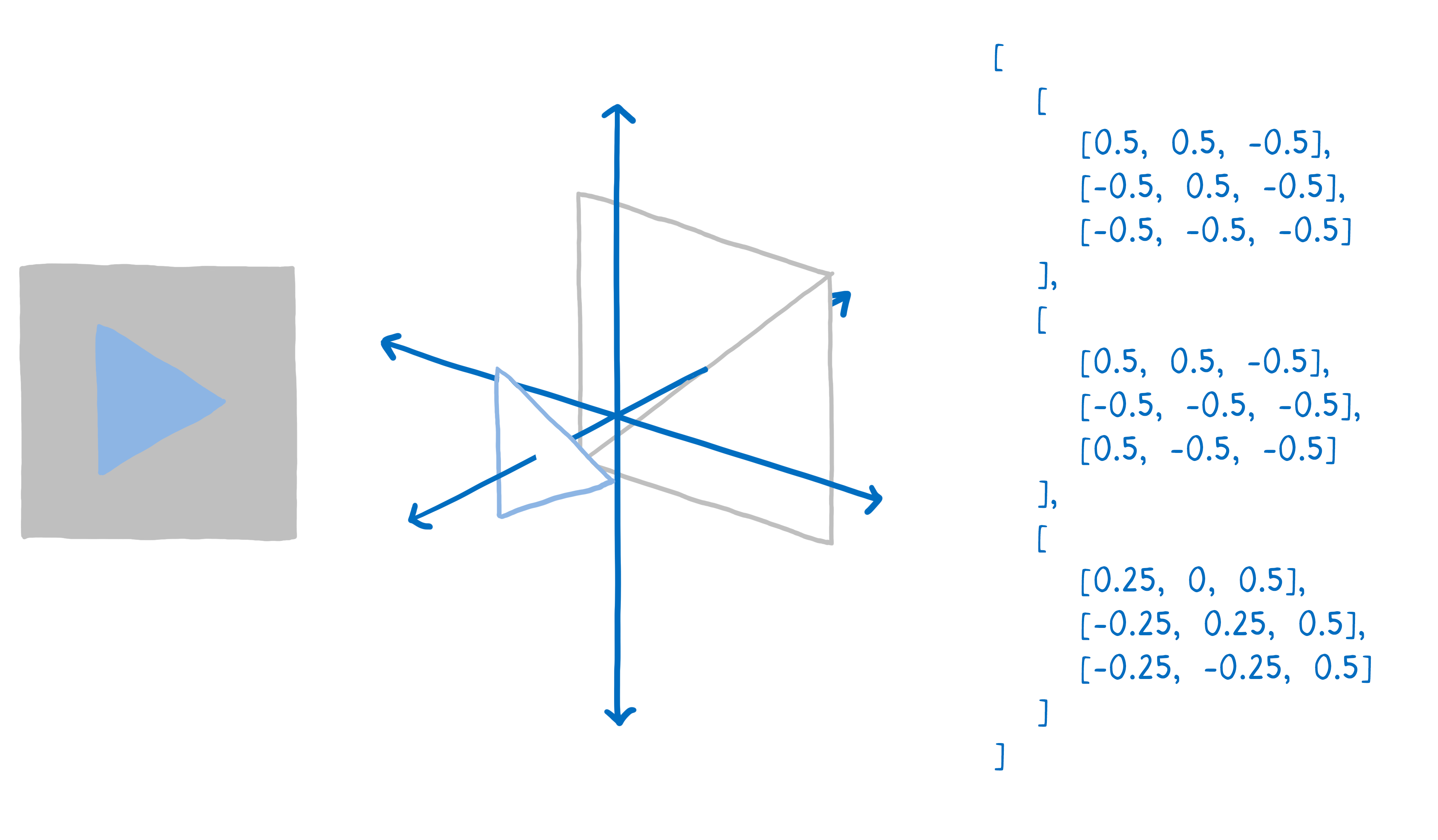
然后您发出绘制调用——您告诉 GPU 绘制这些形状。
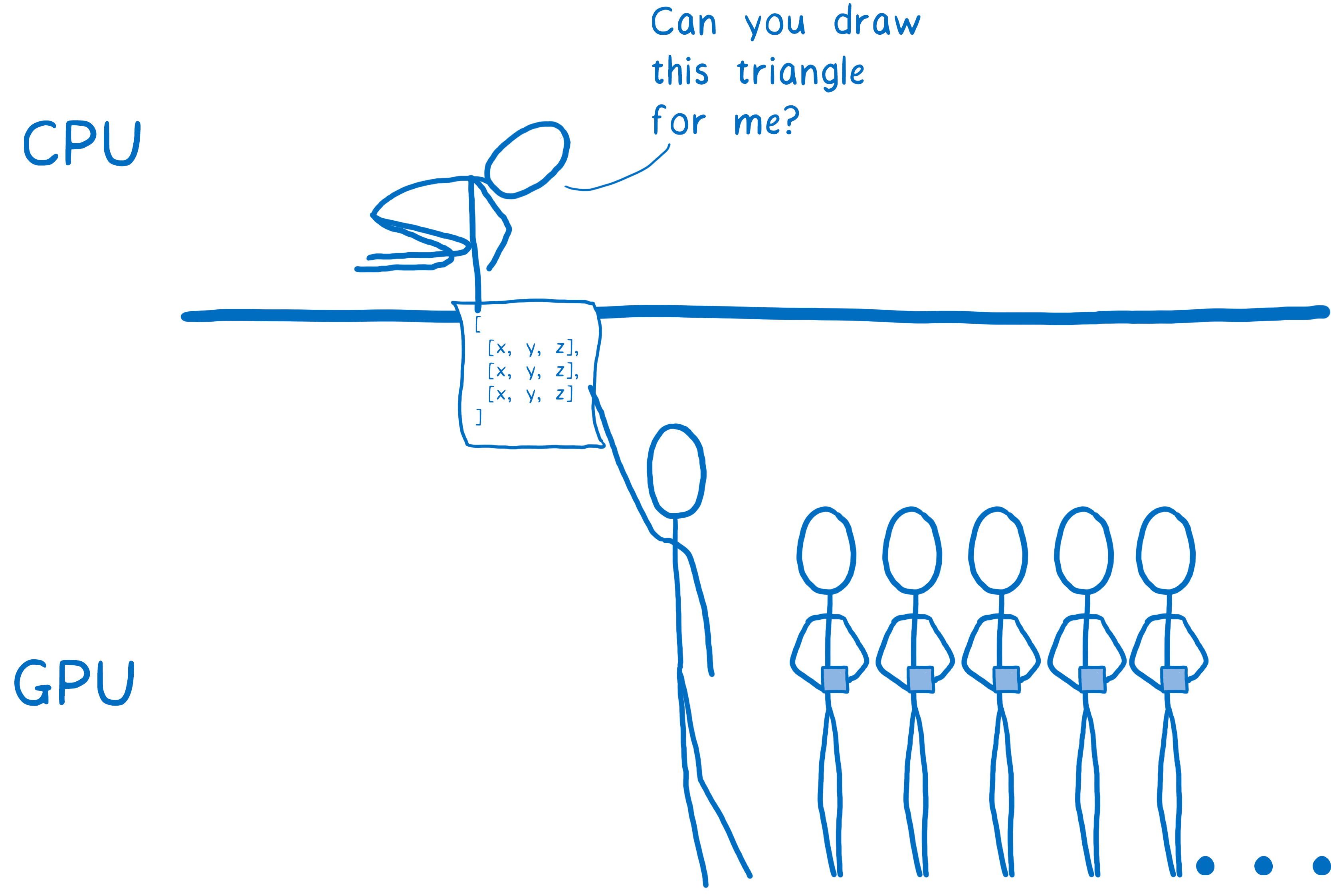
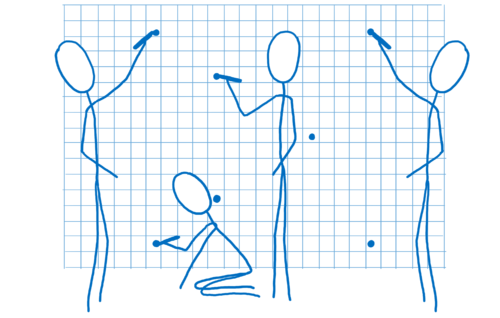
从那里开始,GPU 就接管了。所有核心将同时处理同一件事。他们将
- 找出所有形状角点的位置。这称为顶点着色。
- 找出连接这些角点的线。由此,您可以确定形状覆盖了哪些像素。这称为光栅化。
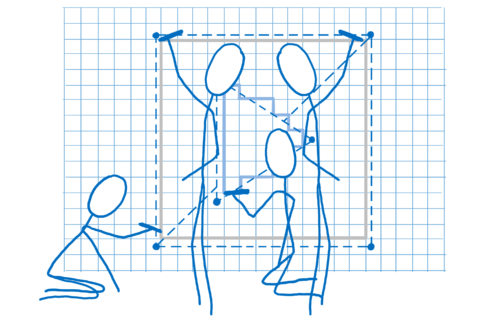
- 现在我们知道了形状覆盖了哪些像素,遍历形状中的每个像素并确定其颜色。这称为像素着色。
最后一步可以用不同的方式完成。要告诉 GPU 如何执行此操作,您需要为 GPU 提供一个称为像素着色器的程序。像素着色是您可以编程的 GPU 的少数几个部分之一。
一些像素着色器很简单。例如,如果您的形状是单色,那么您的着色器程序只需要为形状中的每个像素返回该颜色即可。
其他时候,它会更复杂,例如,当您有背景图像时。您需要确定图像的哪个部分对应于每个像素。您可以像艺术家放大或缩小图像一样执行此操作……在图像顶部放置一个网格,该网格对应于每个像素。然后,一旦您知道哪个框对应于像素,就获取该框内颜色的样本并确定颜色应该是什么。这称为纹理映射,因为它将图像(称为纹理)映射到像素。
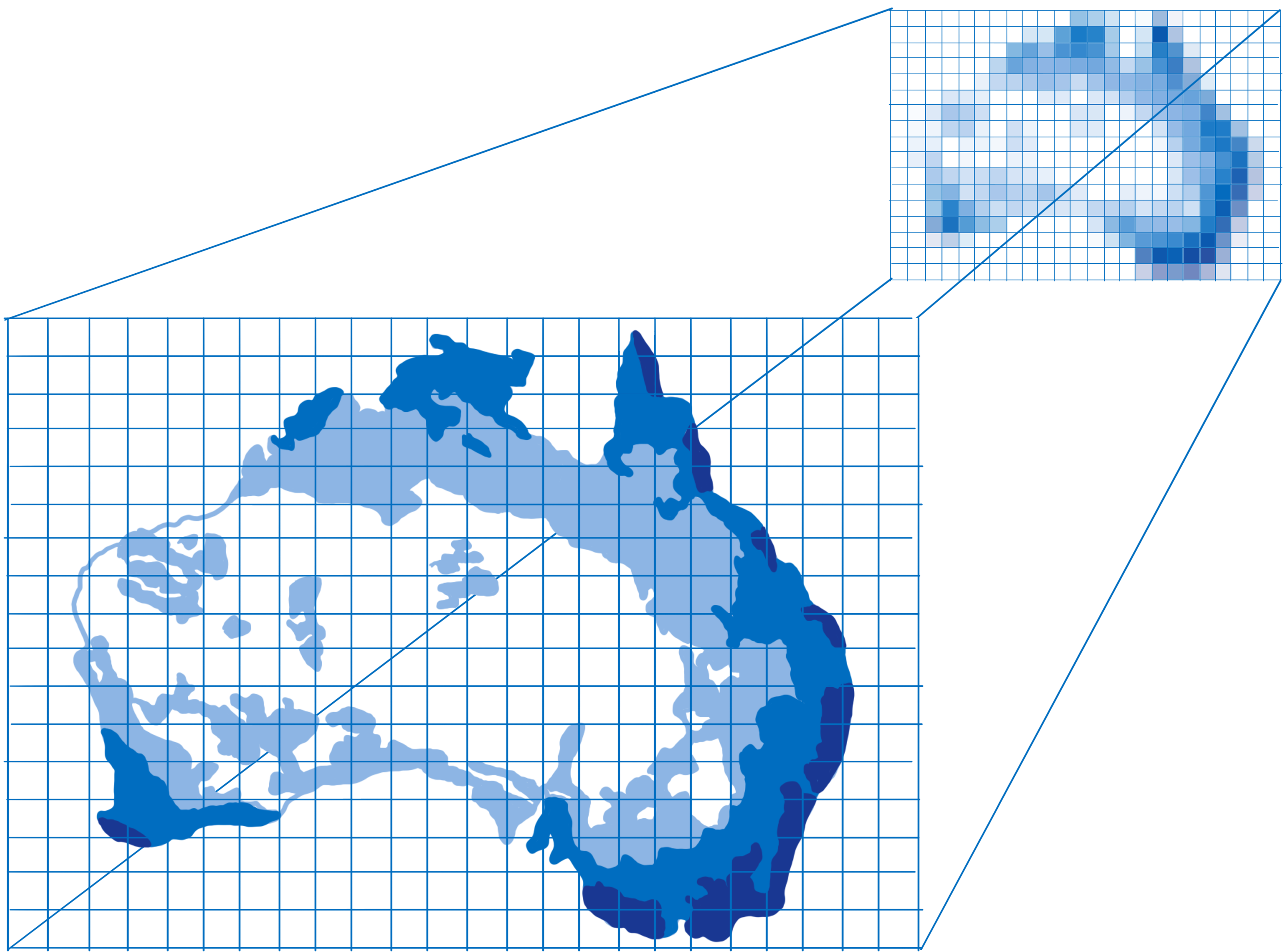
GPU 将在每个像素上调用您的像素着色器程序。不同的核心将同时并行地处理不同的像素,但它们都需要使用相同的像素着色器程序。当您告诉 GPU 绘制形状时,您告诉它使用哪个像素着色器。
对于几乎任何网页,页面的不同部分都需要使用不同的像素着色器。
由于着色器应用于绘制调用中的所有形状,因此您通常必须将绘制调用分解成多个组。这些称为批次。为了尽可能地保持所有核心忙碌,您希望创建少量批次,其中包含大量形状。
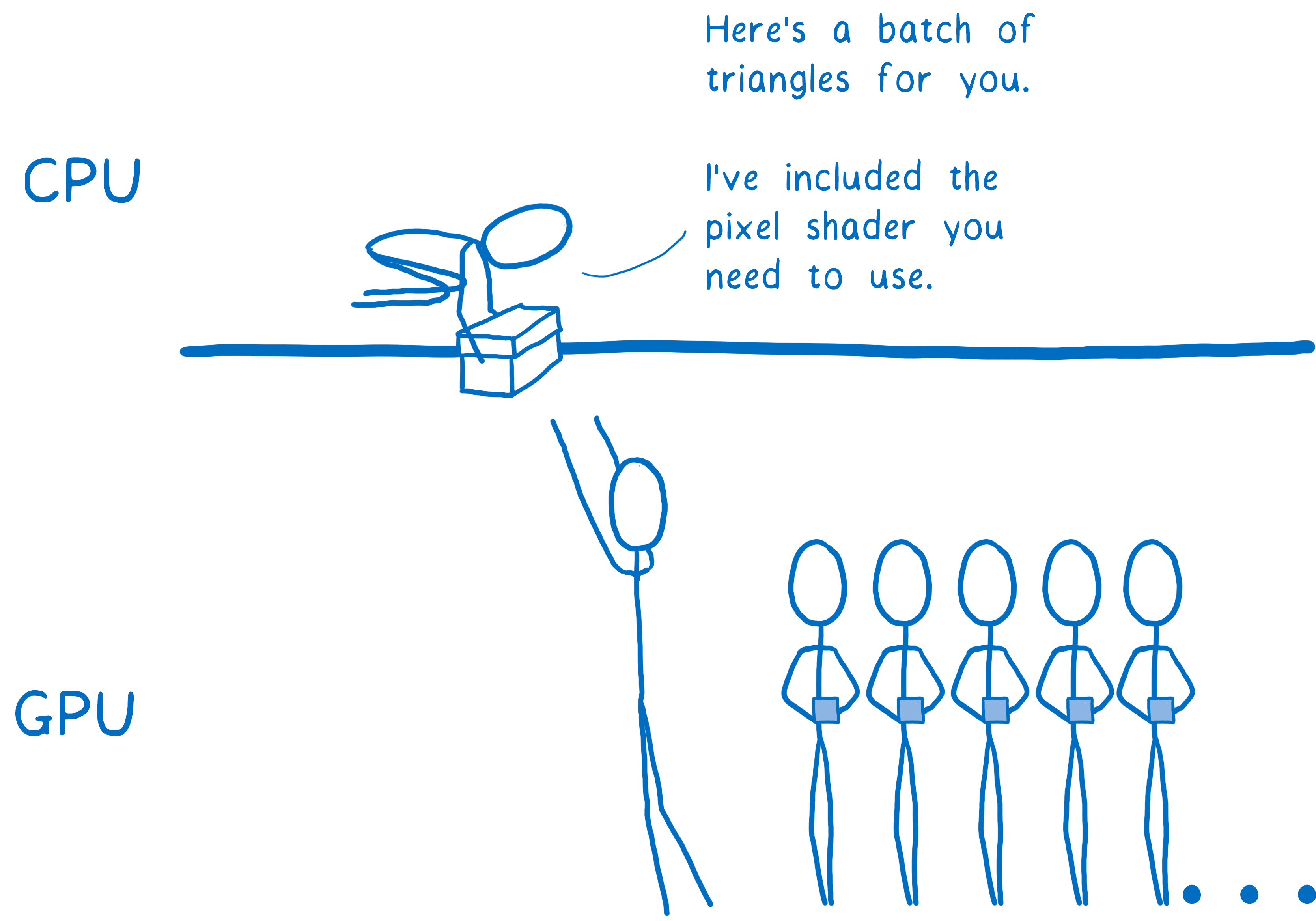
因此,这就是 GPU 如何在数百或数千个核心之间分配工作的过程。我们之所以能够考虑在每一帧上渲染所有内容,正是由于这种极端的并行性。即使有极端的并行性,但这仍然是大量工作。您仍然需要对如何执行此操作进行明智的处理。这就是 WebRender 的作用所在……
WebRender 如何与 GPU 协同工作
让我们回顾一下浏览器渲染页面的步骤。这里有两点将发生变化。
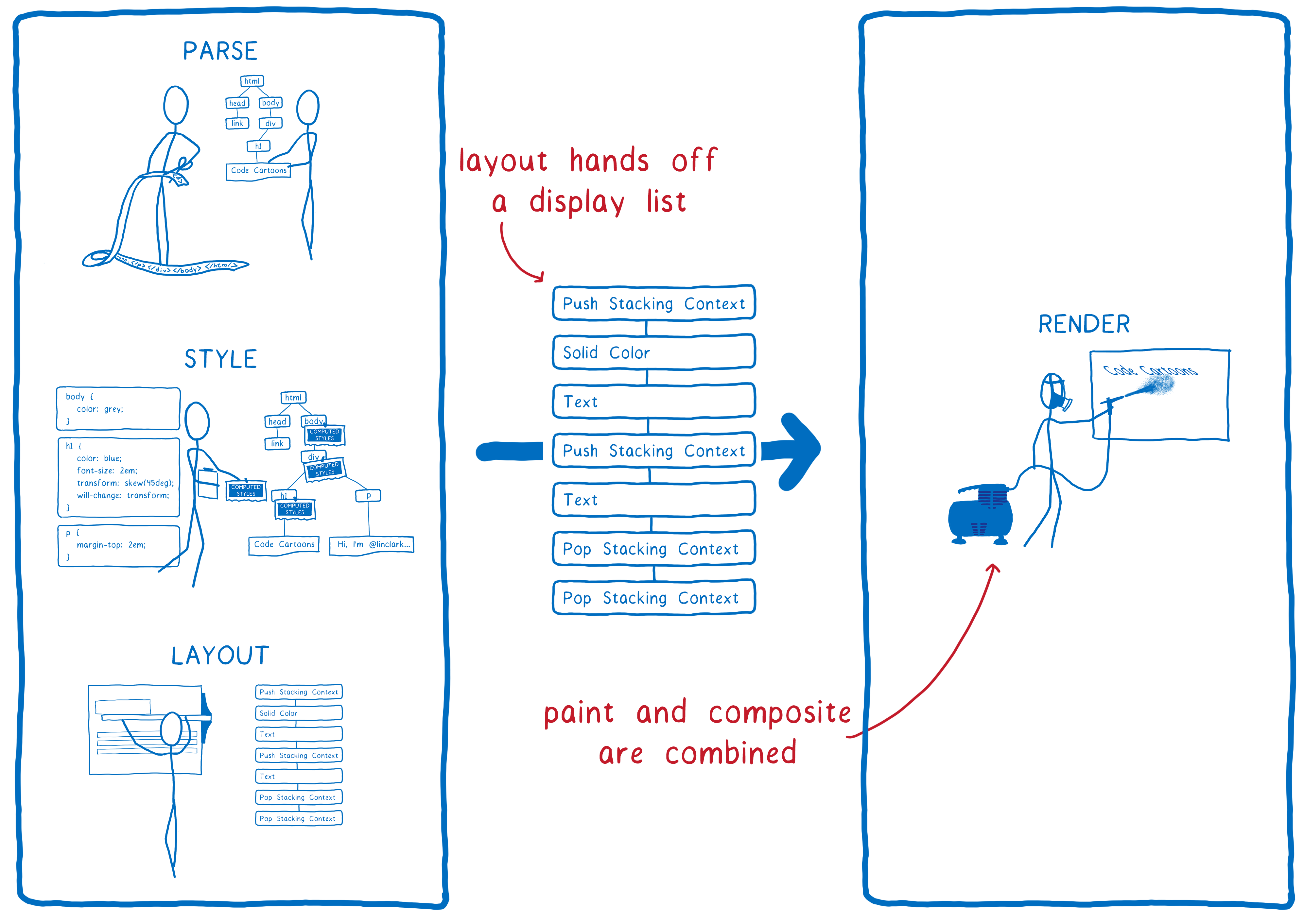
- 现在,绘画和合成之间不再有区别……它们都是同一个步骤的一部分。GPU 根据传递给它的图形 API 命令同时执行它们。
- 布局现在为我们提供了不同的数据结构来渲染。以前,它被称为帧树(或 Chrome 中的渲染树)。现在,它传递了一个显示列表。
显示列表是一组高级绘图指令。它告诉我们需要绘制什么,而不特定于任何图形 API。
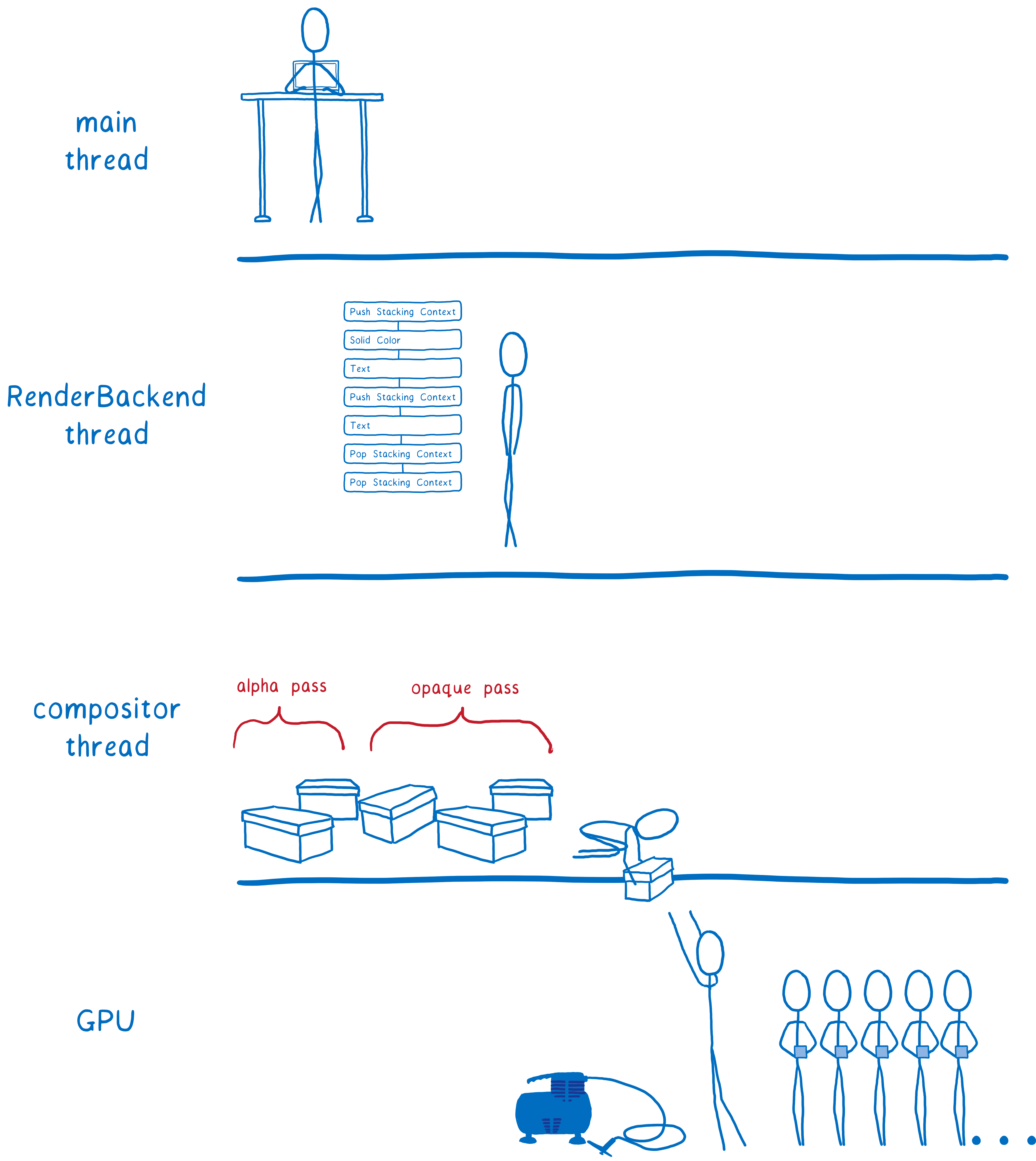
每当有新的东西要绘制时,主线程都会将该显示列表传递给 RenderBackend,RenderBackend 是在 CPU 上运行的 WebRender 代码。
RenderBackend 的工作是将此高级绘图指令列表转换为 GPU 所需的绘制调用,这些调用被批处理在一起以使其运行得更快。

然后,RenderBackend 将这些批处理传递给合成线程,合成线程将它们传递给 GPU。
RenderBackend 希望使其传递给 GPU 的绘制调用尽可能快地运行。它为此使用了几个不同的技术。
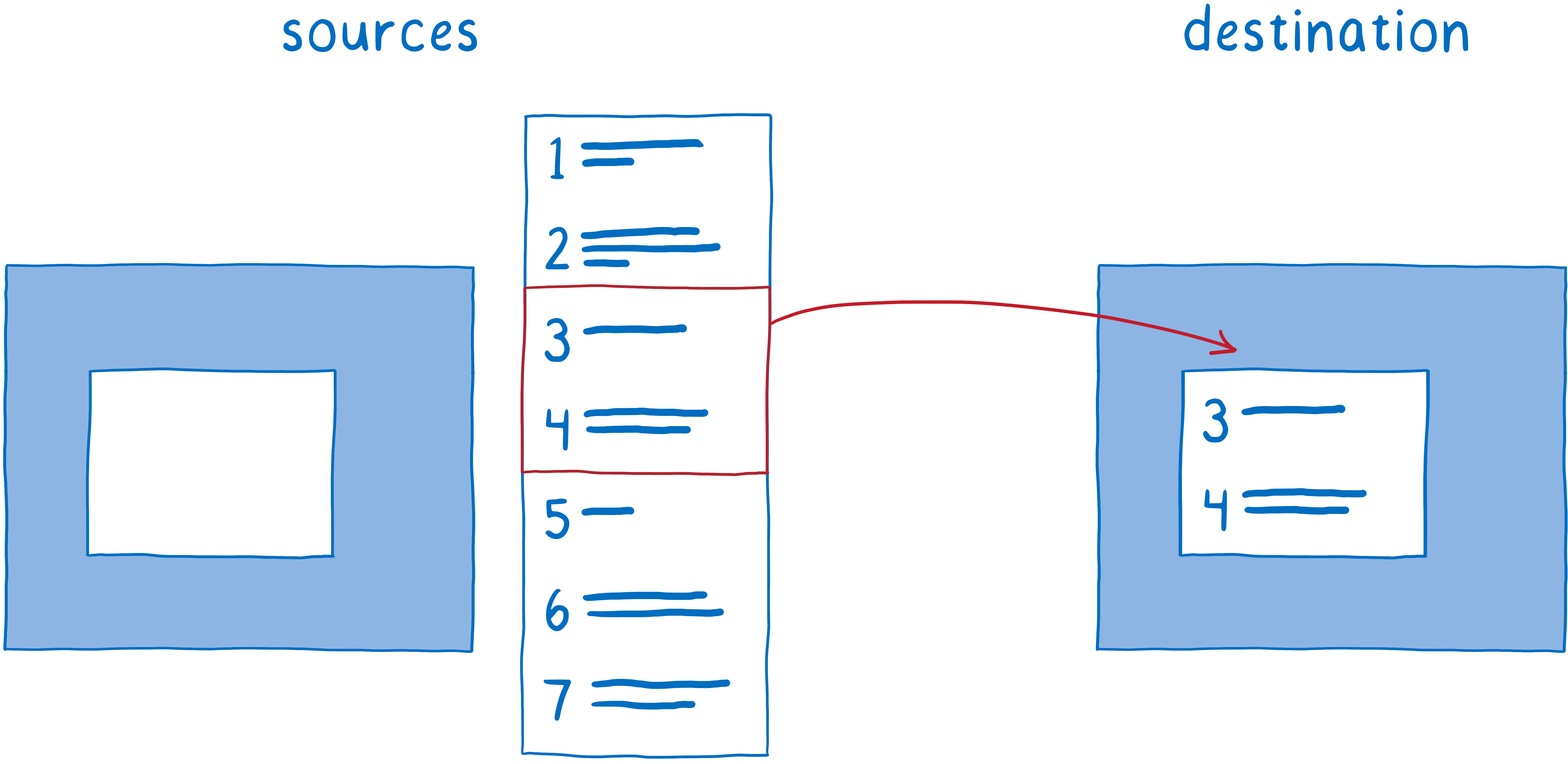
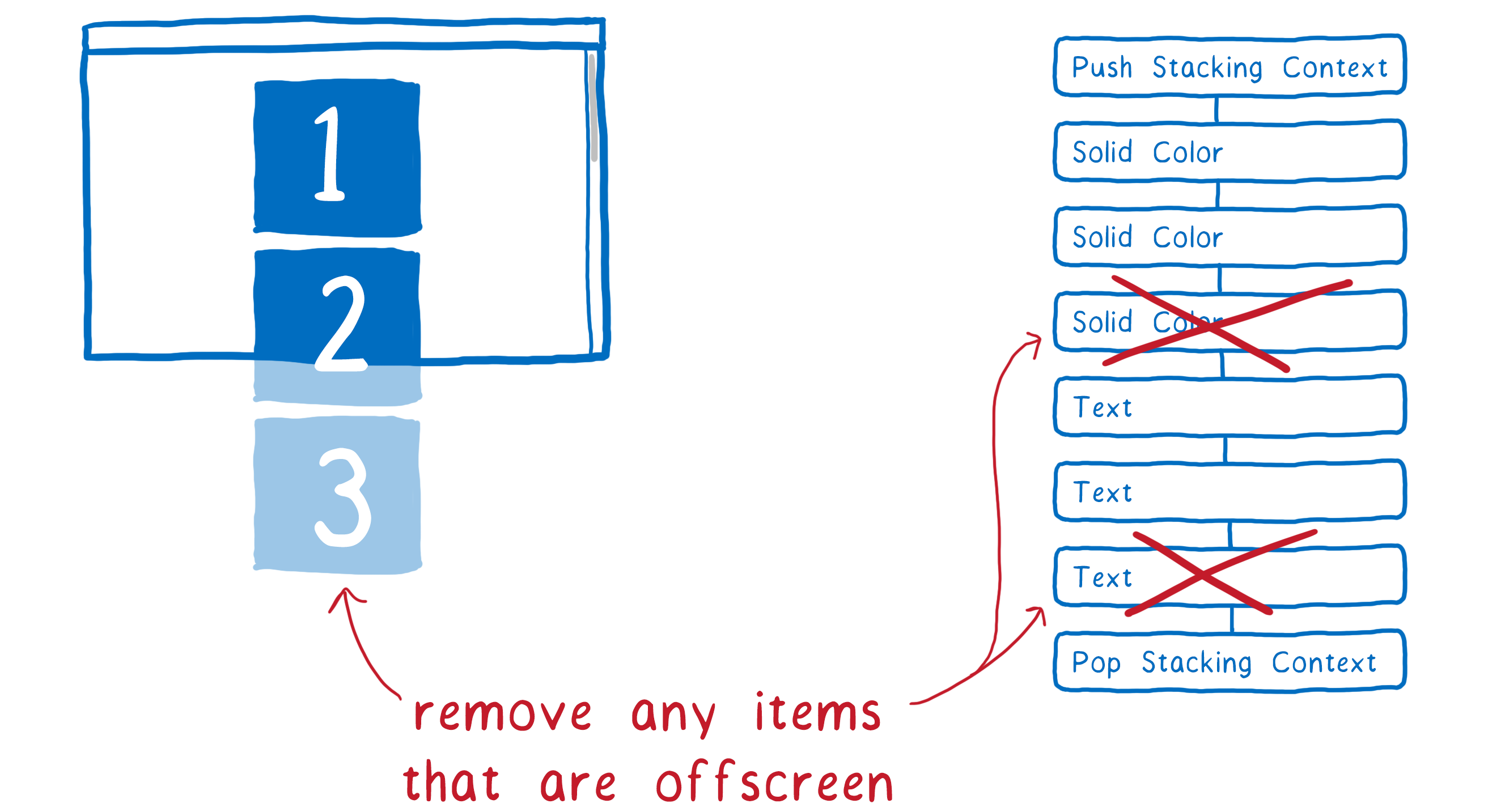
从列表中删除任何不必要的形状(早期剔除)
节省时间的最佳方法是根本不做工作。
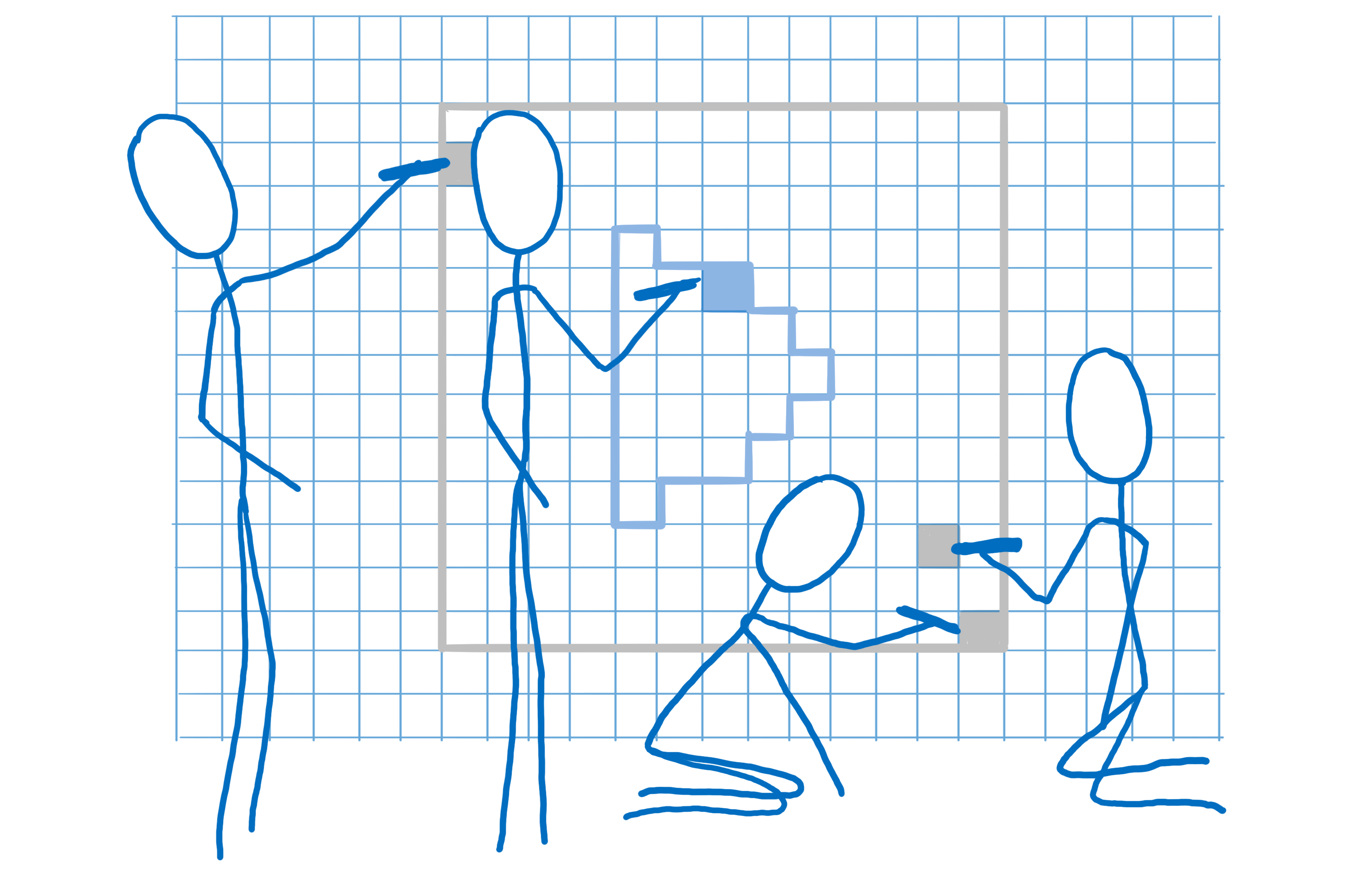
首先,RenderBackend 会减少显示项目的列表。它会找出哪些显示项目实际上会在屏幕上。为此,它会查看诸如每个滚动框的滚动距离等内容。
如果形状的任何部分都在框内,则将其包括在内。但是,如果形状的任何部分都没有显示在页面上,则将其删除。此过程称为早期剔除。
最小化中间纹理的数量(渲染任务树)
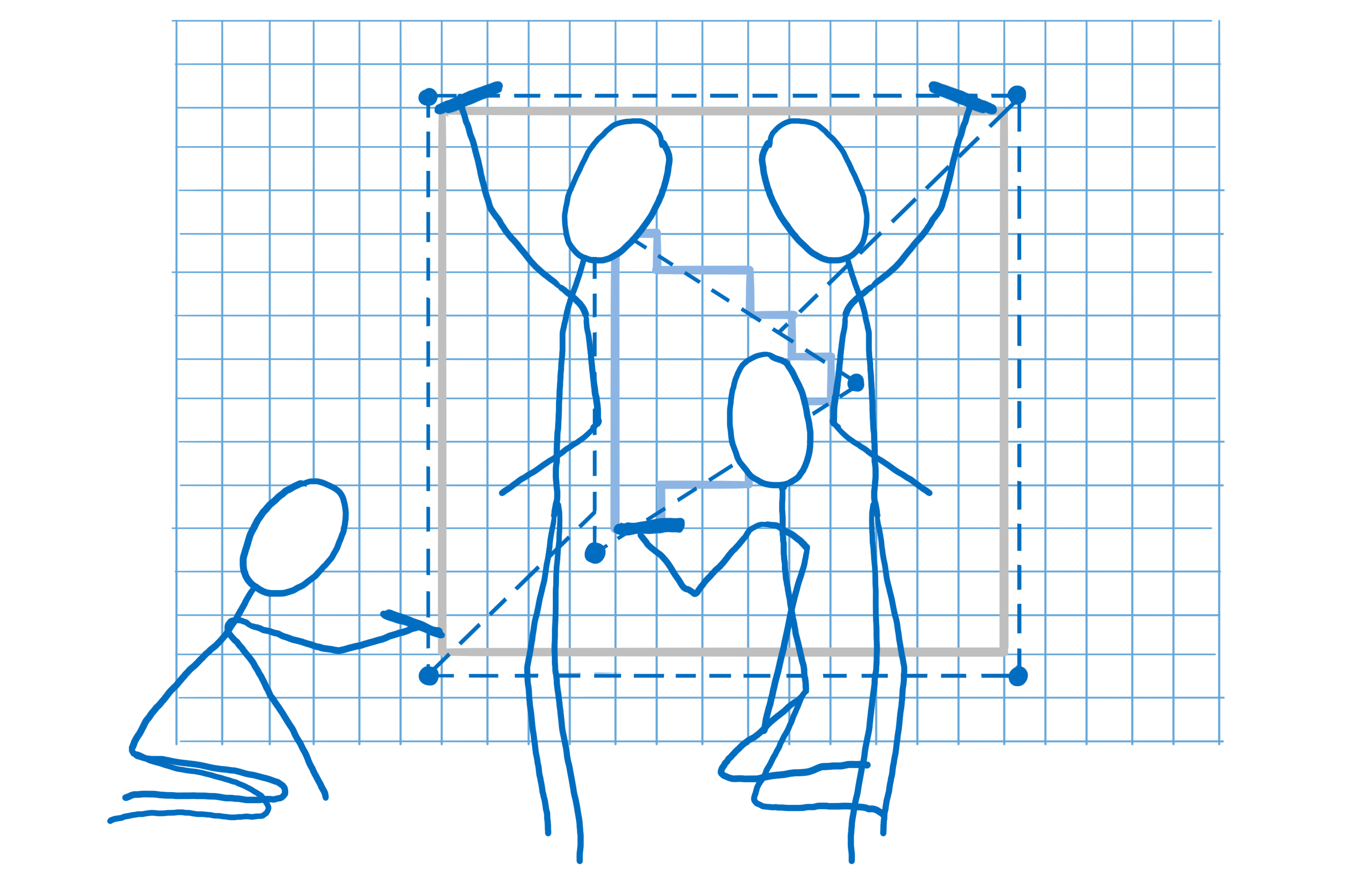
现在我们有一棵树,它只包含我们将使用的形状。这棵树被组织成我们之前讨论过的那些堆叠上下文。
诸如 CSS 滤镜和堆叠上下文之类的效果使事情变得有点复杂。例如,假设你有一个不透明度为 0.5 的元素,它有子元素。你可能会认为每个子元素都是透明的……但实际上是整个组都是透明的。
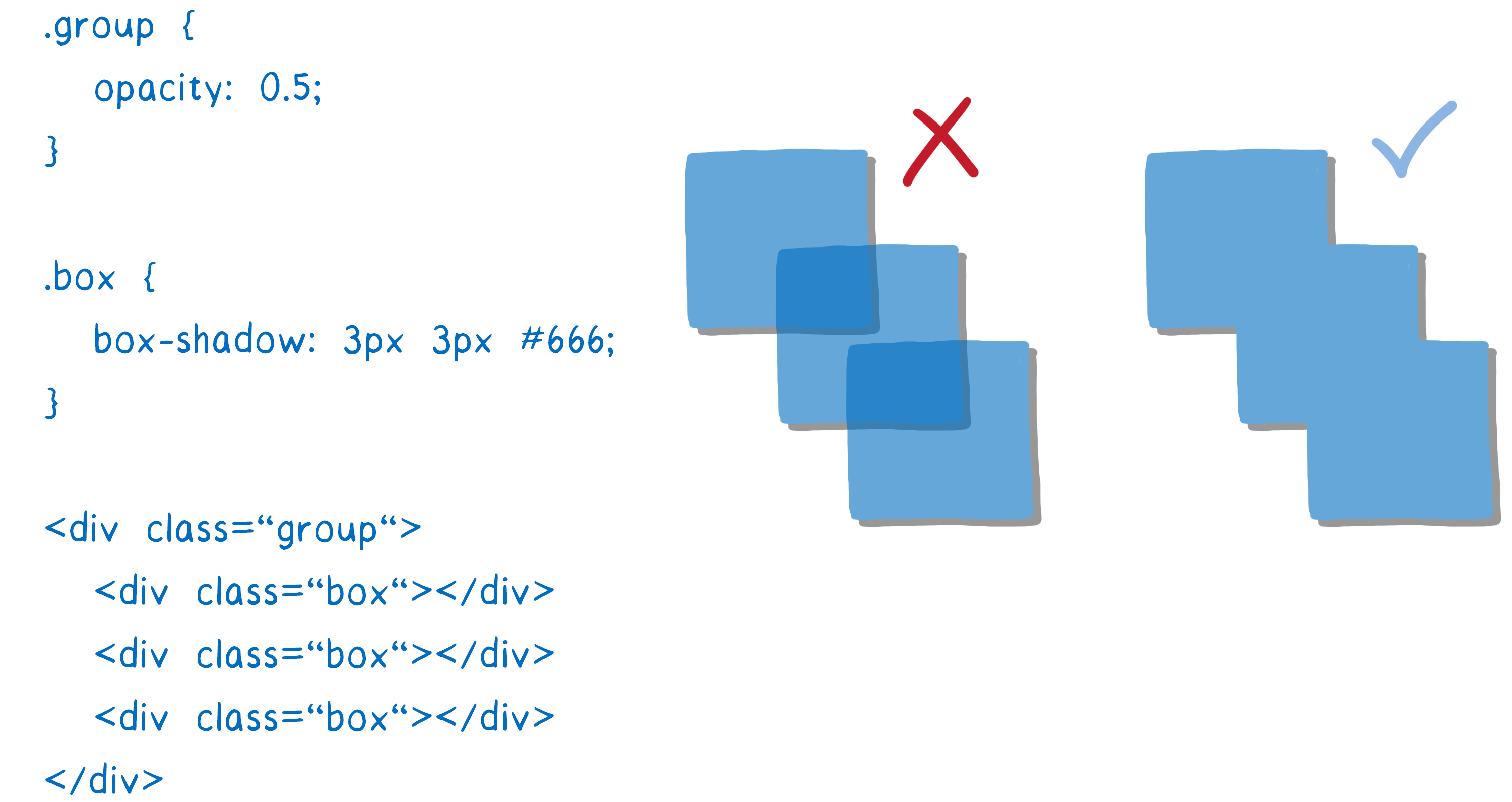
因此,你需要先将该组渲染到纹理中,每个框都具有完全不透明度。然后,当你将其放置在父元素中时,你可以更改整个纹理的不透明度。
这些堆叠上下文可以嵌套……该父元素可能是另一个堆叠上下文的一部分。这意味着它必须渲染到另一个中间纹理中,依此类推。
为这些纹理创建空间很昂贵。我们尽可能地将它们分组到同一个中间纹理中。
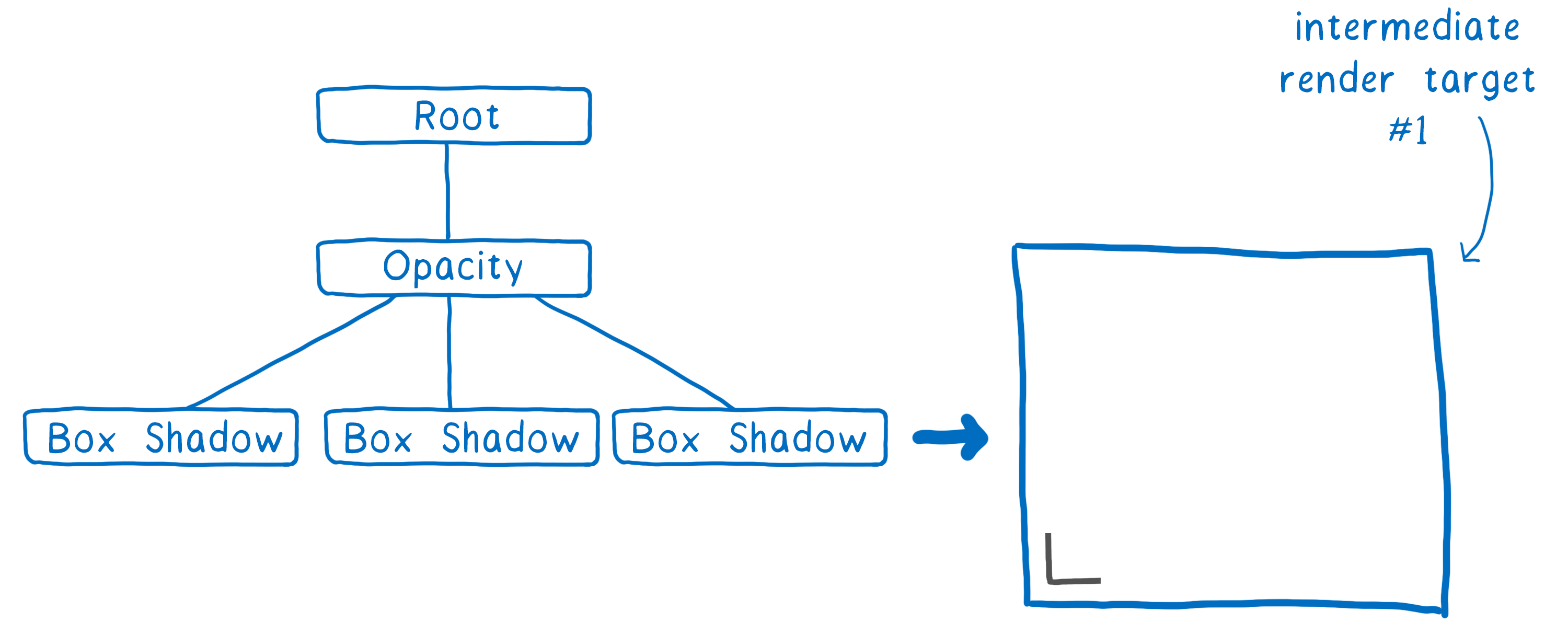
为了帮助 GPU 执行此操作,我们创建了一个渲染任务树。有了它,我们就知道哪些纹理需要在其他纹理之前创建。任何不依赖于其他纹理的纹理都可以在第一遍中创建,这意味着它们可以分组到同一个中间纹理中。
因此,在上面的示例中,我们首先进行一遍以输出方框阴影的一个角。(它比这稍微复杂一点,但这是要点。)
在第二遍中,我们可以将此角镜像到方框周围以将方框阴影放置在方框上。然后我们可以以完全不透明度渲染出该组。
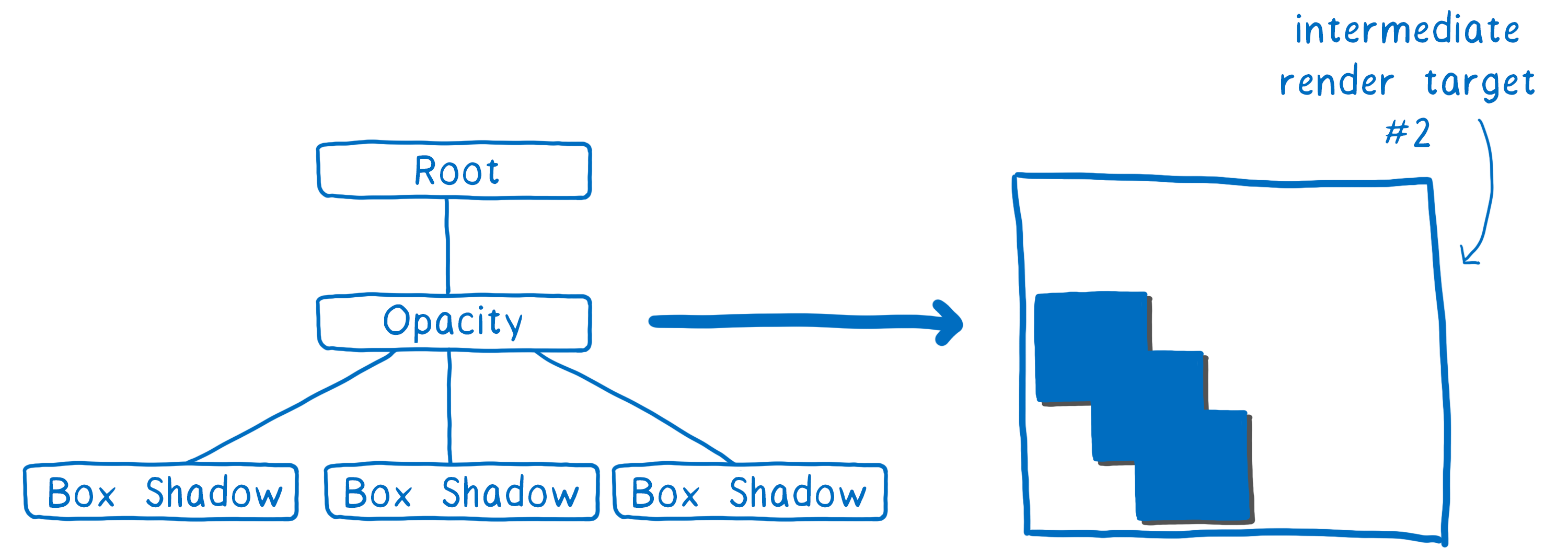
接下来,我们只需更改此纹理的不透明度,并将其放置在它需要在最终输出到屏幕的纹理中的位置。

通过构建此渲染任务树,我们找出了我们可以使用的最少数量的离屏渲染目标。这是件好事,因为正如我提到的,为这些渲染目标纹理创建空间很昂贵。
它还有助于我们将它们批处理在一起。
将绘制调用分组在一起(批处理)
正如我们之前讨论过的,我们需要创建少量批次,这些批次包含大量形状。
关注你创建批次的方式确实可以加快速度。你希望在一个批次中尽可能多地包含形状。这是因为几个原因。
首先,每当 CPU 告诉 GPU 执行绘制调用时,CPU 都必须执行大量工作。它必须执行诸如设置 GPU、上传着色器程序和测试不同的硬件错误等操作。这项工作加起来,并且在 CPU 执行这项工作时,GPU 可能会处于空闲状态。
其次,更改状态会产生成本。假设你需要在批次之间更改着色器程序。在典型的 GPU 上,你需要等待所有核心完成当前着色器。这称为清空管道。在管道清空之前,其他核心将处于空闲状态。

因此,你希望尽可能地进行批处理。对于典型的台式 PC,你希望每帧有 100 个或更少的绘制调用,并且希望每个调用有数千个顶点。这样,你就可以充分利用并行性。
我们查看渲染任务树中的每一遍,并找出我们可以批处理在一起的内容。
目前,每种不同类型的基元都需要不同的着色器。例如,有一个边框着色器、一个文本着色器和一个图像着色器。
我们相信我们可以组合许多这些着色器,这将使我们能够拥有更大的批次,但这已经相当不错了。
我们几乎准备将其发送给 GPU。但是我们还可以消除更多工作。
使用不透明和 alpha 通道减少像素着色(Z 剔除)
大多数网页都有大量形状相互重叠。例如,一个文本字段位于一个 div(带背景)之上,该 div 位于主体(带另一个背景)之上。
在计算像素颜色时,GPU 可以计算出每个形状中像素的颜色。但是只有顶层会显示。这称为过度绘制,它会浪费 GPU 时间。
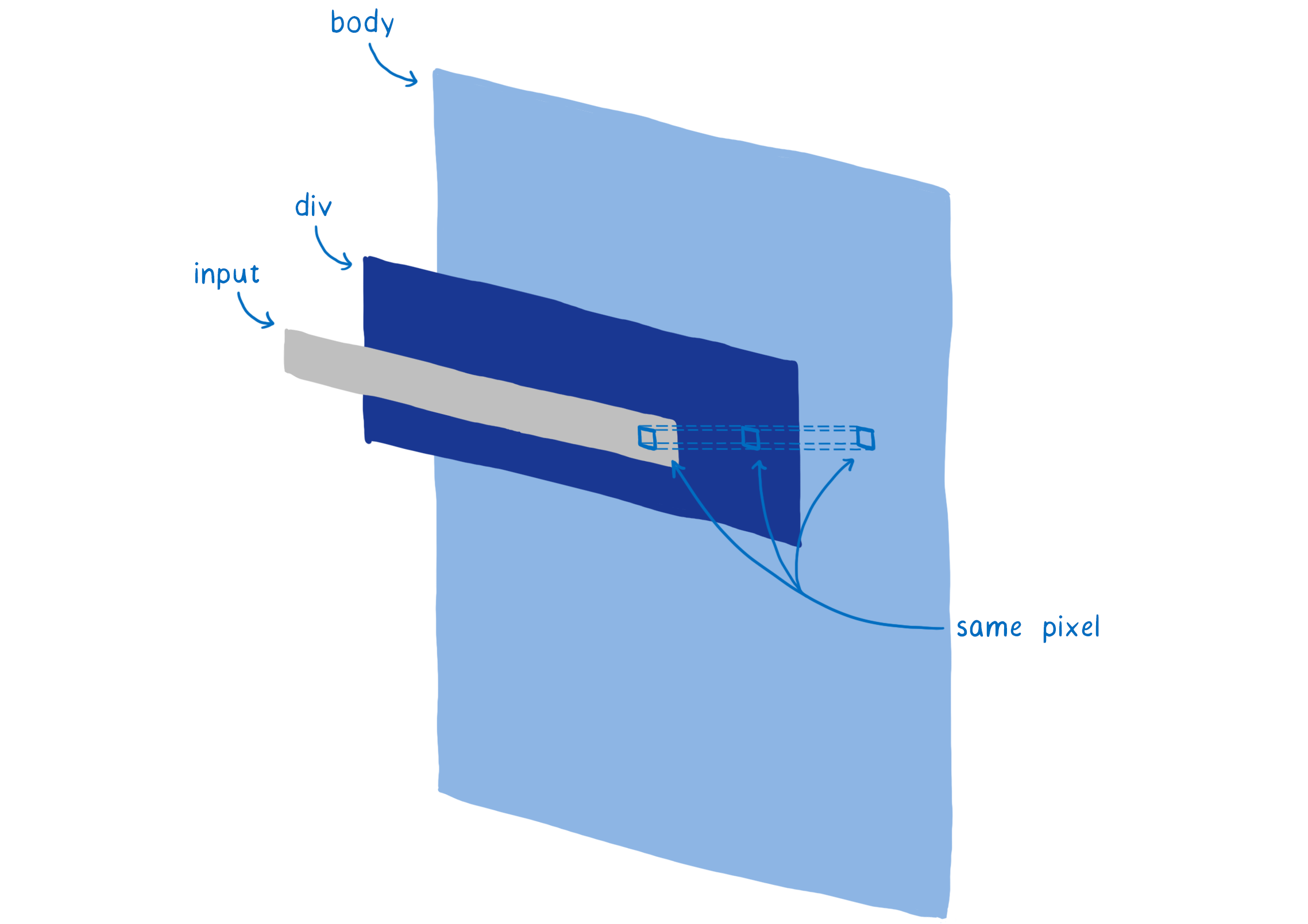
因此,你可以执行的操作之一是先渲染顶层形状。对于下一个形状,当你到达同一个像素时,检查它是否已经有值。如果有,则不要执行工作。

但是,这方面存在一个小问题。每当一个形状是半透明的时,你需要混合两个形状的颜色。为了使它看起来正确,这需要从后到前进行。
所以我们所做的是将工作分成两遍。首先,我们执行不透明通道。我们从前往后绘制所有不透明形状。我们跳过位于其他形状后面的任何像素。
然后,我们执行半透明形状。这些是从后到前绘制的。如果一个半透明像素位于一个不透明像素之上,则将其混合到不透明像素中。如果它会落在不透明形状后面,则不会进行计算。
此过程将工作分为不透明和 alpha 通道,然后跳过不需要的像素计算,称为 Z 剔除。
虽然它看起来可能是一个简单的优化,但它为我们带来了巨大的收益。在典型的网页上,它大大减少了我们需要触碰的像素数量,我们目前正在研究将更多工作转移到不透明通道的方法。
此时,我们已经准备好了帧。我们已经尽力减少工作量。
……我们准备好了绘制!
我们准备好了设置 GPU 并渲染我们的批次。
注意:并非所有内容都已在 GPU 上
CPU 仍然必须执行一些绘制工作。例如,我们仍然在 CPU 上渲染用于文本块中的字符(称为字形)。可以在 GPU 上执行此操作,但很难与计算机在其他应用程序中渲染的字形完全匹配。因此,人们可能会发现看到 GPU 渲染的字体会让人感到困惑。我们正在尝试使用 Pathfinder 项目 将字形之类的内容转移到 GPU 上。
目前,这些东西被绘制到 CPU 上的位图中。然后,它们被上传到 GPU 上称为纹理缓存的内容中。此缓存会从一帧保存到下一帧,因为它们通常不会改变。
即使此绘制工作仍然在 CPU 上进行,我们仍然可以使其比现在更快。例如,当我们绘制字体中的字符时,我们会在所有核心之间拆分不同的字符。我们使用与 Stylo 用于并行化样式计算的相同技术来执行此操作…… 工作窃取。
WebRender 的下一步是什么?
我们期待在 2018 年将 WebRender 作为 Quantum Render 的一部分落地到 Firefox 中,这将在最初的 Firefox Quantum 发布后的几个版本中实现。这将使今天网页运行得更加流畅。它还使 Firefox 为新一代高分辨率 4K 显示器做好了准备,因为随着屏幕上像素数量的增加,渲染性能变得更加关键。
但是 WebRender 不仅对 Firefox 有用。它也是我们对 WebVR 所做工作的关键,在 WebVR 中,你需要以 4K 分辨率和 90 FPS 的速度为每只眼睛渲染不同的帧。
WebRender 的早期版本目前可在 Firefox 中使用一个标志进行访问。集成工作仍在进行中,因此性能目前不如完成后的性能好。如果你想了解 WebRender 的开发,你可以关注 GitHub 仓库,或者关注 Twitter 上的 Firefox Nightly 以获取整个 Quantum Render 项目的每周更新。
关于 Lin Clark
Lin 在 Mozilla 的高级开发部门工作,重点关注 Rust 和 WebAssembly。
63 条评论