
在 Mozilla,我们相信语音界面将成为未来人们与设备交互的重要方式。今天,我们很高兴地宣布我们开源语音识别模型的初始版本,以便任何人都可以开发引人入胜的语音体验。
Mozilla 研究院的机器学习团队一直在开发一个开源自动语音识别引擎,该引擎模仿了百度发布的 Deep Speech 论文 (1、2)。从一开始,主要目标之一就是使转录的字词错误率低于 10%。我们已经取得了巨大进展:我们在 LibriSpeech 的 test-clean 集上的字词错误率为 6.5%,这不仅实现了我们的初始目标,而且让我们接近人类水平的表现。
这篇文章概述了团队的工作,并以对拼图的最后一块——CTC 解码器的更详细解释结束。
架构
Deep Speech 是一种端到端的可训练、字符级、深度循环神经网络 (RNN)。用更通俗的话来说,它是一个具有循环层的深度神经网络,它接收音频特征作为输入并直接输出字符——音频的转录。它可以使用从头开始的监督学习进行训练,无需任何外部“智能来源”,例如音素到音位转换器或对输入进行强制对齐。
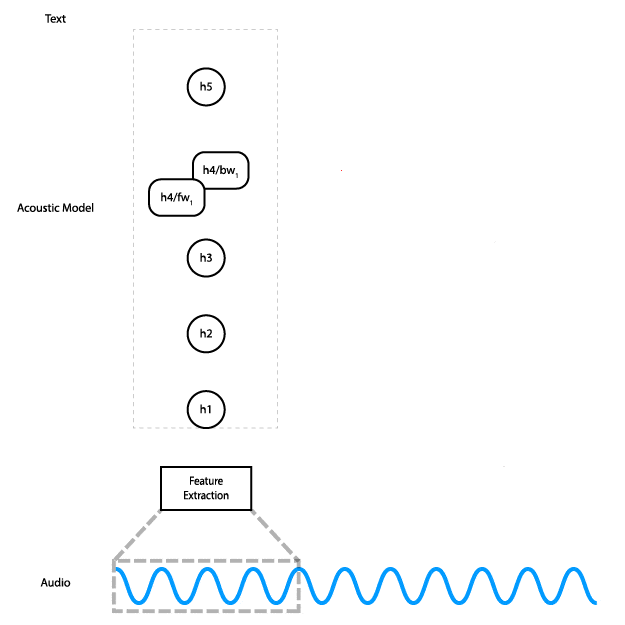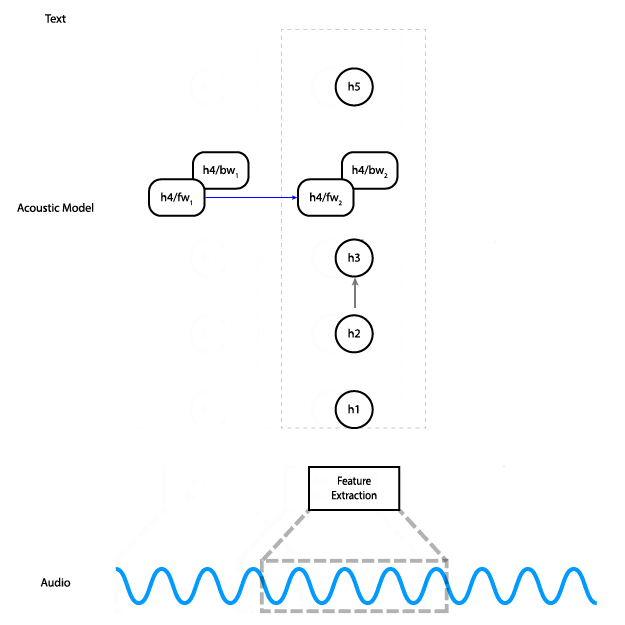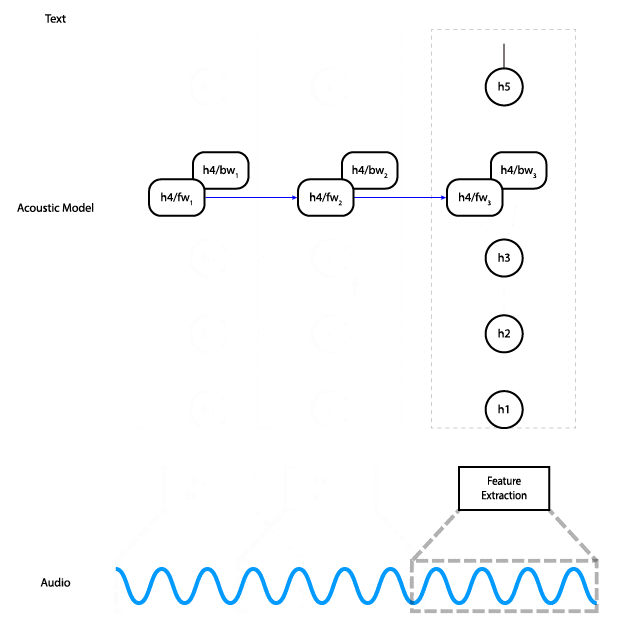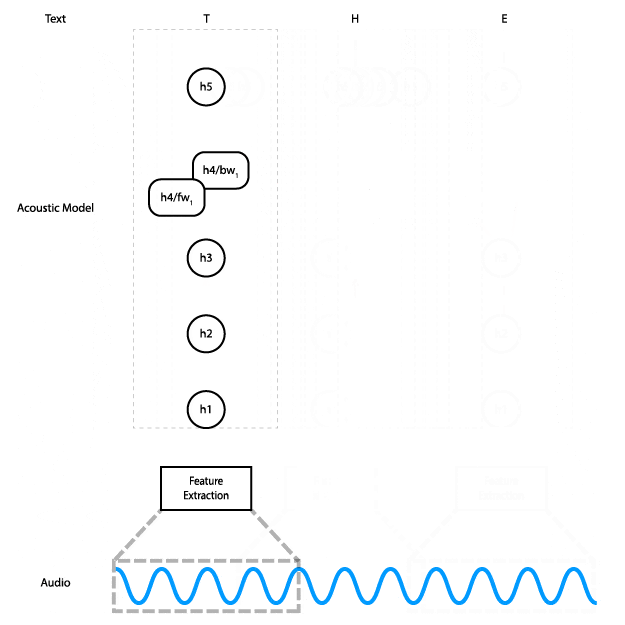
此动画展示了数据如何在网络中流动。实际上,我们不是单独处理音频输入的切片,而是同时处理所有切片。
该网络有五层:输入被馈送到三个全连接层,然后是双向 RNN 层,最后是全连接层。隐藏的全连接层使用 ReLU 激活。RNN 层使用具有 tanh 激活的 LSTM 单元。
网络的输出是随时间推移的字符概率矩阵。换句话说,对于每个时间步,网络都会为字母表中的每个字符输出一个概率,它代表该字符对应于音频中此时所说内容的可能性。 CTC 损失函数 (PDF 链接) 同时考虑了音频与转录的所有对齐方式,使我们能够最大程度地提高预测正确转录的概率,而无需担心对齐。最后,我们使用 Adam 优化器 进行训练。
数据
监督学习需要数据,大量数据。训练像 Deep Speech 这样的模型需要数千小时的标记音频,获取和准备这些数据的工作量可能与实现网络和训练逻辑一样多,甚至更多。
我们首先下载了免费提供的语音语料库,例如 TED-LIUM 和 LibriSpeech,,以及获取了付费语料库,例如 Fisher 和 Switchboard。我们用 Python 为不同的数据集编写了导入器,这些导入器将音频文件转换为 WAV,分割音频并清理掉不必要的字符,例如标点符号和重音符号。最后,我们将预处理后的数据存储在 CSV 文件中,这些文件可用于将数据馈送到网络。
使用现有的语音语料库使我们能够快速开始研究模型。但为了获得出色的结果,我们需要更多的数据。我们必须有创造力。我们认为,这种类型的语音数据可能已经存在于人们的档案中,所以我们联系了公共电视台和广播电台、大学的语言学习部门,以及任何可能拥有标记语音数据可供分享的人。通过这种努力,我们能够将训练数据量增加一倍以上,这现在足以训练一个高质量的英语模型。
拥有一个高质量的语音语料库公开可用不仅有助于推进我们自己的语音识别引擎。它最终将促进广泛的创新,因为开发人员、初创公司和世界各地的研究人员可以使用它来训练和试验针对不同语言的不同架构和模型。它可以帮助那些无力支付数千小时的训练数据(几乎所有人)的民主化深度学习。
为了构建一个免费、开源且足够大以创建有意义产品的语音语料库,我们与 Mozilla 的开放式创新团队合作,推出了 Common Voice 项目,以收集和验证来自世界各地志愿者的语音贡献。今天,该团队正在将大量语音数据发布到 公共领域。在 Open Innovation Medium 博客 上了解更多关于该版本的信息。
硬件
Deep Speech 拥有超过 1.2 亿个参数,训练如此庞大的模型是一项非常计算密集型的任务:如果你不想永远等待结果,你需要大量的 GPU。我们研究过在云端训练,但这在经济上不可行:如果你进行大量训练,专用硬件很快就能收回成本。云端是进行快速超参数探索的好方法,所以要记住这一点。
我们最初使用一台运行四个 Titan X Pascal GPU 的机器,然后又购买了两台服务器,每台服务器都配备了 8 个 Titan XP。我们将这两台 8 GPU 机器作为集群运行,较旧的 4 GPU 机器独立运行,以运行较小的实验和测试代码更改,这些更改需要比我们的开发机器更大的计算能力。这种设置相当高效,对于我们的大型训练运行,我们可以从零开始在大约一周内获得一个良好的模型。
使用 TensorFlow 设置分布式训练是一个艰巨的过程。虽然它拥有所有可用深度学习框架中最成熟的分布式训练工具,但让它真正无错误地工作并充分利用额外的计算能力却很棘手。我们目前的设置之所以能够正常工作,要归功于我的同事 Tilman Kamp 的出色努力,他忍受了与 TensorFlow、Slurm, 甚至 Linux 内核的漫长战斗,直到我们让一切都正常运行。
将所有内容整合在一起
此时,我们有两篇论文来指导我们,一个基于这些论文实现的模型,以及由此产生的数据和训练过程所需的硬件。事实证明,复制一篇论文的结果并不那么简单。绝大多数论文都没有指定它们使用的所有超参数,如果它们确实指定了,也只是指定了一部分。这意味着你必须花费大量的时间和精力进行超参数搜索,才能找到一套好的值。我们最初使用随机和直觉混合选择的测试值,甚至与论文中报道的值相差甚远,可能是由于架构上的细微差异——例如,我们使用了 LSTM (长短期记忆) 单元,而不是 GRU (门控循环单元) 单元。我们花了大量时间对 dropout 比例进行二进制搜索,降低了学习率,改变了权重初始化的方式,还尝试了不同的隐藏层大小。所有这些更改都让我们非常接近我们想要的低于 10% 字词错误率的目标,但还没有达到。
我们的代码中缺少一个重要的优化:将我们的语言模型集成到解码器中。CTC (连接主义时间分类) 解码器的工作原理是,获取模型输出的概率矩阵,并遍历它,根据概率矩阵寻找最有可能的文本序列。如果在时间步长 0 时,字母“C”是最有可能的,在时间步长 1 时,字母“A”是最有可能的,在时间步长 2 时,字母“T”是最有可能的,那么由最简单的解码器给出的转录将是“CAT”。这种策略称为贪婪解码。
这是一种将模型输出的概率解码为字符序列的相当不错的方法,但它有一个主要的缺陷:它只考虑网络的输出,这意味着它只考虑来自音频的信息。当同一音频具有两个同样可能的转录(想想“new”与“knew”,“pause”与“paws”)时,模型只能猜测哪一个是正确的。这远非最佳:如果一个句子的前四个词是“the cat has tiny”,我们可以相当肯定第五个词是“paws”,而不是“pause”。回答这类问题是语言模型的工作,如果我们能将语言模型集成到我们模型的解码阶段,我们就能得到更好的结果。
当我们第一次尝试解决这个问题时,我们在 TensorFlow 中遇到了几个障碍:首先,它没有在 Python API 中公开其波束评分功能(可能是出于性能方面的考虑);其次,CTC 损失函数输出的对数概率是(曾经是)无效的。
我们决定通过构建类似于拼写检查器的东西来解决这个问题:遍历转录并查看我们是否可以进行一些小的修改来增加该转录是有效英语的可能性,这取决于语言模型。这在纠正输出中的少量拼写错误方面做得相当不错,但随着我们越来越接近我们的目标错误率,我们意识到这还不够。我们必须硬着头皮写一些 C++。
使用语言模型进行波束评分
将语言模型集成到解码器中,涉及每次评估对转录的添加时查询语言模型。回到前面的例子,当查看是否要在“the cat has tiny”之后选择“paws”还是“pause”作为下一个词时,我们会查询语言模型,并将该分数用作权重来对候选转录进行排序。现在我们可以利用来自音频和我们的语言模型的信息来决定哪个转录更有可能。该算法在 Hannun 等人发表的这篇论文 中进行了描述。
幸运的是,TensorFlow 在其 CTC 波束搜索解码器上有一个扩展点,允许用户提供自己的波束评分器。这意味着你只需要编写查询语言模型的波束评分器,然后将其插入即可。对于我们的情况,我们希望该功能公开给我们的 Python 代码,因此我们也将其作为自定义 TensorFlow 操作公开,可以使用 tf.load_op_library 加载。
让所有这些与我们的设置一起工作需要相当多的努力,从与 Bazel 构建系统搏斗数小时,到确保所有代码都能以一致的方式处理 Unicode 输入,以及调试光束评分器本身。该系统需要相当多的部分协同工作
虽然添加这么多活动部件确实使我们的代码更难修改和应用于不同的用例(如其他语言),但它也带来了巨大的好处:我们在 LibriSpeech 的测试清理集上的词错误率从 16% 降至 6.5%,这不仅实现了我们的初始目标,而且使我们接近人类级别的性能(根据 Deep Speech 2 论文,为 5.83%)。在一台 MacBook Pro 上,使用 GPU,该模型可以在大约 0.3 倍的实时因子下进行推理,而在仅使用 CPU 时,大约为 1.4 倍。(1 倍的实时因子意味着你可以在 1 秒内转录 1 秒的音频。)
从初始发布我们的模型开始,这是一段令人难以置信的旅程!将来,我们希望发布一个足够快可以在移动设备或 Raspberry Pi 上运行的模型。
如果这种类型的作品对你来说很有趣或有用,请查看 我们在 GitHub 上的仓库 和我们的 Discourse 频道。我们有一个不断壮大的贡献者社区,我们很高兴帮助你为你的语言创建和发布模型。
关于 Reuben Morais
Reuben Morais 是 Mozilla 机器学习团队的高级研究工程师。他目前专注于缩小机器学习研究与现实世界应用之间的差距,为用户带来保护隐私的语音技术。
21条评论