
人们称 WebAssembly 为游戏规则改变者,因为它使在网络上更快地运行代码成为可能。其中一些 加速已经出现,而一些加速还有待实现。
这些加速之一是流式编译,即浏览器在代码仍在下载时编译代码。到目前为止,这只是一个潜在的未来加速。但随着下周发布的 Firefox 58,它将成为现实。
Firefox 58 还包括一个新的两层编译器。新的基线编译器比优化编译器快 10-15 倍。
结合起来,这两个更改意味着我们编译代码的速度比网络传输的速度更快。

在台式机上,我们每秒编译 30-60 兆字节的 WebAssembly 代码。这 比网络 传输数据包的速度更快。
如果您使用 Firefox Nightly 或 Beta,您可以在自己的设备上 尝试一下。即使在相当普通的移动设备上,我们也能以每秒 8 兆字节的速度进行编译,这比几乎所有移动网络的平均下载速度都快。
这意味着您的代码几乎在完成下载后立即执行。
为什么这很重要?
当网站发送大量 JavaScript 时,Web 性能倡导者会感到很棘手。这是因为下载大量 JavaScript 会使页面加载速度变慢。
这主要是因为解析和编译时间。正如 Steve Souders 指出,Web 性能的旧瓶颈曾经是网络。但 Web 性能的新瓶颈是 CPU,尤其是主线程。

因此,我们希望尽可能多地将工作从主线程转移出去。我们还希望尽快开始,以便利用 CPU 的所有时间。更好的是,我们可以减少 CPU 的工作量。
对于 JavaScript,您可以做一些事情。您可以在文件流入时将其从主线程中解析出来。但是您仍然需要解析它们,这需要很多工作,而且您必须等到解析完毕才能开始编译。对于编译,您需要回到主线程。这是因为 JS 通常是在运行时 延迟编译 的。
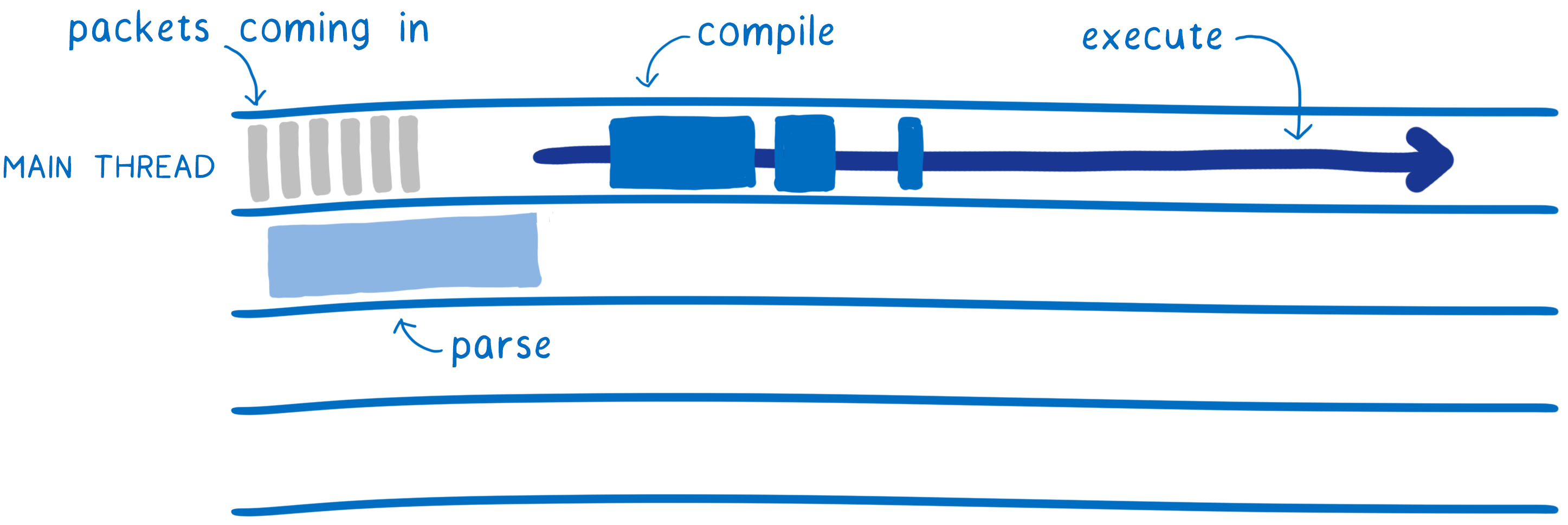
对于 WebAssembly,一开始需要做的工作更少。解码 WebAssembly 比解析 JavaScript 简单得多,也快得多。这种解码和编译可以在多个线程之间进行。
这意味着多个线程将执行基线编译,这使其更快。完成之后,基线编译的代码可以在主线程上开始执行。它不必像 JS 那样暂停以进行编译。
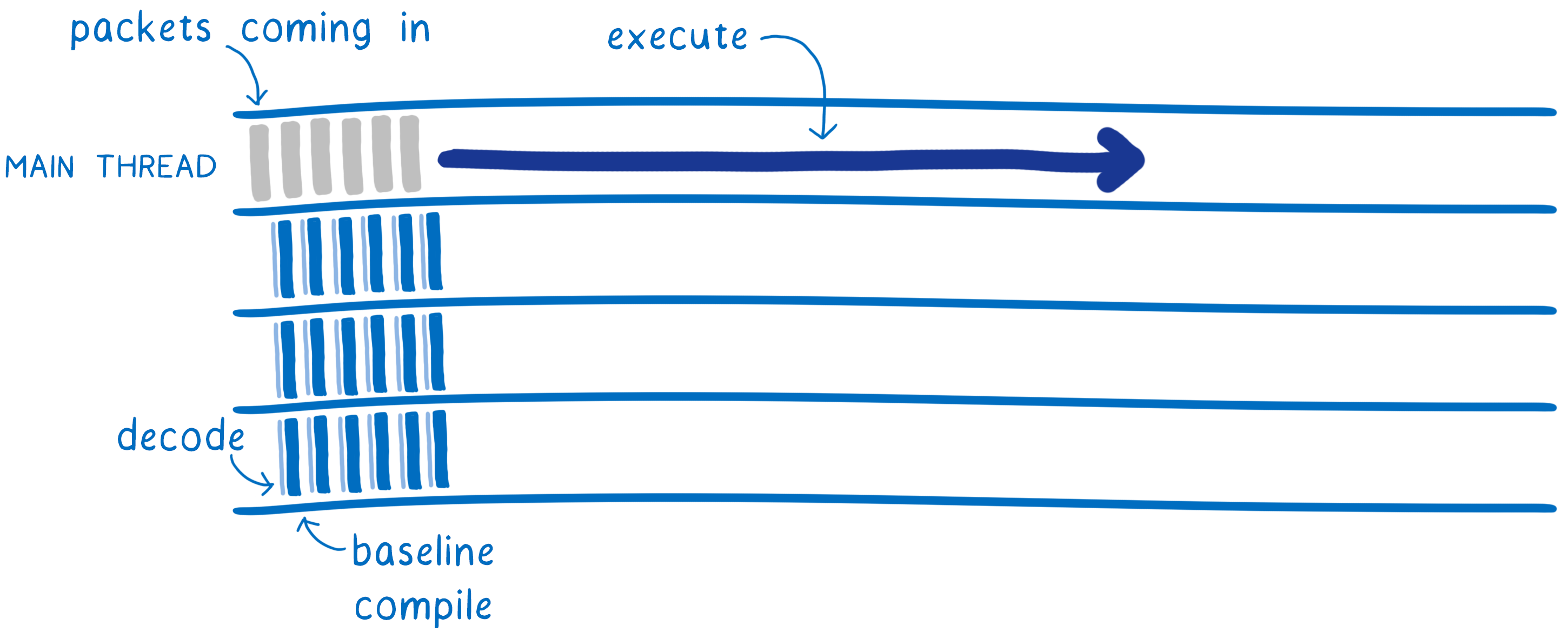
当基线编译的代码在主线程上运行时,其他线程会继续优化版本。当优化版本完成时,可以将其替换掉,使代码运行得更快。
这改变了加载 WebAssembly 的成本,使其更像是解码图像而不是加载 JavaScript。想想看……Web 性能倡导者确实对 150 kB 的 JS 负载感到棘手,但同样大小的图像负载却不会引起任何关注。

这是因为图像的加载时间要快得多,正如 Addy Osmani 在 JavaScript 的成本 中所解释的那样,解码图像不会阻塞主线程,正如 Alex Russell 在 您能负担得起吗?现实世界的 Web 性能预算 中所讨论的那样。
这并不意味着我们期望 WebAssembly 文件与图像文件一样大。虽然早期的 WebAssembly 工具会创建较大的文件,因为它们包含大量运行时,但目前有大量工作在使这些文件更小。例如,Emscripten 具有一个 “缩减计划”。在 Rust 中,您已经可以使用 wasm32-unknown-unknown 目标获得相当小的文件大小,并且还有像 wasm-gc 和 wasm-snip 这样的工具,可以进一步优化这些文件。
这意味着这些 WebAssembly 文件的加载速度会比等效的 JavaScript 快得多。
这是个重大事件。正如 Yehuda Katz 指出,这是一个游戏规则改变者。

那么让我们看看新编译器是如何工作的。
流式编译:更早开始编译
如果您更早开始编译代码,您将更早完成编译代码。这就是流式编译的功能……使其能够尽快开始编译 .wasm 文件。
当您下载文件时,它不会一次性下载下来。相反,它会以一系列数据包的形式下载下来。
以前,当 .wasm 文件中的每个数据包正在下载时,浏览器的网络层会将其放入一个 ArrayBuffer 中。

然后,完成后,它会将该 ArrayBuffer 移到 Web VM(又称 JS 引擎)中。这时,WebAssembly 编译器会开始编译。

但没有充分的理由让编译器等待。从技术上讲,可以逐行编译 WebAssembly。这意味着您可以尽快从第一个块开始。
因此,这就是我们的新编译器所做的。它利用了 WebAssembly 的流式 API。
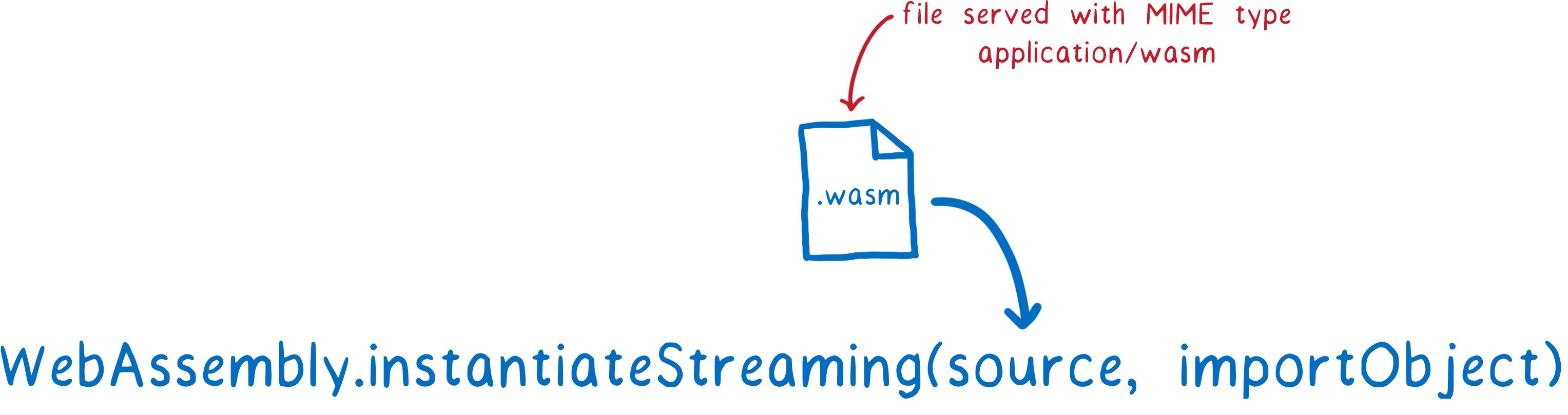
如果您向 WebAssembly.instantiateStreaming 提供一个响应对象,这些块将在到达时立即进入 WebAssembly 引擎。然后,编译器可以在下载下一个块时开始处理第一个块。

除了能够并行下载和编译代码之外,这样做还有另一个优势。
.wasm 模块的代码部分位于任何数据(将进入模块的内存对象)之前。因此,通过流式传输,编译器可以在模块的数据仍在下载时编译代码。如果您的模块需要大量数据,数据可能是兆字节,因此这很重要。
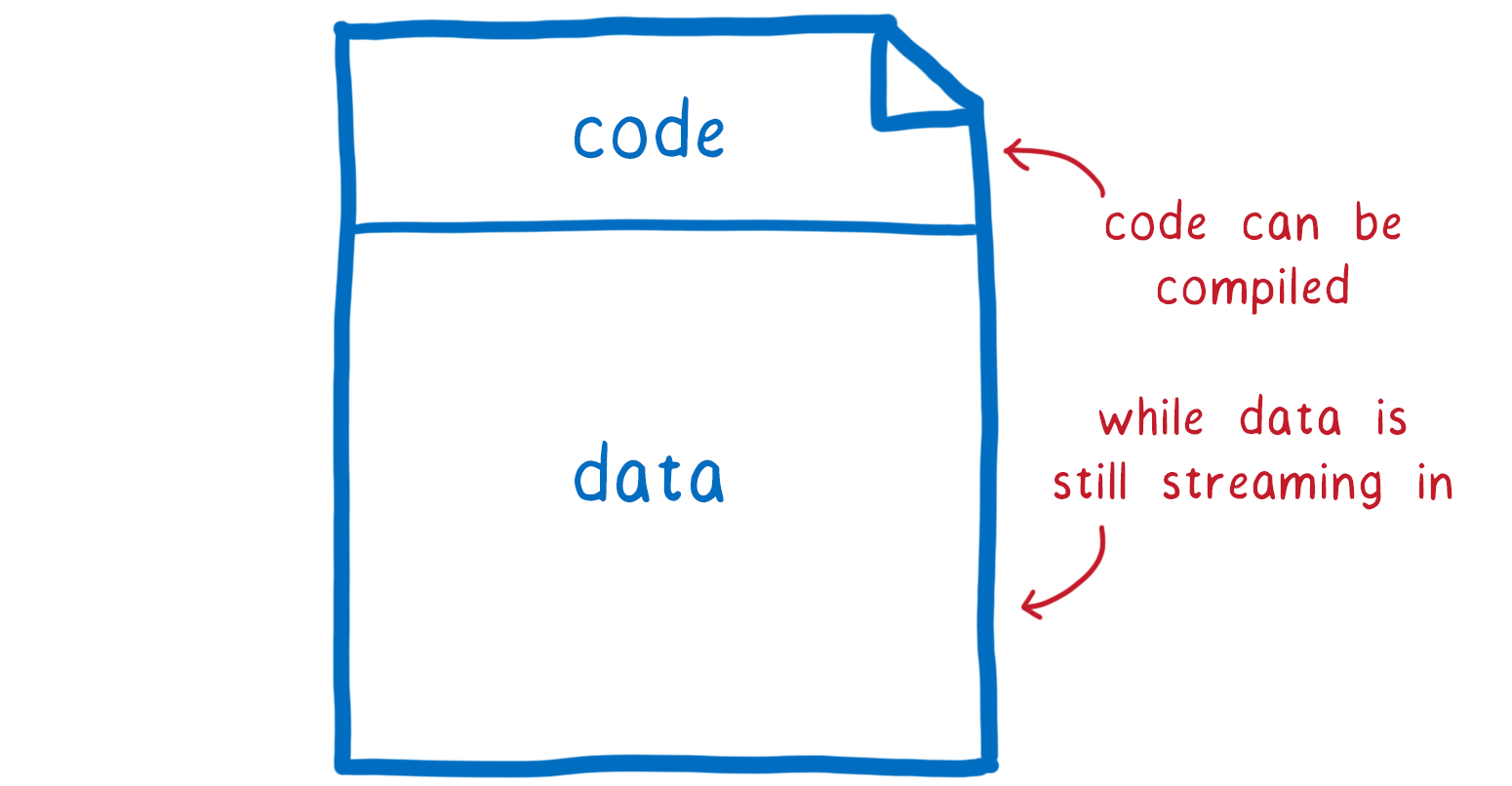
使用流式传输,我们可以更早开始编译。但我们也可以加快编译速度。
1 级基线编译器:更快编译代码
如果您希望代码运行速度快,您需要对其进行优化。但在编译时执行这些优化会花费时间,从而使编译代码的速度变慢。因此存在权衡。
我们可以同时拥有这两个世界的优势。如果我们使用两个编译器,我们可以让一个编译器快速编译,而不会进行太多优化,另一个编译器可以更慢地编译代码,但会生成更优化的代码。
这被称为分层编译。当代码首次进入时,它由 1 级(或基线)编译器编译。然后,在基线编译的代码开始运行后,2 级编译器会在后台再次遍历代码并编译一个更优化的版本。
完成后,它会将优化后的代码热交换为之前的基线版本。这使代码执行速度更快。
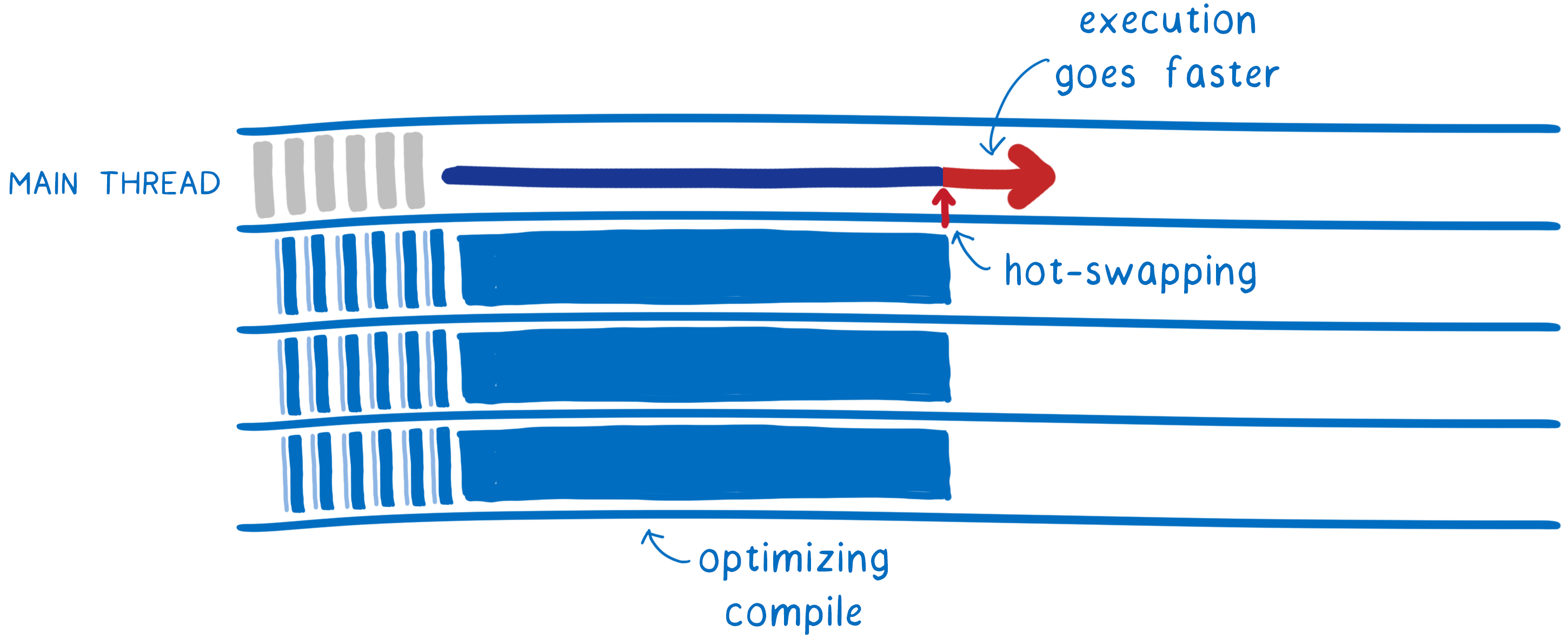
JavaScript 引擎很早就开始使用分层编译器。但是,JS 引擎只会在一段代码变得“热”时使用 2 级(或优化)编译器,即当代码的这一部分被多次调用时。
相反,WebAssembly 2 级编译器将积极地进行完全重新编译,优化模块中的所有代码。将来,我们可能会为开发人员添加更多选项来控制优化执行得有多积极或多被动。
此基线编译器在启动时节省了大量时间。它编译代码的速度是优化编译器的 10-15 倍。并且它生成的代码在我们的测试中只慢了 2 倍。
这意味着您的代码即使在最初的几秒钟内,在它仍然运行基线编译的代码时,也会运行得相当快。
并行化:让所有这一切变得更快
在 关于 Firefox Quantum 的文章 中,我解释了粗粒度和细粒度并行化。我们在这两种方法中都使用它们来编译 WebAssembly。
我在上面提到过,优化编译器将在后台进行其编译。这意味着它会将主线程留给代码执行。基线编译版本的代码可以在优化编译器进行重新编译时运行。
但在大多数计算机上,这仍然会使多个核心未被使用。为了充分利用所有核心,两个编译器都使用细粒度并行化来划分工作。
并行化的单元是函数。每个函数可以独立编译,在不同的核心上运行。实际上,这种粒度非常细,我们需要将这些函数打包成更大的函数组。这些批次被发送到不同的核心。
… 然后通过隐式缓存完全跳过所有这些工作(未来工作)
目前,每次重新加载页面都会重新进行解码和编译。但是,如果使用的是相同的 .wasm 文件,它应该编译成相同的机器代码。
这意味着,大多数情况下,可以跳过这项工作。未来,我们将会这样做。我们将在第一次页面加载时进行解码和编译,然后将生成的机器代码缓存到 HTTP 缓存中。之后,当您请求该 URL 时,它将提取预编译的机器代码。
这使得后续页面加载时的加载时间消失。
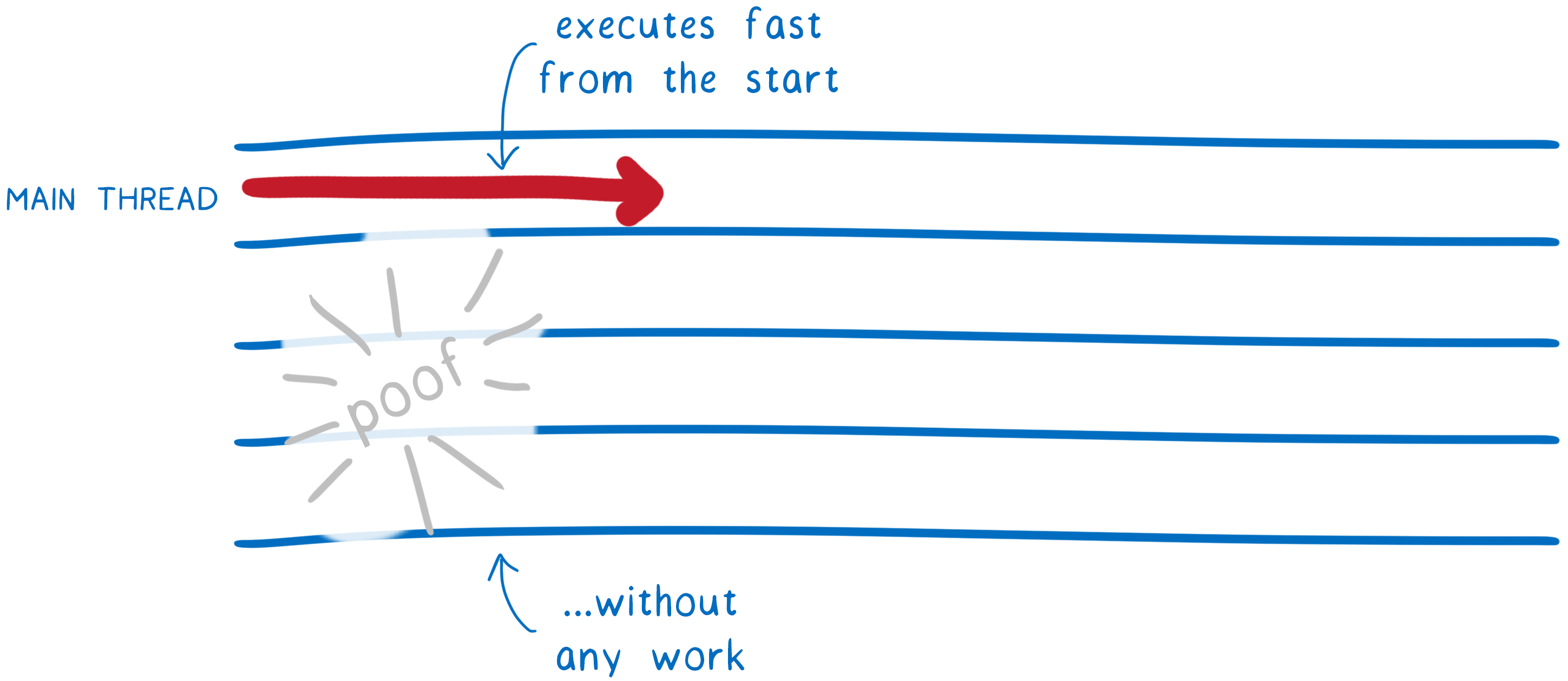
此功能的基础工作已经完成。我们在 Firefox 58 版本中 以这种方式缓存 JavaScript 字节码。我们只需要将此支持扩展到缓存 .wasm 文件的机器代码。
关于 Lin Clark
Lin 在 Mozilla 的高级开发部门工作,专注于 Rust 和 WebAssembly。
22条评论