
Edit: 进一步的算法改进带来了比本文所述更快的速度提升,总共比原始实现快了 **10.9 倍**。在 Speed Without Wizardry! 中了解这些额外收益。
Tom Tromey 和我用 Rust 代码替换了 source-map JavaScript 库的 Source Map 解析器中对性能影响最大的部分,该代码被编译成 WebAssembly。在现实基准测试中,WebAssembly 比 JavaScript 实现快了 **5.89 倍**,处理的是真实世界的 Source Map。此外,性能也更加一致:相对标准差降低了。
我们删除了以牺牲性能为代价而编写得过于复杂和不符合习惯的 JavaScript 代码,并用性能更佳的符合习惯的 Rust 代码替换了它。
我们希望通过分享我们的经验,激励其他人效仿,使用 WebAssembly 将性能敏感的 JavaScript 代码重写为 Rust 代码。
背景
Source Map 格式
Source Map 格式 提供了编译器0、压缩器或包捆绑工具生成的某些 JavaScript 代码中的位置与程序员编写的原始源代码中的位置之间的双向映射。JavaScript 开发人员工具使用 Source Map 对堆栈跟踪进行符号化,并在调试器中实现源级步进。Source Map 编码的调试信息类似于 DWARF’s .debug_line 部分中的调试信息。
Source Map 是一个 JSON 对象,包含几个字段。"mappings" 字段是一个字符串,它构成了 Source Map 的主体,包含源位置和目标位置之间的双向映射。
我们将在 扩展巴科斯-诺尔范式 (EBNF) 中描述 "mappings" 字符串的语法。
映射按生成的 JavaScript 行号分组,每次在单个映射之间放置分号时都会递增行号。当连续映射位于同一生成的 JavaScript 行上时,它们用逗号分隔
<mappings> = [ <generated-line> ] ';' <mappings>
| ''
;
<generated-line> = <mapping>
| <mapping> ',' <generated-line>
;
每个单独的映射都具有生成的 JavaScript 中的位置,以及可选的原始源文本中的位置,该位置可能还包含一个关联的名称
<mapping> = <generated-column> [ <source> <original-line> <original-column> [ <name> ] ] ;
映射的每个组件都是一个使用可变长度量 (VLQ) 编码的整数。文件名和关联名称被编码为 Source Map 的 JSON 对象中其他字段中存储的侧边表的索引。每个值都相对于其类型的上次出现,例如,给定的 <source> 值是自上次 <source> 值以来的增量。这些增量往往比它们的绝对值小,这意味着它们在编码时更紧凑
<generated-column> = <vlq> ;
<source> = <vlq> ;
<original-line> = <vlq> ;
<original-column> = <vlq> ;
<name> = <vlq> ;
VLQ 中的每个字符都来自一组 64 个可打印的 ASCII 字符,包括大写和小写字母、十进制数字和一些符号。每个字符代表一个特定的 6 位值。除 VLQ 中最后一个字符外,所有字符的最重要一位都已设置;剩余的 5 位被附加到表示的整数值前面。
我们没有尝试将此定义翻译成 EBNF,而是提供了以下用于解析和解码单个 VLQ 的伪代码。
constant SHIFT = 5
constant CONTINUATION_BIT = 1 << SHIFT
constant MASK = (1 << SHIFT) - 1
decode_vlq(input):
let accumulation = 0
let shift = 0
let next_digit_part_of_this_number = true;
while next_digit_part_of_this_number:
let [character, ...rest] = input
let digit = decode_base_64(character)
accumulation += (digit & MASK) << shift
shift += SHIFT;
next_digit_part_of_this_number = (digit & CONTINUATION_BIT) != 0
input = rest
let is_negative = accumulation & 1
let value = accumulation >> 1
if is_negative:
return (-value, input)
else:
return (value, input)
source-map JavaScript 库
source-map 库 发布在 npm 上,由 Mozilla 的 Firefox 开发人员工具团队 维护。它是 JavaScript 社区中最依赖的库之一,每周下载量为 1000 万次。
与许多软件项目一样,source-map 库最初是为了正确性而编写的,后来又进行修改以提高性能。到目前为止,它已经经历了许多性能改进。
在使用 Source Map 时,大多数时间都花在解析 "mappings" 字符串和构建一对数组上:一个按生成的 JavaScript 位置排序,另一个按原始源代码位置排序。查询在适当的数组上使用二进制搜索。解析和排序都是懒惰进行的,只有在特定查询需要时才会进行。这允许调试器列出源代码,例如,无需解析和排序映射。解析和排序完成后,查询往往不会成为性能瓶颈。
VLQ 解码函数以字符串作为输入,解析和解码字符串中的 VLQ,并返回一个包含值和未消耗的输入的剩余部分的对。此函数最初是用符合习惯的、引用透明的方式编写的,以便将对作为具有两个属性的 Object 字面量返回
function decodeVlqBefore(input) {
// ...
return { result, rest };
}
发现以这种方式返回对成本很高。JavaScript 即时 (JIT) 编译器的优化编译层无法消除此分配。由于 VLQ 解码例程经常被调用,因此此分配会对垃圾收集器造成不必要的压力,导致垃圾收集暂停更加频繁。
为了消除分配,我们 修改了该过程,使其接受第二个参数:一个被修改并充当输出参数的 Object。我们没有返回一个新分配的 Object,而是覆盖了输出参数的属性。这样,我们可以为每次 VLQ 解析重复使用同一个对象。这种方法虽然不符合习惯,但性能更好
function decodeVlqAfter(input, out) {
// ...
out.result = result;
out.rest = rest;
}
在遇到意外的字符串结尾或无效的 base 64 字符时,VLQ 解码函数会 throw 一个 Error。我们发现,当我们 更改单个 base 64 数字解码函数以在失败时返回 -1 而不是 throw 一个 Error 时,JavaScript JIT 会发出更快的代码。这种方法虽然不符合习惯,但再次提高了性能。
在使用 SpiderMonkey 的 JITCoach 原型进行分析时,我们发现 SpiderMonkey 的 JIT 在我们的映射 Object 上使用的是慢速多态内联缓存来获取和设置 Object 属性。JIT 无法发出具有直接对象插槽访问的理想快速路径代码,因为它没有检测到所有映射 Object 共享的常见 “形状”(或“隐藏类”)。例如,当没有与映射关联的名称时,某些属性会以不同的顺序添加,或完全省略。通过为映射 Object 创建一个构造函数,该构造函数初始化了我们将使用的所有属性,我们帮助 JIT 为所有映射 Object 创建了一个通用形状。这导致了 另一个性能改进
function Mapping() {
this.generatedLine = 0;
this.generatedColumn = 0;
this.lastGeneratedColumn = null;
this.source = null;
this.originalLine = null;
this.originalColumn = null;
this.name = null;
}
在对两个映射数组进行排序时,我们使用自定义比较器函数。当 source-map 库最初编写时,SpiderMonkey 的 Array.prototype.sort 是用 C++ 实现的,以提高性能1。但是,当 sort 传递显式比较器函数和大型数组时,排序代码必须多次调用比较器函数。从 C++ 到 JavaScript 的调用相对昂贵,因此传递自定义比较器函数会导致排序性能很差。
为了避免这种情况,我们 在 JavaScript 中实现了我们自己的快速排序。这不仅避免了 C++ 到 JavaScript 的调用,而且还允许 JavaScript JIT 将比较器函数内联到排序函数中,从而实现进一步优化。这为我们带来了另一个巨大的性能提升,再次使代码更不符合习惯。
WebAssembly
WebAssembly 是一种新的、低级的、与架构无关的字节码,专门为 Web 开发。它旨在安全、高效地执行和生成紧凑的二进制文件,并作为 Web 标准公开开发。所有主流 Web 浏览器都支持它。
WebAssembly 公开了与现代处理器架构相匹配的堆栈机器。它的指令在大型线性内存缓冲区上运行。它不支持垃圾收集,尽管将其扩展以与垃圾收集的 JavaScript 对象一起使用是 未来的计划。控制流是结构化的,而不是允许任意跳转和标签。它旨在是确定性和一致性的,即使在不同架构在边缘情况下存在差异时也是如此,例如超出范围的移位、溢出和规范化 NaN。
WebAssembly 旨在匹配或超越本机执行速度。目前,它 在大多数基准测试中处于本机执行速度的 1.5 倍之内。
由于缺乏垃圾收集器,目前针对 WebAssembly 的语言仅限于没有运行时或垃圾收集器的语言,除非收集器和运行时也编译为 WebAssembly。在实践中,这种情况不会发生。目前,开发人员实际编译到 WebAssembly 的语言是 C、C++ 和 Rust。
Rust
Rust 是一种系统编程语言,强调安全性和速度。它提供内存安全,但不依赖垃圾收集器。相反,它静态跟踪资源的所有权和借用,以确定在哪里发出代码来运行析构函数或释放内存。
Rust 非常适合编译到 WebAssembly。由于 Rust 不需要垃圾收集,因此 Rust 作者不必为针对 WebAssembly 而进行额外的操作。Rust 拥有 Web 开发人员期望的许多优点,而 C 和 C++ 则没有这些优点
- 轻松构建、打包、发布、共享和记录库。Rust 有
rustup、cargo和 crates.io 生态系统;C 和 C++ 没有任何广泛使用的等效工具。 -
内存安全。无需在
gdb中追查内存损坏。Rust 在编译时阻止了大多数这类陷阱。
在 Rust 中解析和查询 Source Map
当我们决定用 Rust 重写源映射解析和查询的热部分时,我们必须决定 JavaScript 和 Rust 编译器发出的 WebAssembly 之间的边界在哪里。目前,跨越 JavaScript 的 JIT 代码到 WebAssembly 的边界以及返回会带来类似于我们之前提到的 C++ 到 JavaScript 调用那样的开销。2 所以将这个边界放置在适当的位置以最小化跨越它的次数很重要。
一个关于将 WebAssembly 和 JavaScript 之间的边界放置在何处的不好的选择是在 VLQ 解码函数处。VLQ 解码函数对于 "mappings" 字符串中编码的每个映射会调用一到四次,因此在解析过程中,我们必须跨越 JavaScript 到 WebAssembly 的边界那么多次。
相反,我们决定在 Rust/WebAssembly 中解析整个 "mappings" 字符串,然后将解析后的数据保留在那里。WebAssembly 堆在其可查询形式中拥有解析后的数据。这意味着我们不必将数据从 WebAssembly 堆中复制出来,这会导致更频繁地跨越 JavaScript/WebAssembly 边界。相反,我们只为每个查询跨越一次边界,外加为每个查询结果的映射跨越一次边界。查询倾向于产生单个结果,或者可能是一小部分。
为了确保我们的 Rust 实现是正确的,我们不仅确保我们的新实现通过了 source-map 库的现有测试套件,还编写了一个 quickcheck 属性测试套件。这些测试构建随机的 "mappings" 输入字符串,解析它们,然后断言各种属性成立。
我们在 crates.io 上发布了我们的 Rust 实现的 "mappings" 解析和查询,它被称为 source-map-mappings 包。
Base 64 可变长度量
解析源映射映射的第一步是解码 VLQ。我们在 Rust 中实现了一个 vlq 库 并将其发布到 crates.io。
decode64 函数解码单个 base 64 数字。它使用模式匹配和惯用的 Result 风格的错误处理。
一个 Result<T, E> 要么是 Ok(v),表示操作成功并生成了类型为 T 的值 v,要么是 Err(error),表示操作失败,类型为 E 的值 error 提供了详细信息。decode64 函数的返回类型 Result<u8, Error> 表示它在成功时返回一个 u8 值,或在失败时返回一个 vlq::Error 值
fn decode64(input: u8) -> Result<u8, Error> {
match input {
b'A'...b'Z' => Ok(input - b'A'),
b'a'...b'z' => Ok(input - b'a' + 26),
b'0'...b'9' => Ok(input - b'0' + 52),
b'+' => Ok(62),
b'/' => Ok(63),
_ => Err(Error::InvalidBase64(input)),
}
}
有了 decode64 函数,我们就可以解码完整的 VLQ 值。decode 函数将一个字节迭代器的可变引用作为输入,消耗它解码 VLQ 所需的字节数,最后返回解码值的 Result
pub fn decode<B>(input: &mut B) -> Result<i64>
where
B: Iterator<Item = u8>,
{
let mut accum: u64 = 0;
let mut shift = 0;
let mut keep_going = true;
while keep_going {
let byte = input.next().ok_or(Error::UnexpectedEof)?;
let digit = decode64(byte)?;
keep_going = (digit & CONTINUED) != 0;
let digit_value = ((digit & MASK) as u64)
.checked_shl(shift as u32)
.ok_or(Error::Overflow)?;
accum = accum.checked_add(digit_value).ok_or(Error::Overflow)?;
shift += SHIFT;
}
let abs_value = accum / 2;
if abs_value > (i64::MAX as u64) {
return Err(Error::Overflow);
}
// The low bit holds the sign.
if (accum & 1) != 0 {
Ok(-(abs_value as i64))
} else {
Ok(abs_value as i64)
}
}
与它所替换的 JavaScript 代码不同,这段代码没有为了性能而牺牲惯用的错误处理。惯用的错误处理确实是高效的,并且不涉及在堆上对值进行装箱或展开堆栈。
"mappings" 字符串
我们首先定义一些小的辅助函数。is_mapping_separator 谓词函数在给定字节是映射之间的分隔符时返回 true,否则返回 false。有一个几乎相同的 JavaScript 函数
#[inline]
fn is_mapping_separator(byte: u8) -> bool {
byte == b';' || byte == b','
}
接下来,我们定义一个辅助函数来读取单个 VLQ 偏移值并将其添加到前一个值。JavaScript 没有等效的函数,而是每次想要读取 VLQ 偏移值时都会重复这段代码。JavaScript 不让我们控制参数在内存中的表示方式,但 Rust 可以。我们不能以零成本的方式将引用传递给 JavaScript 中的数字。我们可以将引用传递给具有数字属性的 Object,或者我们可以将数字的变量封闭在局部闭包函数中,但这两种解决方案都与运行时成本相关联
#[inline]
fn read_relative_vlq<B>(
previous: &mut u32,
input: &mut B,
) -> Result<(), Error>
where
B: Iterator<Item = u8>,
{
let decoded = vlq::decode(input)?;
let (new, overflowed) = (*previous as i64).overflowing_add(decoded);
if overflowed || new > (u32::MAX as i64) {
return Err(Error::UnexpectedlyBigNumber);
}
if new < 0 {
return Err(Error::UnexpectedNegativeNumber);
}
*previous = new as u32;
Ok(())
}
总而言之,Rust 实现的 "mappings" 解析与它所替换的 JavaScript 实现非常相似。但是,使用 Rust,我们可以控制哪些是装箱的,哪些不是,而在 JavaScript 中,我们不能。在 JavaScript 实现中,每个解析的映射 Object 都是装箱的。Rust 实现的大部分优势来自于避免这些分配及其相关的垃圾回收
pub fn parse_mappings(input: &[u8]) -> Result<Mappings, Error> {
let mut generated_line = 0;
let mut generated_column = 0;
let mut original_line = 0;
let mut original_column = 0;
let mut source = 0;
let mut name = 0;
let mut mappings = Mappings::default();
let mut by_generated = vec![];
let mut input = input.iter().cloned().peekable();
while let Some(byte) = input.peek().cloned() {
match byte {
b';' => {
generated_line += 1;
generated_column = 0;
input.next().unwrap();
}
b',' => {
input.next().unwrap();
}
_ => {
let mut mapping = Mapping::default();
mapping.generated_line = generated_line;
read_relative_vlq(&mut generated_column, &mut input)?;
mapping.generated_column = generated_column as u32;
let next_is_sep = input.peek()
.cloned()
.map_or(true, is_mapping_separator);
mapping.original = if next_is_sep {
None
} else {
read_relative_vlq(&mut source, &mut input)?;
read_relative_vlq(&mut original_line, &mut input)?;
read_relative_vlq(&mut original_column, &mut input)?;
let next_is_sep = input.peek()
.cloned()
.map_or(true, is_mapping_separator);
let name = if next_is_sep {
None
} else {
read_relative_vlq(&mut name, &mut input)?;
Some(name)
};
Some(OriginalLocation {
source,
original_line,
original_column,
name,
})
};
by_generated.push(mapping);
}
}
}
quick_sort::<comparators::ByGeneratedLocation, _>(&mut by_generated);
mappings.by_generated = by_generated;
Ok(mappings)
}
最后,我们仍然在 Rust 代码中使用自定义的快速排序实现,这是 Rust 代码中唯一不惯用的部分。我们发现,尽管标准库的内置排序在针对本机代码时快得多,但我们的自定义快速排序在针对 WebAssembly 时更快。(这令人惊讶,但我们没有调查原因。)
与 JavaScript 交互
WebAssembly 外部函数接口 (FFI) 仅限于标量值,因此通过 WebAssembly 从 Rust 公开给 JavaScript 的任何函数只能使用标量值类型作为参数和返回值。因此,JavaScript 代码必须要求 Rust 为 "mappings" 字符串分配一个带有空间的缓冲区,并返回指向该缓冲区的指针。接下来,JavaScript 必须将 "mappings" 字符串复制到该缓冲区中,它可以做到这一点而不会跨越 FFI 边界,因为它对整个 WebAssembly 线性内存具有写入访问权限。缓冲区初始化后,JavaScript 调用 parse_mappings 函数,并返回指向解析后的映射的指针。然后,JavaScript 可以通过 WebAssembly API 执行任意数量的查询,在执行查询时传入指向解析后的映射的指针。最后,当不再进行任何查询时,JavaScript 会告诉 WebAssembly 释放解析后的映射。
从 Rust 公开 WebAssembly API
我们公开的所有 WebAssembly API 都位于一个小的胶水包中,它包装了 source-map-mappings 包。这种分离很有用,因为它允许我们使用我们的本机主机目标测试 source-map-mappings 包,并且只在针对 WebAssembly 时编译 WebAssembly 胶水。
除了对可以跨越 FFI 边界的类型的限制外,每个导出的函数都需要
- 它具有
#[no_mangle]属性,这样它就不会被名称修饰,JavaScript 可以轻松地调用它,以及 - 它被标记为
extern "C",以便在最终的.wasm文件中公开它。
与核心库不同,这个通过 WebAssembly 向 JavaScript 公开功能的胶水代码出于必要性,经常使用 unsafe。调用 extern 函数和使用从 FFI 边界接收的指针始终是 unsafe 的,因为 Rust 编译器无法验证另一端的安全性。最终,与其他目标相比,这对于 WebAssembly 来说不那么令人担忧——我们能做的最糟糕的事情是 trap(导致在 JavaScript 侧引发 Error)或返回不正确的答案。比使用本机二进制文件时的最坏情况要温和得多,在本机二进制文件中,可执行内存与可写内存位于同一个地址空间,攻击者可以欺骗程序跳转到他们插入了一些 shell 代码的内存位置。
我们导出的最简单的函数是获取库中发生的最后一个错误的函数。这提供了类似于 libc 中的 errno 的功能,并在某个 API 调用失败且 JavaScript 希望知道发生了哪种类型的失败时由 JavaScript 调用。我们始终在全局变量中维护最近发生的错误,这个函数会检索该错误值
static mut LAST_ERROR: Option<Error> = None;
#[no_mangle]
pub extern "C" fn get_last_error() -> u32 {
unsafe {
match LAST_ERROR {
None => 0,
Some(e) => e as u32,
}
}
}
JavaScript 和 Rust 之间的第一次交互是为保存 "mappings" 字符串分配一个带有空间的缓冲区。我们想要一个拥有的连续的 u8 块,这表明使用 Vec<u8>,但我们希望向 JavaScript 公开单个指针。单个指针可以跨越 FFI 边界,并且在 JavaScript 侧更容易处理。我们可以使用 Box<Vec<u8>> 添加一层间接层,或者可以将用于重建向量所需的额外数据保存在一旁。我们选择后者。
向量是一个三元组,包括
- 指向堆分配的元素的指针,
- 该分配的容量,以及
- 初始化元素的长度。
由于我们只向 JavaScript 公开指向堆分配的元素的指针,因此我们需要一种方法来保存长度和容量,以便我们能够按需重建 Vec。我们分配两个额外的空间,并将长度和容量存储在堆元素的前两个空间中。然后,我们将指向这些额外空间之后的空间的指针传递给 JavaScript
#[no_mangle]
pub extern "C" fn allocate_mappings(size: usize) -> *mut u8 {
// Make sure that we don't lose any bytes from size in the remainder.
let size_in_units_of_usize = (size + mem::size_of::<usize>() - 1)
/ mem::size_of::<usize>();
// Make room for two additional `usize`s: we'll stuff capacity and
// length in there.
let mut vec: Vec<usize> = Vec::with_capacity(size_in_units_of_usize + 2);
// And do the stuffing.
let capacity = vec.capacity();
vec.push(capacity);
vec.push(size);
// Leak the vec's elements and get a pointer to them.
let ptr = vec.as_mut_ptr();
debug_assert!(!ptr.is_null());
mem::forget(vec);
// Advance the pointer past our stuffed data and return it to JS,
// so that JS can write the mappings string into it.
let ptr = ptr.wrapping_offset(2) as *mut u8;
assert_pointer_is_word_aligned(ptr);
ptr
}
在为 "mappings" 字符串初始化缓冲区后,JavaScript 将缓冲区的拥有权传递给 parse_mappings,后者将字符串解析为可查询的结构。返回指向可查询的 Mappings 结构的指针,或者如果发生某种解析错误,则返回 NULL。
parse_mappings 必须做的第一件事是恢复 Vec 的长度和容量。接下来,它构建 "mappings" 字符串数据的切片,将切片的生命周期限制在当前范围,以再次检查我们是否在切片被释放后再次访问了它,然后调用我们库的 "mappings" 字符串解析函数。无论解析成功与否,我们都会释放保存 "mappings" 字符串的缓冲区,并返回指向解析后的结构的指针,或者保存可能发生的任何错误,并返回 NULL。
/// Force the `reference`'s lifetime to match the `scope`'s
/// lifetime. Certain `unsafe` operations, such as dereferencing raw
/// pointers, return references with un-constrained lifetimes, and we
/// use this function to ensure we can't accidentally use the
/// references after they become invalid.
#[inline]
fn constrain<'a, T>(_scope: &'a (), reference: &'a T) -> &'a T
where
T: ?Sized
{
reference
}
#[no_mangle]
pub extern "C" fn parse_mappings(mappings: *mut u8) -> *mut Mappings {
assert_pointer_is_word_aligned(mappings);
let mappings = mappings as *mut usize;
// Unstuff the data we put just before the pointer to the mappings
// string.
let capacity_ptr = mappings.wrapping_offset(-2);
debug_assert!(!capacity_ptr.is_null());
let capacity = unsafe { *capacity_ptr };
let size_ptr = mappings.wrapping_offset(-1);
debug_assert!(!size_ptr.is_null());
let size = unsafe { *size_ptr };
// Construct the input slice from the pointer and parse the mappings.
let result = unsafe {
let input = slice::from_raw_parts(mappings as *const u8, size);
let this_scope = ();
let input = constrain(&this_scope, input);
source_map_mappings::parse_mappings(input)
};
// Deallocate the mappings string and its two prefix words.
let size_in_usizes = (size + mem::size_of::<usize>() - 1) / mem::size_of::<usize>();
unsafe {
Vec::<usize>::from_raw_parts(capacity_ptr, size_in_usizes + 2, capacity);
}
// Return the result, saving any errors on the side for later inspection by
// JS if required.
match result {
Ok(mappings) => Box::into_raw(Box::new(mappings)),
Err(e) => {
unsafe {
LAST_ERROR = Some(e);
}
ptr::null_mut()
}
}
}
当我们运行查询时,我们需要一种方法将结果跨越 FFI 边界。查询的结果要么是单个 Mapping,要么是一组多个 Mapping,而 Mapping 无法按原样跨越 FFI 边界,除非我们对它进行装箱。我们不希望对 Mapping 进行装箱,因为我们还需要为它的每个字段提供 getter,这会导致代码膨胀,并且增加了分配和间接的成本。我们的解决方案是为每个 Mapping 查询结果调用一个导入的函数。
mappings_callback 是一个没有定义的 extern 函数,它在 WebAssembly 中转换为一个导入的函数,JavaScript 在实例化 WebAssembly 模块时必须提供该函数。mappings_callback 接收一个 Mapping,该 Mapping 被分解为其成员部分:传递性扁平化的 Mapping 中的每个字段都被转换为一个参数,以便它可以跨越 FFI 边界。对于 Option<T> 成员,我们添加一个 bool 参数作为判别器,确定 Option<T> 是 Some 还是 None,因此确定后面的 T 参数是有效的还是垃圾
extern "C" {
fn mapping_callback(
// These two parameters are always valid.
generated_line: u32,
generated_column: u32,
// The `last_generated_column` parameter is only valid if
// `has_last_generated_column` is `true`.
has_last_generated_column: bool,
last_generated_column: u32,
// The `source`, `original_line`, and `original_column`
// parameters are only valid if `has_original` is `true`.
has_original: bool,
source: u32,
original_line: u32,
original_column: u32,
// The `name` parameter is only valid if `has_name` is `true`.
has_name: bool,
name: u32,
);
}
#[inline]
unsafe fn invoke_mapping_callback(mapping: &Mapping) {
let generated_line = mapping.generated_line;
let generated_column = mapping.generated_column;
let (
has_last_generated_column,
last_generated_column,
) = if let Some(last_generated_column) = mapping.last_generated_column {
(true, last_generated_column)
} else {
(false, 0)
};
let (
has_original,
source,
original_line,
original_column,
has_name,
name,
) = if let Some(original) = mapping.original.as_ref() {
let (
has_name,
name,
) = if let Some(name) = original.name {
(true, name)
} else {
(false, 0)
};
(
true,
original.source,
original.original_line,
original.original_column,
has_name,
name,
)
} else {
(
false,
0,
0,
0,
false,
0,
)
};
mapping_callback(
generated_line,
generated_column,
has_last_generated_column,
last_generated_column,
has_original,
source,
original_line,
original_column,
has_name,
name,
);
}
所有导出的查询函数都具有类似的结构。它们首先将原始的 *mut Mappings 指针转换为 &mut Mappings 可变引用。&mut Mappings 的生命周期被限制在当前作用域内,以强制执行它仅在该函数调用中使用,并且不会保存在任何地方,在那里它可能会在被释放后使用。接下来,导出的查询函数将查询转发到相应的 Mappings 方法。对于每个生成的 Mapping,导出的函数会调用 mapping_callback。
一个典型的例子是导出的 all_generated_locations_for 查询函数,它包装了 Mappings::all_generated_locations_for 方法,并找到与给定原始源位置相对应的所有映射。
#[inline]
unsafe fn mappings_mut<'a>(
_scope: &'a (),
mappings: *mut Mappings,
) -> &'a mut Mappings {
mappings.as_mut().unwrap()
}
#[no_mangle]
pub extern "C" fn all_generated_locations_for(
mappings: *mut Mappings,
source: u32,
original_line: u32,
has_original_column: bool,
original_column: u32,
) {
let this_scope = ();
let mappings = unsafe { mappings_mut(&this_scope, mappings) };
let original_column = if has_original_column {
Some(original_column)
} else {
None
};
let results = mappings.all_generated_locations_for(
source,
original_line,
original_column,
);
for m in results {
unsafe {
invoke_mapping_callback(m);
}
}
}
最后,当 JavaScript 完成对 Mappings 的查询后,它必须使用导出的 free_mappings 函数释放它们。
#[no_mangle]
pub extern "C" fn free_mappings(mappings: *mut Mappings) {
unsafe {
Box::from_raw(mappings);
}
}
将 Rust 编译成 .wasm 文件
添加 wasm32-unknown-unknown 目标使将 Rust 编译成 WebAssembly 成为可能,而 rustup 使安装针对 wasm32-unknown-unknown 的 Rust 编译器工具链变得容易。
$ rustup update
$ rustup target add wasm32-unknown-unknown
现在我们有了 wasm32-unknown-unknown 编译器,构建目标平台和 WebAssembly 之间的唯一区别在于 --target 标志。
$ cargo build --release --target wasm32-unknown-unknown
生成的 .wasm 文件位于 target/wasm32-unknown-unknown/release/source_map_mappings_wasm_api.wasm。
虽然我们现在有了可用的 .wasm 文件,但我们还没有完成:这个 .wasm 文件仍然比它需要的要大得多。为了生成我们所能得到的最小 .wasm 文件,我们利用了以下工具
wasm-gc,它就像链接器的--gc-sections标志一样,用于删除未使用的目标文件部分,但用于.wasm文件而不是 ELF、Mach-O 等目标文件。它找到所有从导出函数无法传递访问的函数,并将其从.wasm文件中删除。-
wasm-snip,用于将 WebAssembly 函数的主体替换为单个unreachable指令。这对于手动删除在运行时永远不会被调用的函数非常有用,但编译器和wasm-gc无法静态地证明这些函数是无法访问的。剪切函数可能会使其他函数静态地无法访问,因此在之后再次运行wasm-gc是有意义的。 -
wasm-opt,它对.wasm文件运行binaryen的优化传递,缩小其大小并提高其运行时性能。最终,当 LLVM 的 WebAssembly 后端成熟后,这可能不再是必需的。
我们的 构建后管道 采用 wasm-gc → wasm-snip → wasm-gc → wasm-opt 的流程。
在 JavaScript 中使用 WebAssembly API
在 JavaScript 中使用 WebAssembly 时,首要关注的问题是如何加载 .wasm 文件。source-map 库主要在三种环境中使用。
- Node.js
- Web
- Firefox 开发者工具内部
不同的环境可能具有不同的方法将 .wasm 文件的字节加载到 ArrayBuffer 中,该 ArrayBuffer 可以随后由 JavaScript 运行时编译。在 Web 和 Firefox 内部,我们可以使用标准的 fetch API 发出 HTTP 请求以加载 .wasm 文件。库使用者有责任在解析任何源映射之前提供指向 .wasm 文件的 URL。当与 Node.js 一起使用时,库使用 fs.readFile API 从磁盘读取 .wasm 文件。在这种情况下,在解析任何源映射之前不需要进行任何初始化。我们通过使用功能检测来选择正确的 .wasm 加载实现,从而提供了一个统一的接口,无论库在哪个环境中加载。
在编译和实例化 WebAssembly 模块时,我们必须提供 mapping_callback。此回调在实例化的 WebAssembly 模块的生命周期中不能更改,但根据我们正在执行的查询类型,我们希望对生成的映射做不同的事情。因此,我们提供的实际 mapping_callback 仅负责将展开的映射成员转换为结构化对象,然后将该结果传递到我们根据正在运行的查询设置的闭包函数。
let currentCallback = null;
// ...
WebAssembly.instantiate(buffer, {
env: {
mapping_callback: function (
generatedLine,
generatedColumn,
hasLastGeneratedColumn,
lastGeneratedColumn,
hasOriginal,
source,
originalLine,
originalColumn,
hasName,
name
) {
const mapping = new Mapping;
mapping.generatedLine = generatedLine;
mapping.generatedColumn = generatedColumn;
if (hasLastGeneratedColumn) {
mapping.lastGeneratedColumn = lastGeneratedColumn;
}
if (hasOriginal) {
mapping.source = source;
mapping.originalLine = originalLine;
mapping.originalColumn = originalColumn;
if (hasName) {
mapping.name = name;
}
}
currentCallback(mapping);
}
}
})
为了使设置和取消设置 currentCallback 更符合人体工程学,我们定义了一个 withMappingCallback 帮助程序,它接受两个函数:一个用于设置为 currentCallback,另一个用于立即调用。一旦第二个函数的执行完成,我们将 currentCallback 重置为 null。这相当于 JavaScript 的 RAII。
function withMappingCallback(mappingCallback, f) {
currentCallback = mappingCallback;
try {
f();
} finally {
currentCallback = null;
}
}
回想一下,JavaScript 在解析源映射时,第一个任务是告诉 WebAssembly 为 "mappings" 字符串分配空间,然后将该字符串复制到分配的缓冲区中。
const size = mappingsString.length;
const mappingsBufPtr = this._wasm.exports.allocate_mappings(size);
const mappingsBuf = new Uint8Array(
this._wasm.exports.memory.buffer,
mappingsBufPtr,
size
);
for (let i = 0; i < size; i++) {
mappingsBuf[i] = mappingsString.charCodeAt(i);
}
一旦 JavaScript 初始化了缓冲区,它就会调用导出的 parse_mappings WebAssembly 函数,并将任何错误转换为 Error,并将其 throw 出去。
const mappingsPtr = this._wasm.exports.parse_mappings(mappingsBufPtr);
if (!mappingsPtr) {
const error = this._wasm.exports.get_last_error();
let msg = `Error parsing mappings (code ${error}): `;
// XXX: keep these error codes in sync with `fitzgen/source-map-mappings`.
switch (error) {
case 1:
msg += "the mappings contained a negative line, column, source index or name index";
break;
case 2:
msg += "the mappings contained a number larger than 2**32";
break;
case 3:
msg += "reached EOF while in the middle of parsing a VLQ";
break;
case 4:
msg += "invalid base 64 character while parsing a VLQ";
break
default:
msg += "unknown error code";
break;
}
throw new Error(msg);
}
this._mappingsPtr = mappingsPtr;
调用 WebAssembly 的各种查询方法具有类似的结构,就像 Rust 侧的导出函数一样。它们验证查询参数,使用 withMappingCallback 设置一个临时映射回调闭包以聚合结果,调用 WebAssembly,然后返回结果。
以下是 JavaScript 中 allGeneratedPositionsFor 的样子。
BasicSourceMapConsumer.prototype.allGeneratedPositionsFor = function ({
source,
line,
column,
}) {
const hasColumn = column === undefined;
column = column || 0;
source = this._findSourceIndex(source);
if (source < 0) {
return [];
}
if (originalLine < 1) {
throw new Error("Line numbers must be >= 1");
}
if (originalColumn < 0) {
throw new Error("Column numbers must be >= 0");
}
const results = [];
this._wasm.withMappingCallback(
m => {
let lastColumn = m.lastGeneratedColumn;
if (this._computedColumnSpans && lastColumn === null) {
lastColumn = Infinity;
}
results.push({
line: m.generatedLine,
column: m.generatedColumn,
lastColumn,
});
}, () => {
this._wasm.exports.all_generated_locations_for(
this._getMappingsPtr(),
source,
line,
hasColumn,
column
);
}
);
return results;
};
当 JavaScript 完成对源映射的查询后,库使用者应调用 SourceMapConsumer.prototype.destroy,然后调用导出的 free_mappings WebAssembly 函数。
BasicSourceMapConsumer.prototype.destroy = function () {
if (this._mappingsPtr !== 0) {
this._wasm.exports.free_mappings(this._mappingsPtr);
this._mappingsPtr = 0;
}
};
基准测试
所有测试都在 2014 年中期配备 2.8 GHz Intel Core i7 处理器和 16 GB 1600 MHz DDR3 内存的 MacBook Pro 上执行。笔记本电脑在每次测试中都插着电源,并在测试之间刷新了基准网页。测试在 Chrome Canary 65.0.3322.0、Firefox Nightly 59.0a1(2018-01-15)和 Safari 11.0.2(11604.4.7.1.6)3 中执行。对于每个基准测试,为了预热浏览器的 JIT 编译器,我们在收集计时数据之前执行了五次迭代。预热后,我们记录了 100 次迭代的计时数据。
我们在基准测试中使用了各种输入源映射。我们使用了在野外找到的三个不同大小的源映射
- 原始 JavaScript 实现的
source-map库的 最小化到未最小化的源映射。此源映射由 UglifyJS 创建,其"mappings"字符串长 30,081 个字符。 -
最新 Angular.JS 的最小化到未最小化的源映射。此源映射的
"mappings"字符串长 391,473 个字符。 -
Scala.JS 运行时的 Scala 到 JavaScript 源映射。此源映射是最大的,其
"mappings"字符串长 14,964,446 个字符。
此外,我们使用两个更多的人工构建的源映射来扩充输入集
- Angular.JS 源映射膨胀到其原始大小的十倍。这会导致
"mappings"字符串的大小为 3,914,739。 -
Scala.JS 源映射膨胀到其原始大小的两倍。这会导致
"mappings"字符串的大小为 29,928,893。对于此输入源映射,我们仅在每个基准测试上收集了 40 次迭代。
敏锐的读者会注意到膨胀的源映射大小分别额外增加了 9 个字符和 1 个字符。这些来自将原始 "mappings" 字符串粘贴在一起以创建膨胀版本时,每个原始 "mappings" 字符串之间的 ; 分隔符。
我们将特别关注 Scala.JS 源映射。它是我们测试过的最大的非人工源映射。此外,它是我们拥有所有浏览器和库实现组合测量数据的最大源映射。Chrome 上没有最大输入(Scala.JS 源映射膨胀到两倍)的数据。使用 JavaScript 实现,我们无法对这种组合进行任何测量,因为没有一个基准测试可以在不使标签的内容进程崩溃的情况下完成。使用 WebAssembly 实现,Chrome 会错误地抛出 RuntimeError: memory access out of bounds。使用 Chrome 的调试器,假设的越界访问发生在一个不存在于 .wasm 文件中的指令序列中。所有其他浏览器的 WebAssembly 实现都成功地使用此输入运行了基准测试,因此我倾向于认为这是 Chrome 实现中的一个错误。
对于所有基准测试,较低的值越好。
首次设置断点
第一个基准测试模拟了一个单步调试器第一次在原始源中的某一行设置断点。这需要解析源映射的 "mappings" 字符串,并按其原始源位置对解析后的映射进行排序,以便我们可以二分搜索到断点行的映射。查询返回与原始源行上的任何映射相对应的每个生成的 JavaScript 位置。
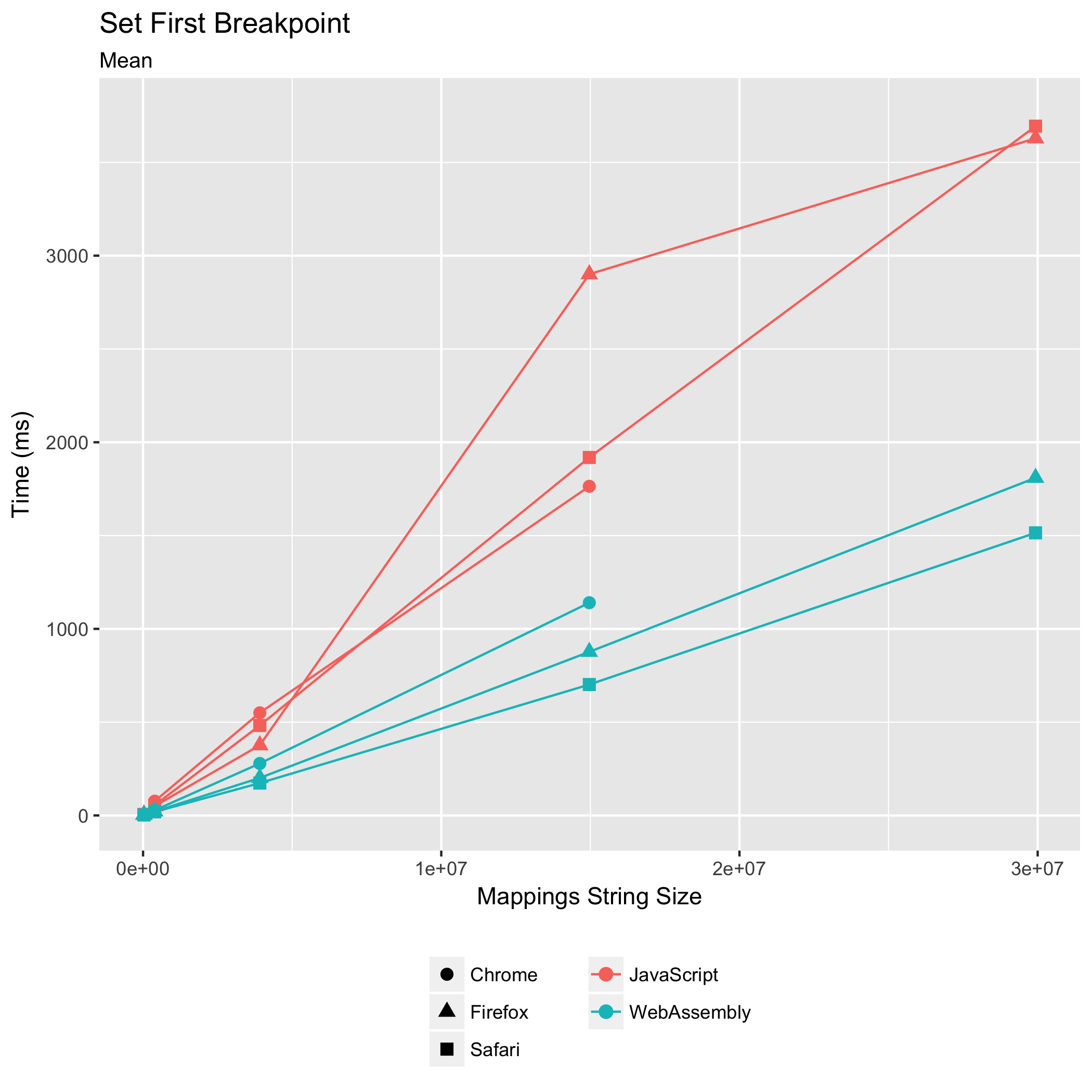
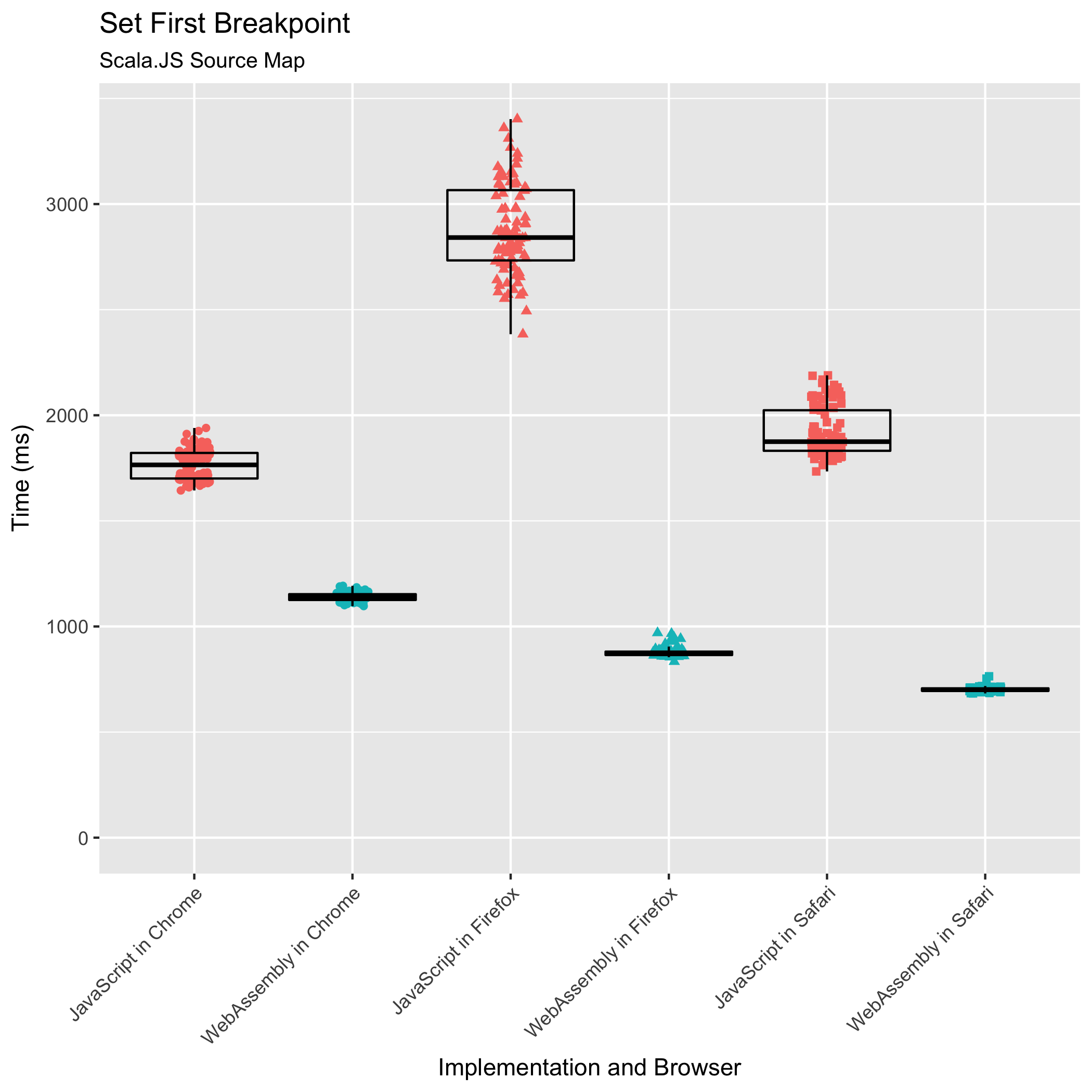
WebAssembly 实现优于其 JavaScript 对应物,在所有浏览器中都是如此。对于 Scala.JS 源映射,WebAssembly 实现所花费的时间是其 JavaScript 对应物在 Chrome 中花费时间的 0.65 倍,在 Firefox 中花费时间的 0.30 倍,在 Safari 中花费时间的 0.37 倍。WebAssembly 实现在 Safari 中最快,平均耗时 702 毫秒,而 Chrome 耗时 1140 毫秒,Firefox 耗时 877 毫秒。
此外,WebAssembly 实现的 相对标准偏差 比 JavaScript 实现更窄,尤其是在 Firefox 中。对于 Scala.JS 源映射,JavaScript 实现的相对标准偏差在 Chrome 中为 ±4.07%,在 Firefox 中为 ±10.52%,在 Safari 中为 ±6.02%。在 WebAssembly 中,这些偏差缩小到 Chrome 中的 ±1.74%,Firefox 中的 ±2.44% 和 Safari 中的 ±1.58%。
首次在异常处暂停
第二个基准测试演练了第一次使用生成的 JavaScript 位置查找其对应原始源位置的代码路径。当单步调试器在来自生成的 JavaScript 代码内部的未捕获异常处暂停时,当从生成的 JavaScript 代码内部记录控制台消息时,或者当从其他 JavaScript 源进入生成的 JavaScript 代码时,就会发生这种情况。
要将生成的 JavaScript 位置转换为原始源位置,必须解析 "mappings" 字符串。然后,必须按生成的 JavaScript 位置对解析后的映射进行排序,以便我们可以对最接近的映射进行二进制搜索,最后返回最接近的映射的原始源位置。
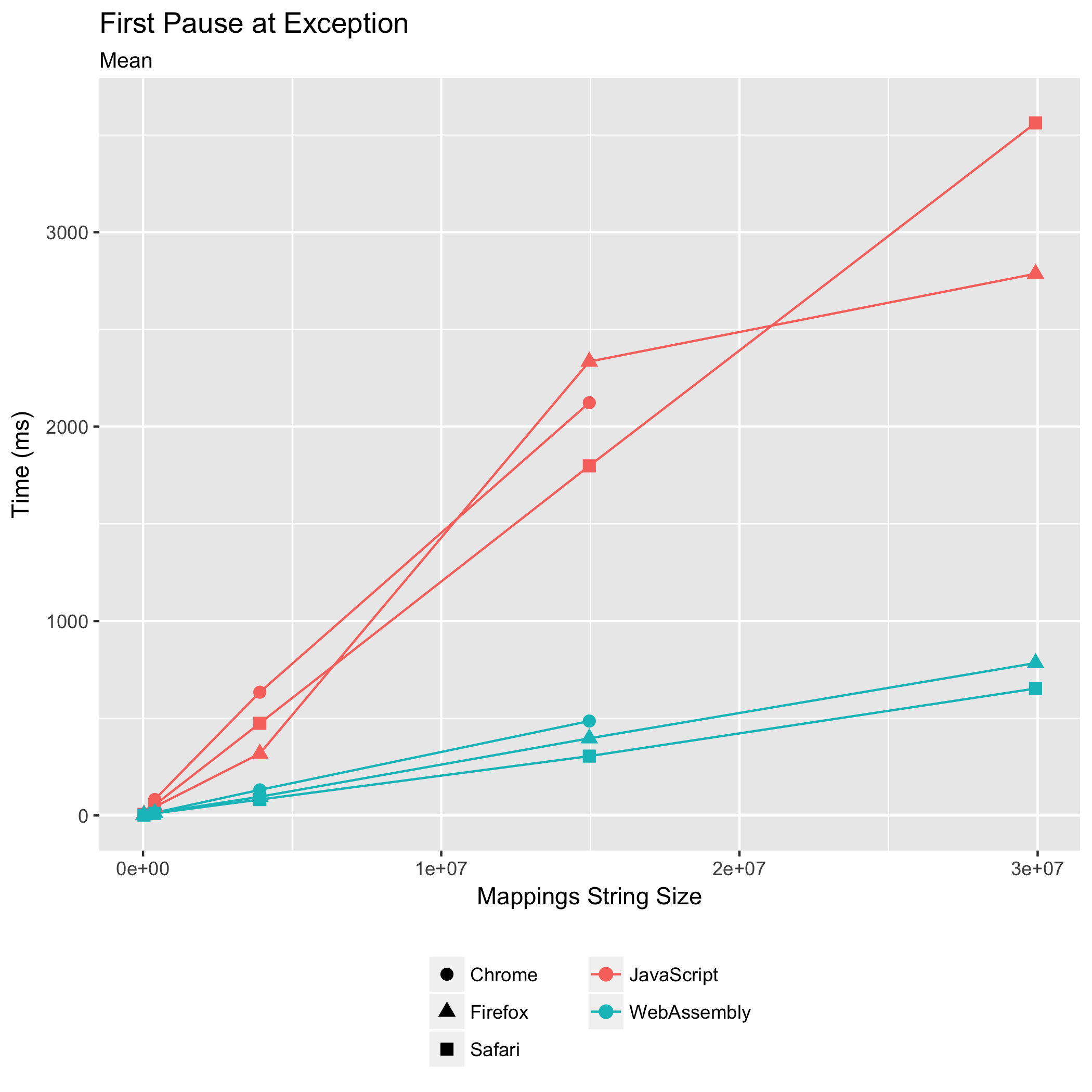
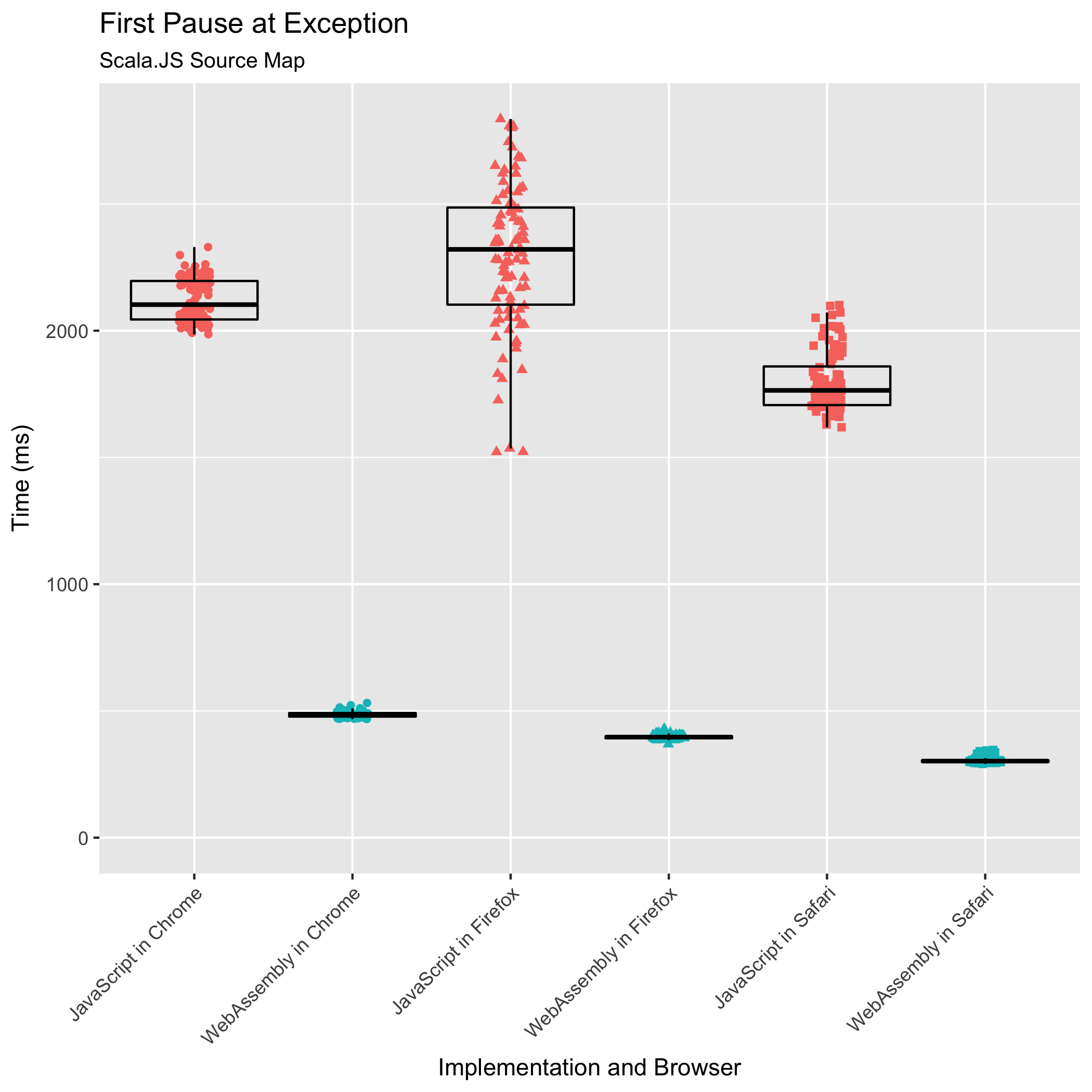
再次,WebAssembly 实现胜过所有浏览器中的 JavaScript 实现——这次的优势更大。使用 Scala.JS 源映射,在 Chrome 中,WebAssembly 实现的执行时间是 JavaScript 实现执行时间的 0.23 倍。在 Firefox 和 Safari 中,WebAssembly 的执行时间分别是 JavaScript 执行时间的 0.17 倍。再次,Safari 以最快的速度运行 WebAssembly(305 毫秒),其次是 Firefox(397 毫秒),然后是 Chrome(486 毫秒)。
WebAssembly 实现再次比 JavaScript 实现更安静。对于 Scala.JS 源映射输入,Chrome 的相对标准差从 ±4.04% 降至 ±2.35±%,Firefox 的从 ±13.75% 降至 ±2.03%,Safari 的从 ±6.65% 降至 ±3.86%。
后续断点和异常暂停
第三和第四个基准测试观察了在第一个断点之后设置后续断点,或在后续未捕获的异常处暂停,或翻译后续日志消息位置所需的时间。从历史上看,这些操作从未成为性能瓶颈:昂贵的部分是初始的 "mappings" 字符串解析以及可查询数据结构(排序数组)的构建。
但是,我们希望确保它保持这种状态:我们不希望这些操作突然变得很昂贵。
这两个基准测试都衡量了对目标位置最接近的映射进行二进制搜索并返回该映射的共置所需的时间。
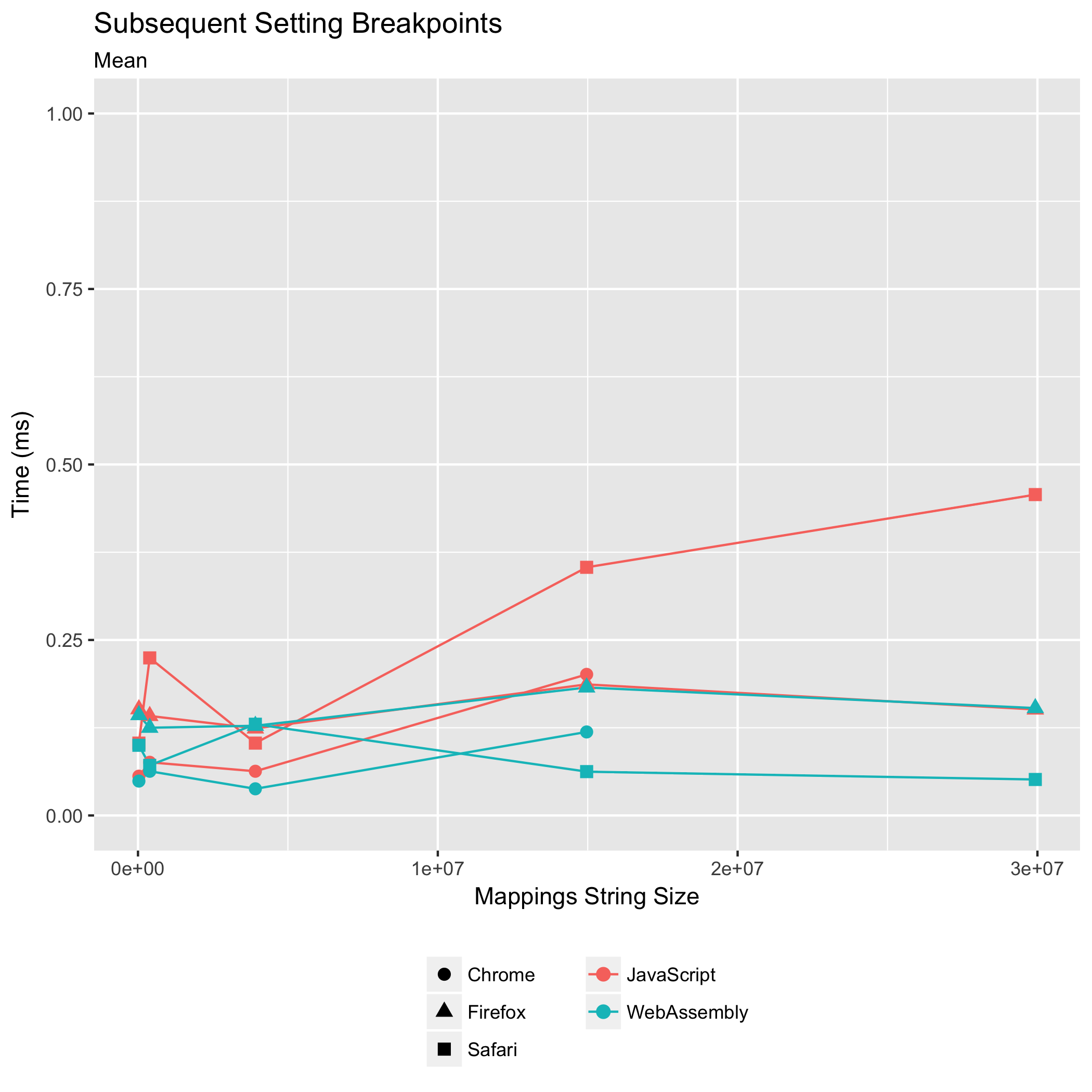
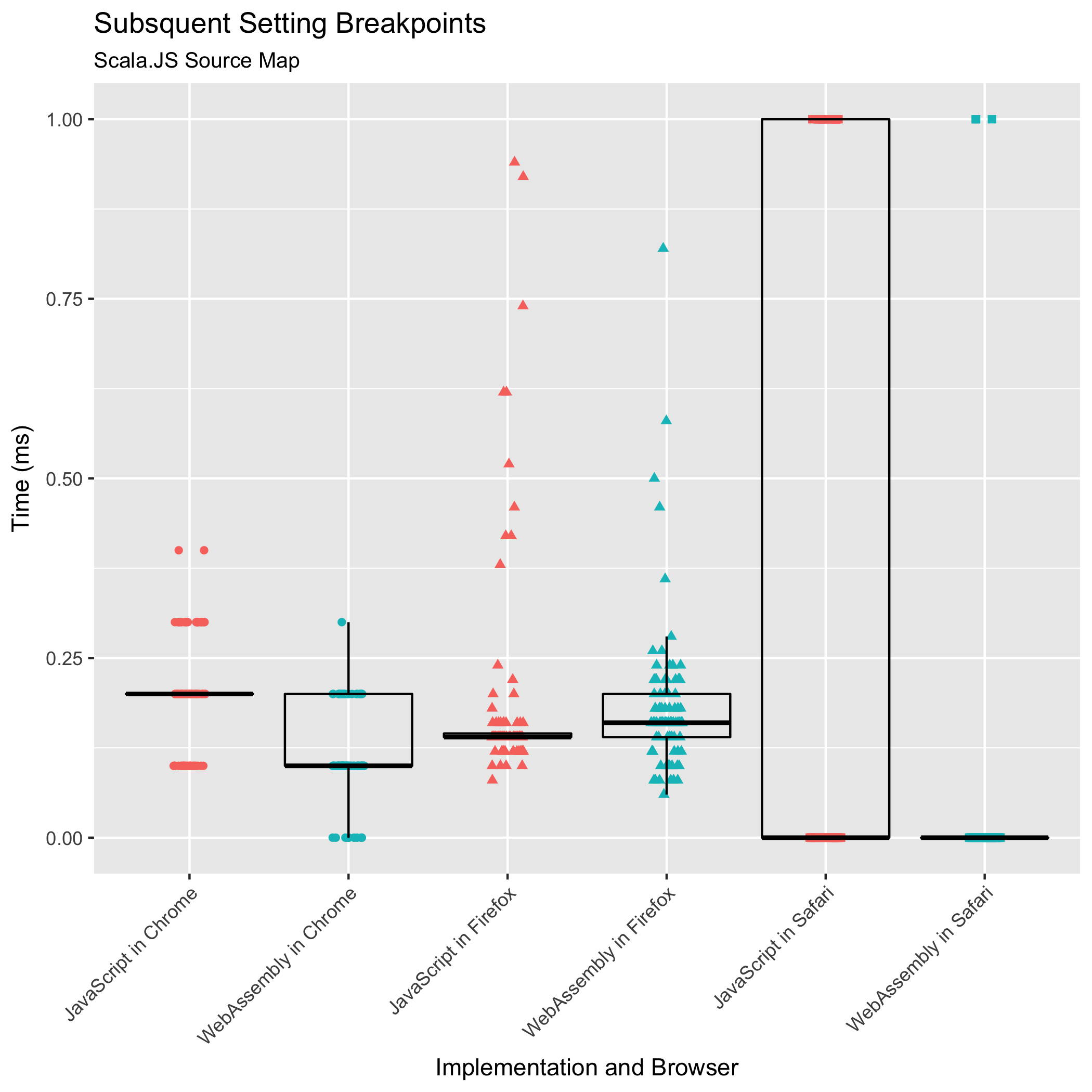
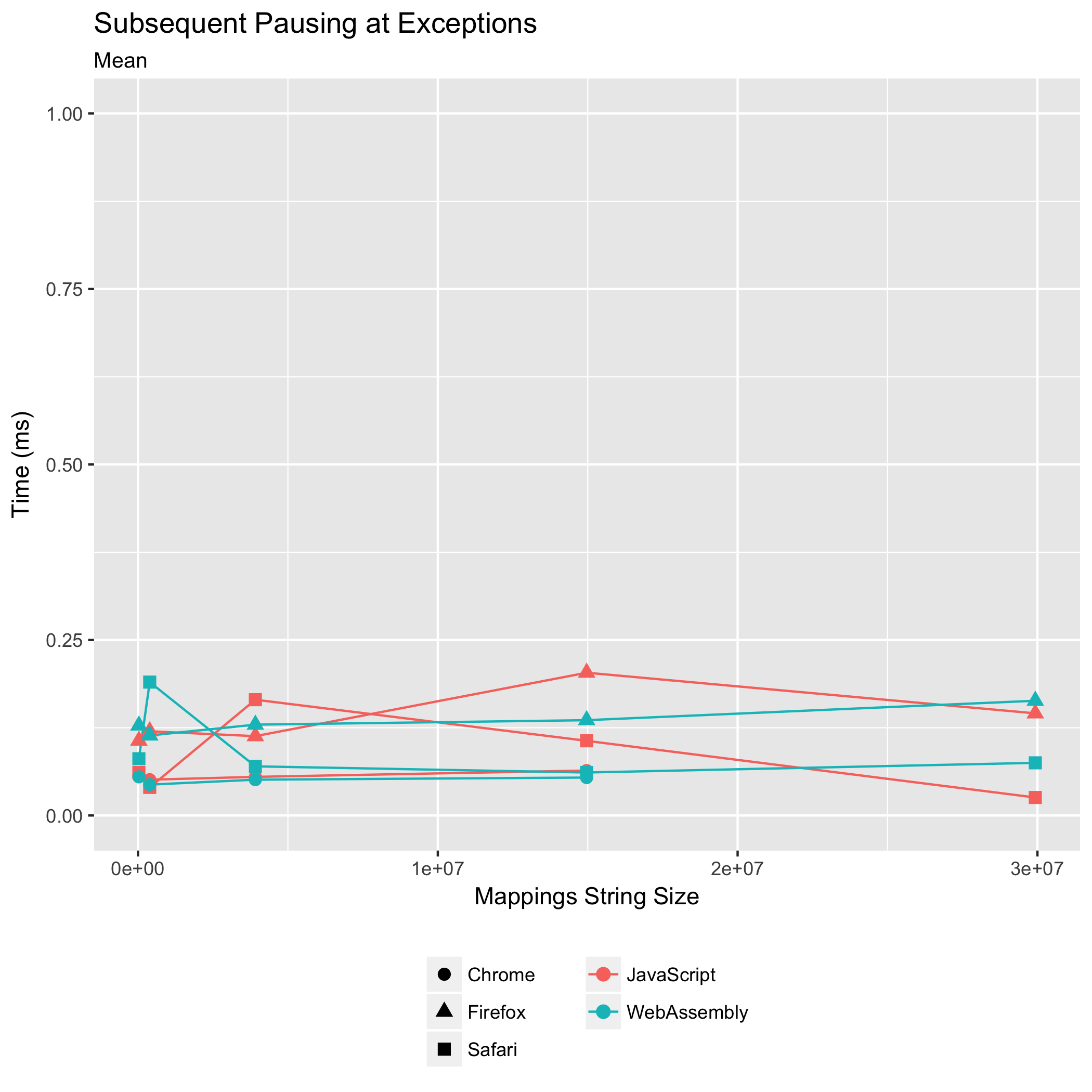
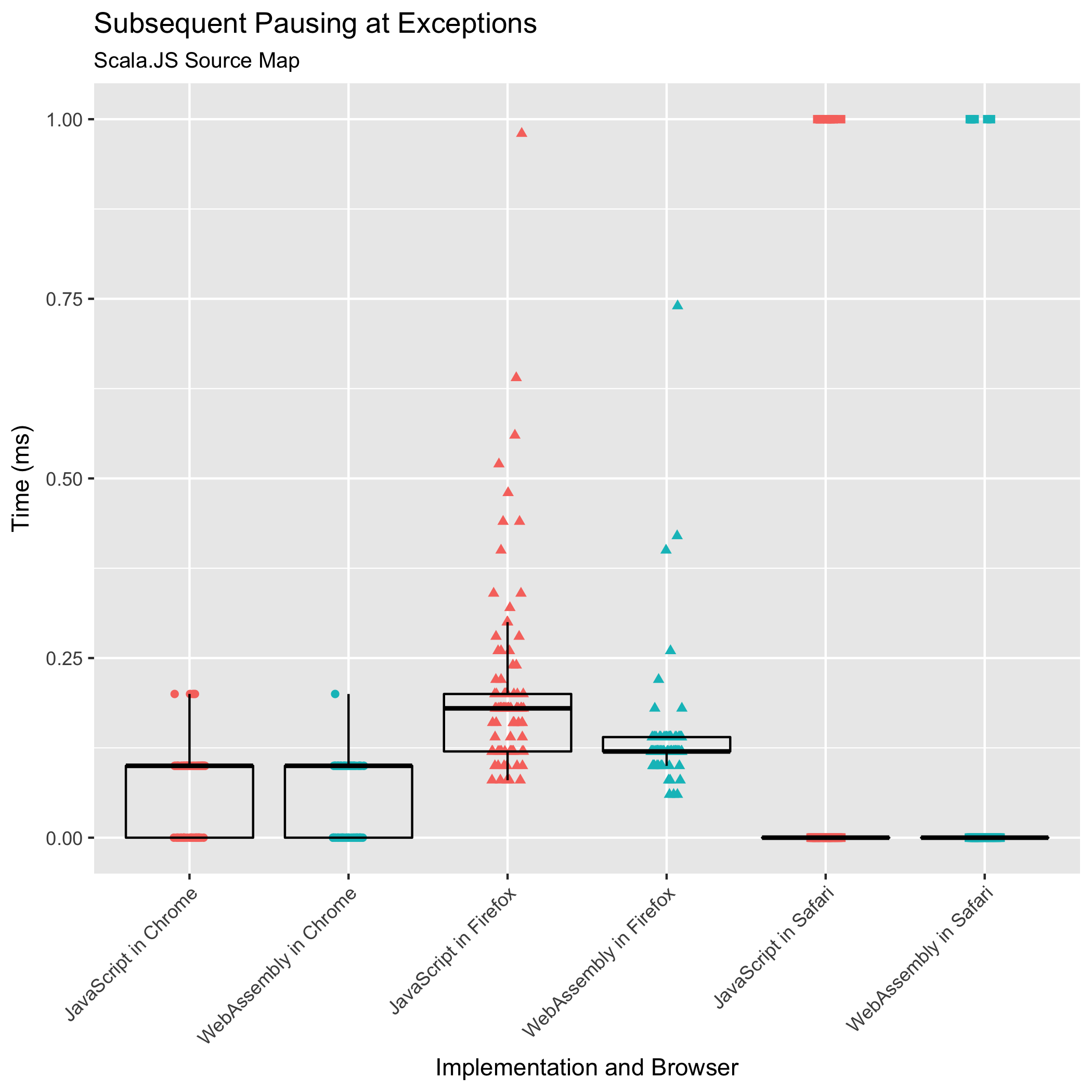
这些基准测试结果应该比其他基准测试结果更谨慎地对待。从 Scala.JS 源映射输入的两张图中,我们看到明显的层状结构。这种分层现象是由于基准测试操作的运行时间非常短,以至于我们计时器的分辨率变得可见。我们可以看到,Chrome 公开了分辨率为十分之一毫秒的计时器,Firefox 公开了分辨率为 0.02 毫秒的计时器,而 Safari 公开了毫秒分辨率的计时器。
根据这些数据,我们只能得出结论,后续查询在 JavaScript 和 WebAssembly 实现中仍然主要保持亚毫秒级操作。后续查询从未成为性能瓶颈,并且在新的 WebAssembly 实现中也没有成为瓶颈。
遍历所有映射
最后两个基准测试测量了解析源映射并立即遍历其映射,以及遍历已解析的源映射的映射所需的时间。这些是构建工具在组合或使用源映射时执行的常见操作。它们有时也会由逐步调试器执行,以突出显示用户可以在原始源中的哪些行设置断点——在不转换为生成 JavaScript 中任何位置的行上设置断点是没有意义的。
这个基准测试是我们担心的一个:它涉及最多的 JavaScript↔WebAssembly 边界跨越,对于源映射中的每个映射,都会进行一个 FFI 调用。对于所有其他测试的基准测试,我们的设计将此类 FFI 调用的数量降至最低。
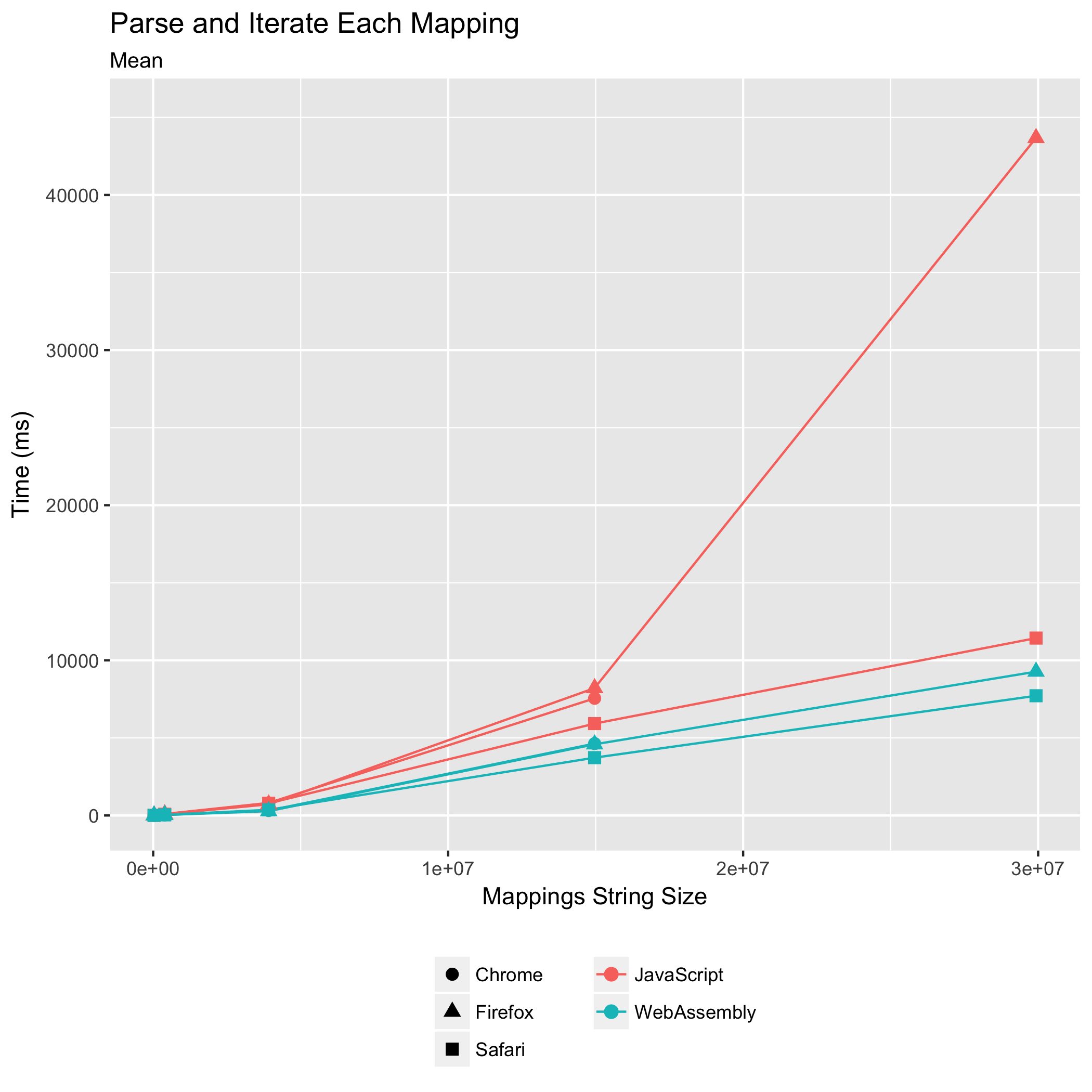
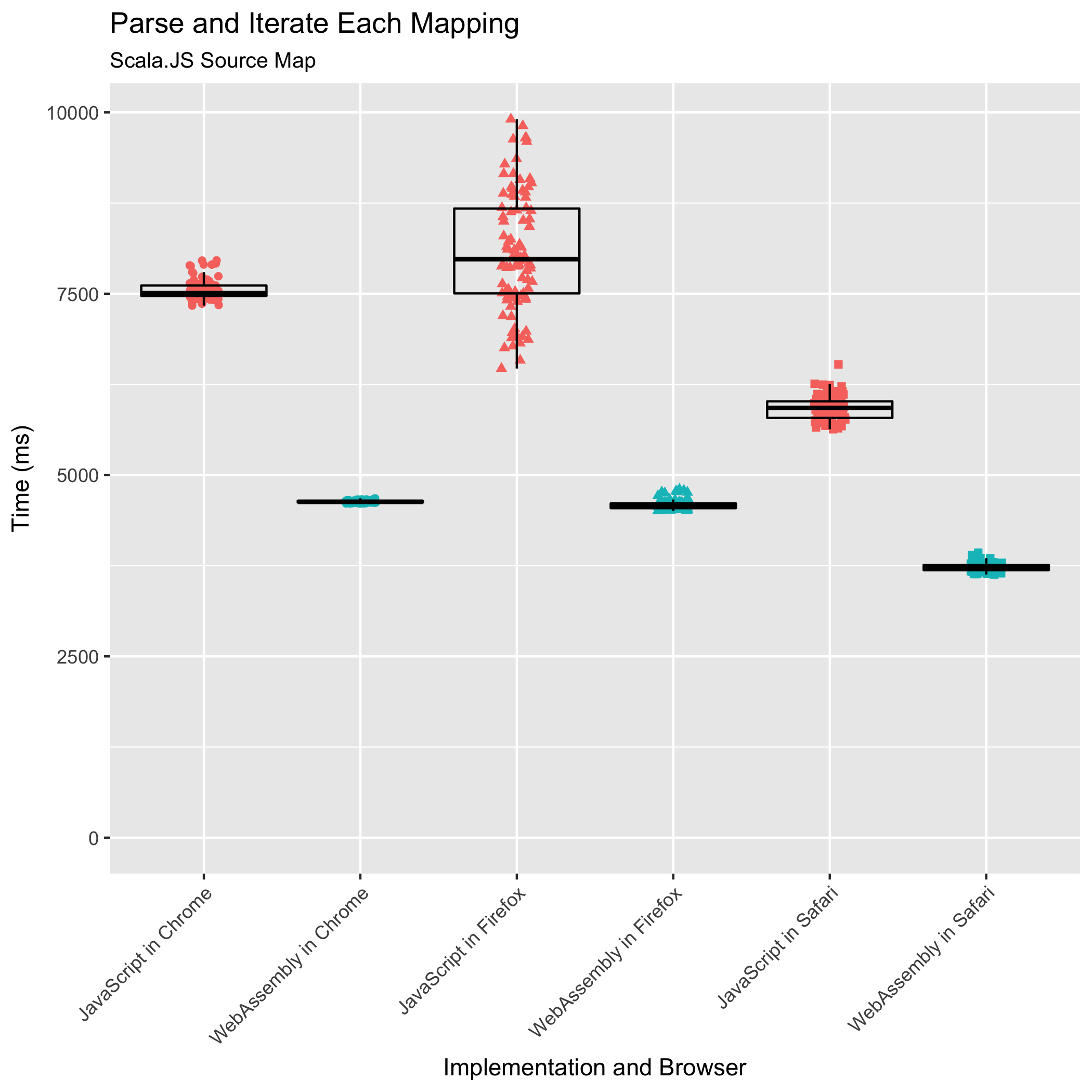
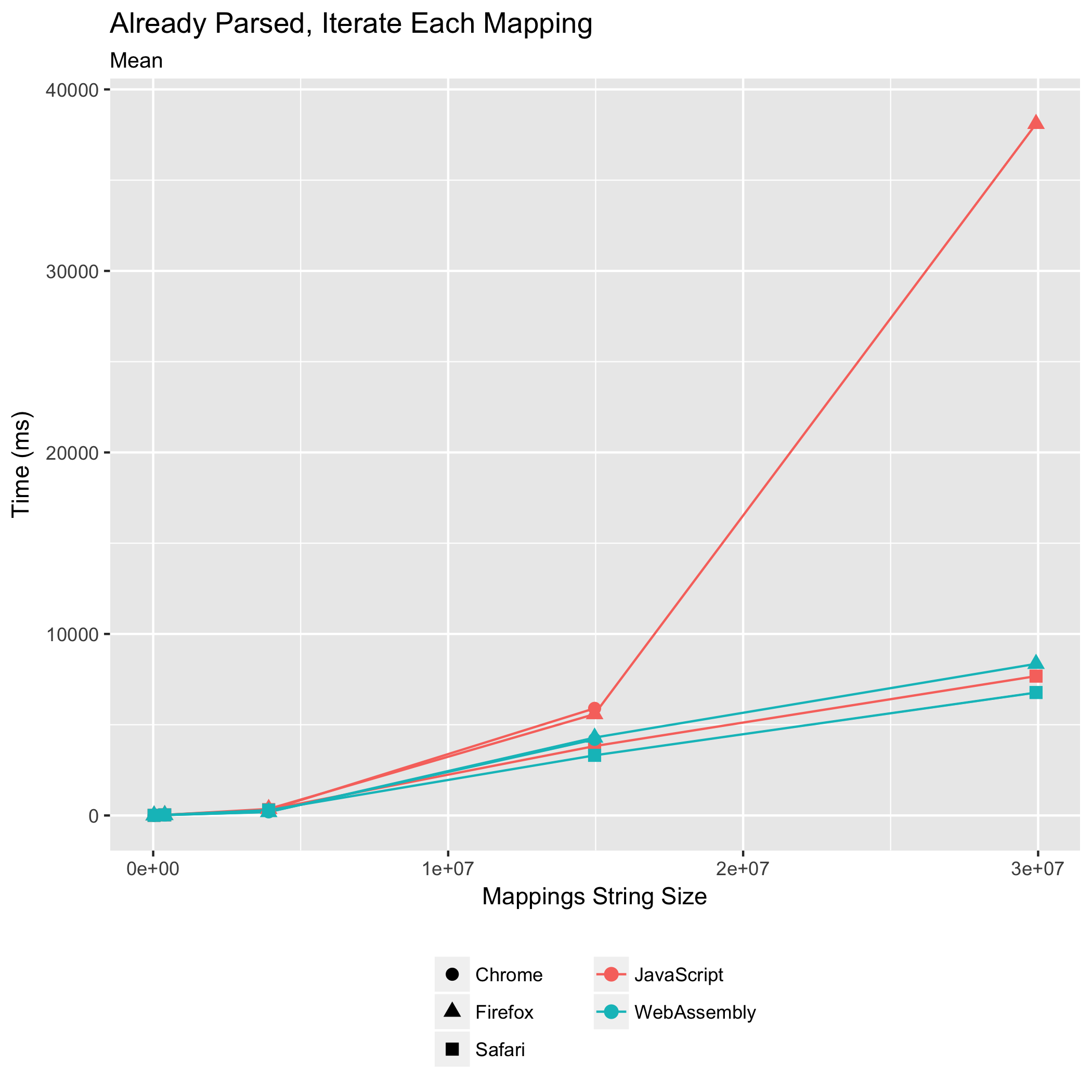
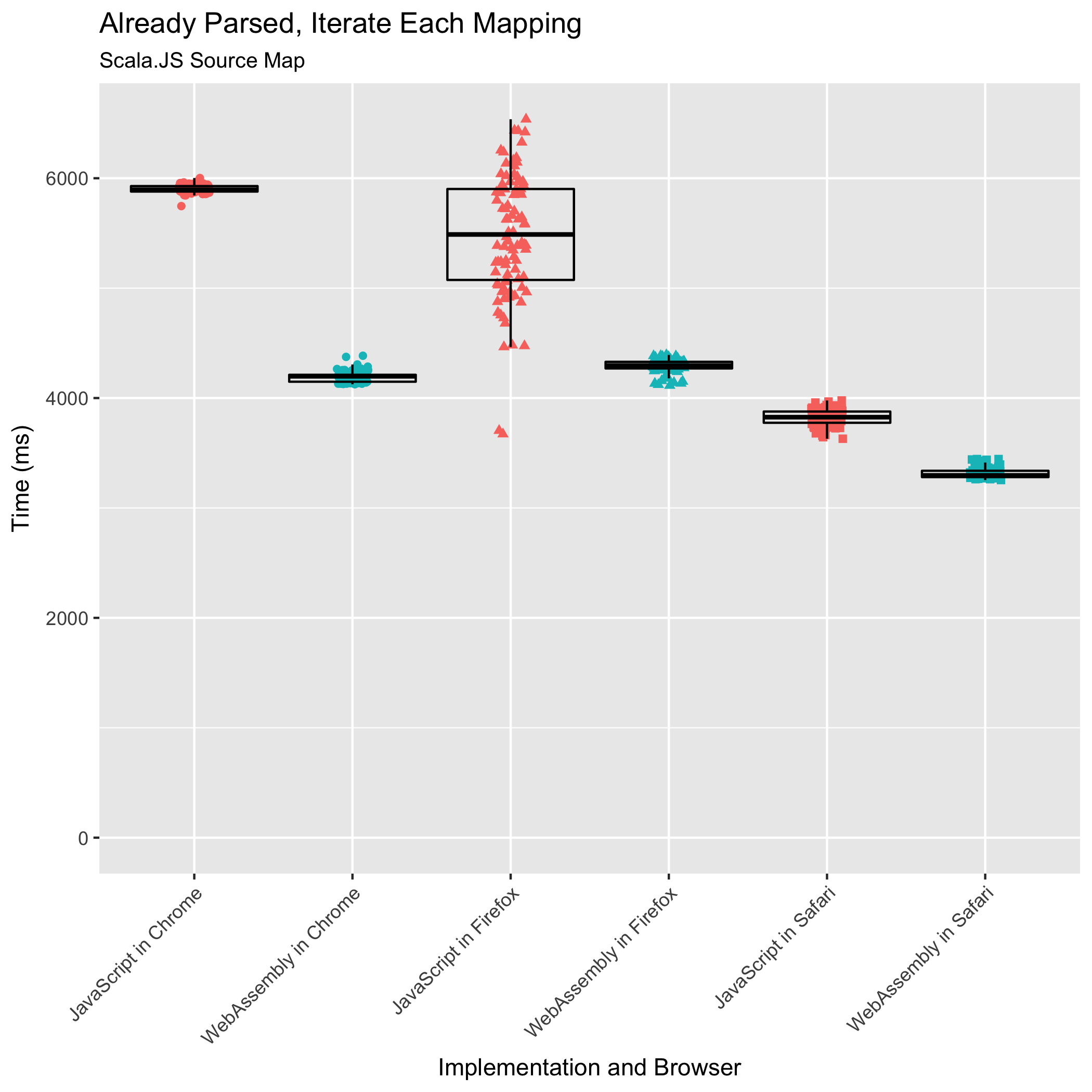
事实证明,我们的担忧是多余的。WebAssembly 实现不仅满足了 JavaScript 实现的性能,即使源映射已经解析,它也超越了 JavaScript 实现的性能。对于解析和遍历以及已解析遍历的基准测试,WebAssembly 在 Chrome 中分别花费了 JavaScript 时间的 0.61 倍和 0.71 倍。在 Firefox 中,WebAssembly 分别花费了 JavaScript 时间的 0.56 倍和 0.77 倍。在 Safari 中,WebAssembly 实现花费了 JavaScript 实现时间的 0.63 倍和 0.87 倍。再次,Safari 以最快的速度运行 WebAssembly 实现,而 Firefox 和 Chrome 基本上并列第二。Safari 在已解析遍历基准测试上的 JavaScript 性能值得特别认可:除了超越其他浏览器 JavaScript 的执行时间外,Safari 的 JavaScript 执行速度还快于其他浏览器运行 WebAssembly 的速度!
与早期的基准测试趋势相符,我们还看到 WebAssembly 相比 JavaScript 实现的相对标准差有所降低。在解析和遍历时,Chrome 的相对标准差从 ±1.80% 降至 ±0.33%,Firefox 的从 ±11.63% 降至 ±1.41%,Safari 的从 ±2.73% 降至 ±1.51%。在遍历已解析的源映射的映射时,Firefox 的相对标准差从 ±12.56% 降至 ±1.40%,Safari 的从 ±1.97% 降至 ±1.40%。Chrome 的相对标准差从 ±0.61% 上升到 ±1.18%,使其成为唯一一个打破趋势的浏览器,但仅针对此基准测试。
代码大小
wasm32-unknown-unknown 目标相对于 wasm32-unknown-emscripten 目标的一个优势是它生成的 WebAssembly 代码更精简。wasm32-unknown-emscripten 目标包含了大多数 libc 的 polyfill 以及基于 IndexedDB 构建的文件系统,等等,但 wasm32-unknown-unknown 却没有。在 source-map 库中,我们只使用了 wasm32-unknown-unknown。
我们考虑传递给客户端的 JavaScript 和 WebAssembly 的代码大小。也就是说,我们关注的是将 JavaScript 模块捆绑到单个 .js 文件后的代码大小。我们查看使用 wasm-gc、wasm-snip 和 wasm-opt 缩减 .wasm 文件大小的效果,以及使用 gzip 压缩的效果,gzip 压缩在 Web 上得到了普遍支持。
在这些测量中,报告的 JavaScript 大小始终是使用 Google Closure Compiler 在“简单”优化级别下创建的最小化 JavaScript 的大小。我们使用 Closure Compiler 是因为 UglifyJS 不支持我们引入的一些较新的 ECMAScript 形式(例如 let 和箭头函数)。我们使用“简单”优化级别是因为“高级”优化级别对于没有为 Closure Compiler 编写而设计的 JavaScript 来说具有破坏性。
标记为“JavaScript”的条形图表示原始的纯 JavaScript source-map 库实现的变体。标记为“WebAssembly”的条形图表示新的 source-map 库实现的变体,该实现使用 WebAssembly 来解析 "mappings" 字符串并查询解析后的映射。请注意,“WebAssembly”实现仍然使用 JavaScript 来执行所有其他功能!source-map 库具有其他功能,例如生成源映射,这些功能仍然在 JavaScript 中实现。对于“WebAssembly”实现,我们报告了 WebAssembly 和 JavaScript 的大小。
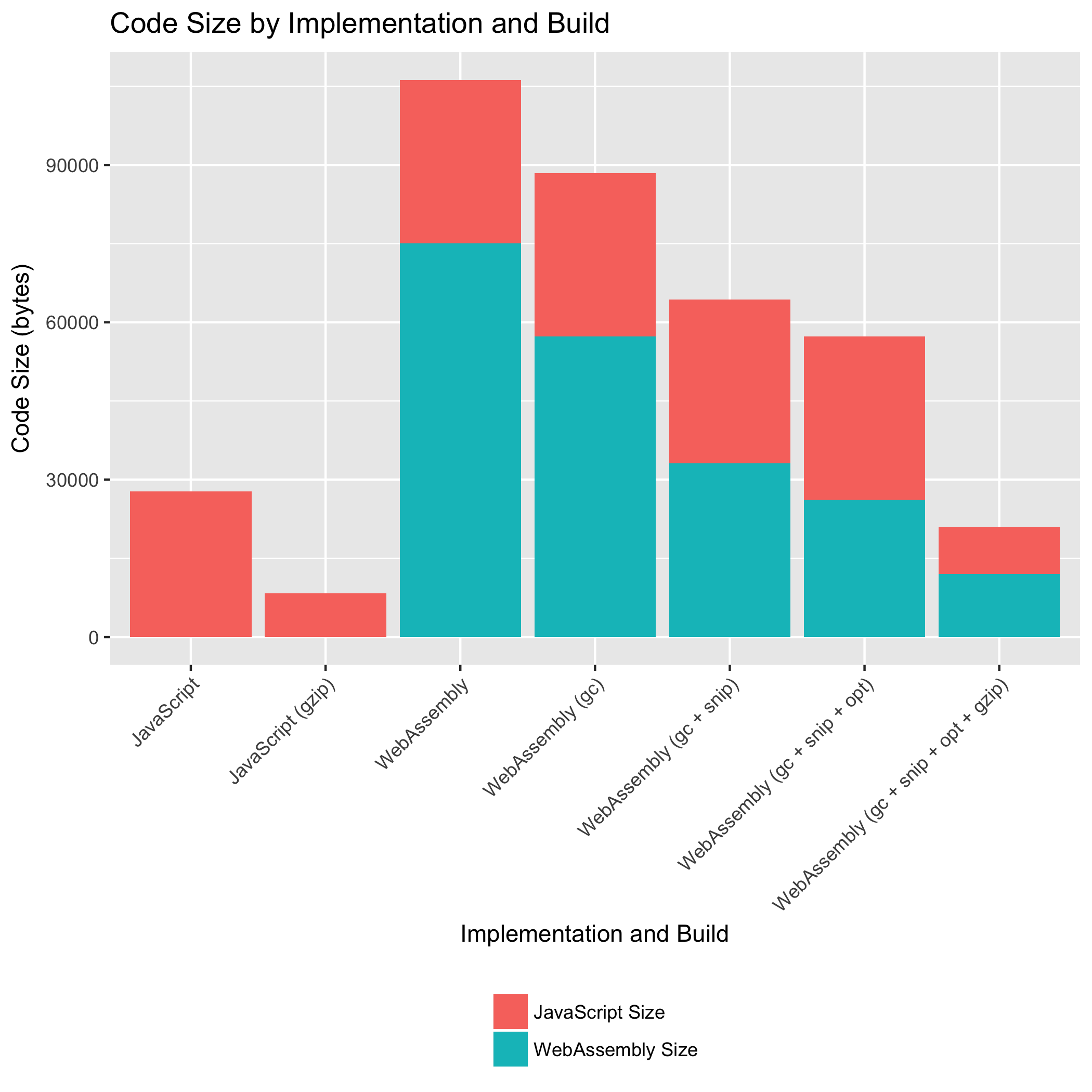
在最小的情况下,新的 WebAssembly 实现的总代码大小大于旧的 JavaScript 实现:分别为 20,996 字节和 8,365 字节。但是,通过使用用于缩减 .wasm 大小的工具,我们将 WebAssembly 的大小缩减到了其原始大小的 0.16 倍。两种实现的 JavaScript 代码量相似。
如果我们将 JavaScript 解析和查询代码替换为 WebAssembly,为什么 WebAssembly 实现不包含更少的 JavaScript 代码?有两个因素导致 JavaScript 代码大小没有减少。首先,有一些少量的新 JavaScript 代码被引入来加载 .wasm 文件并与 WebAssembly 交互。其次,也是更重要的是,我们“替换”的一些 JavaScript 例程以前与 source-map 库的其他部分共享。现在,虽然这些例程不再共享,但它们仍然被库的这些其他部分使用。
让我们将注意力转向导致预 gzip 化 .wasm 文件大小的原因。运行 wasm-objdump -h 会给出每个部分的大小
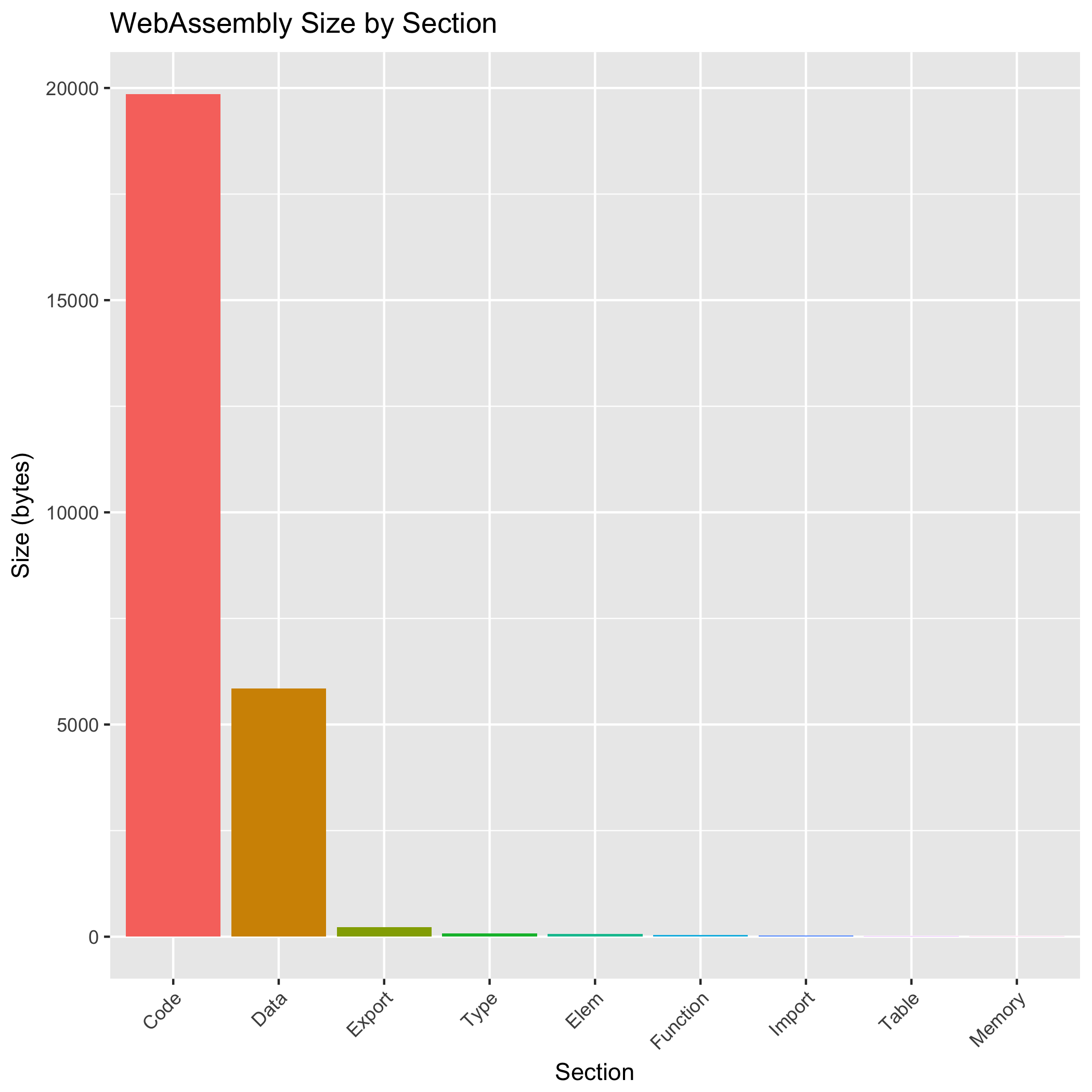
Code 和 Data 部分实际上占用了整个 .wasm 文件的大小。Code 部分包含编码的 WebAssembly 指令,这些指令构成了函数体。Data 部分由要加载到 WebAssembly 模块线性内存空间中的静态数据组成。
使用 wasm-objdump 手动检查 Data 部分的内容表明,它主要由字符串片段组成,这些片段用于在 Rust 代码出现恐慌时构建诊断消息。但是,当以 WebAssembly 为目标时,Rust 恐慌会转换为 WebAssembly 陷阱,而陷阱不会携带额外的诊断信息。我们认为这些字符串片段甚至被发射出来是一个 rustc 中的错误。不幸的是,wasm-gc 目前也无法删除未使用的 Data 段,所以我们暂时只能忍受这种膨胀。WebAssembly 及其工具仍然相对不成熟,我们预计工具链在这方面会随着时间的推移而改进。
接下来,我们后处理 wasm-objdump 的反汇编输出,计算 Code 部分中每个函数体的尺寸,并按 Rust crate 分组尺寸
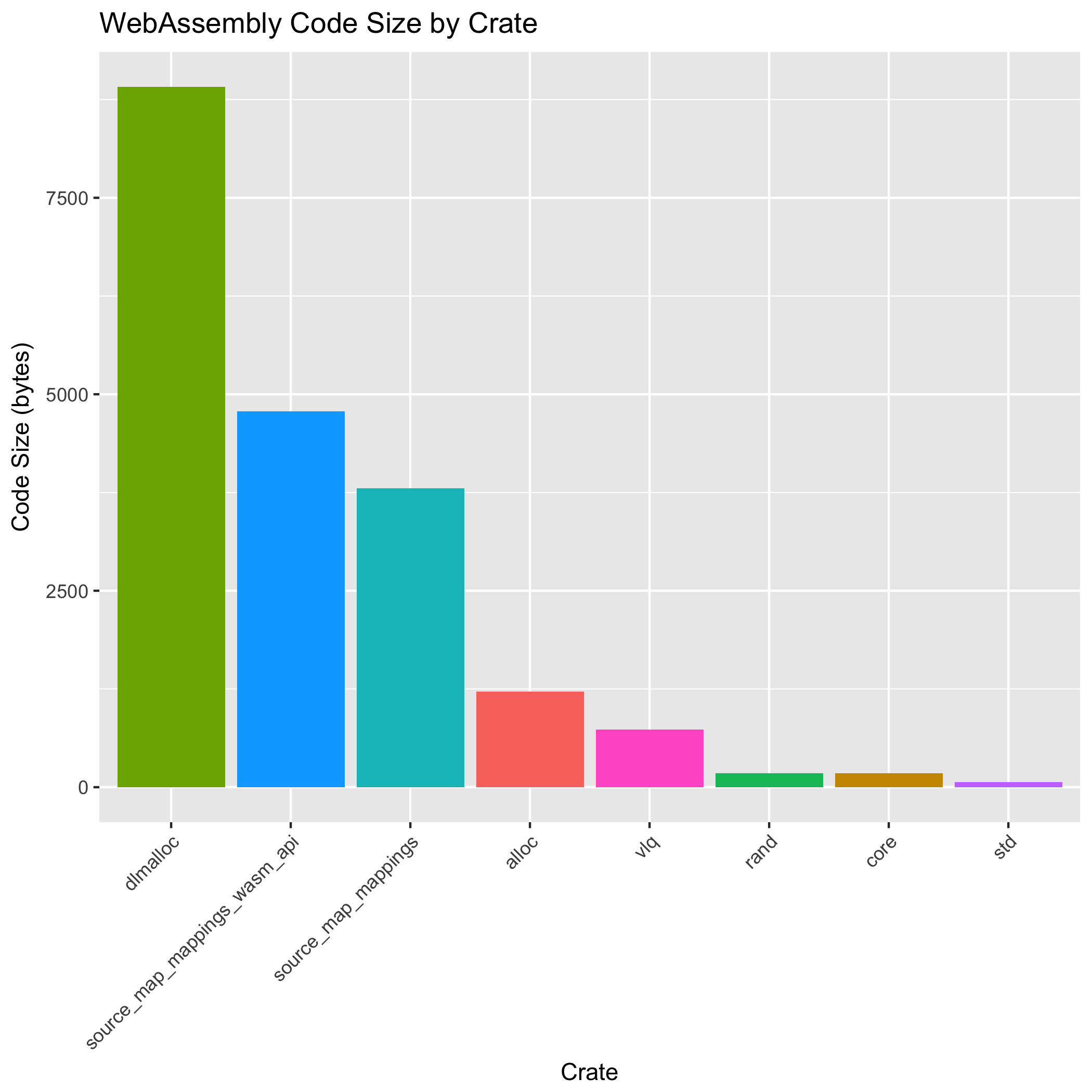
最重的 crate 是 dlmalloc,它由 alloc crate 使用,alloc crate 实现 Rust 的低级分配 API。dlmalloc 和 alloc 共同占用了 10,126 字节,占总函数大小的 50.98%。从某种意义上说,这令人宽慰:分配器的代码大小是一个常数,不会随着我们将更多 JavaScript 代码移植到 Rust 而增长。
我们编写的 crate(vlq、source_map_mappings 和 source_map_mappings_wasm_api)的代码大小之和为 9,320 字节,占总函数大小的 46.92%。这使得其他 crate 只占用了 417 字节(2.10%)的空间。这体现了 wasm-gc、wasm-snip 和 wasm-opt 的有效性:虽然像 std 这样的 crate 比我们的 crate 大得多,但我们只使用了其 API 的一小部分,我们只为我们使用的部分付费。
结论和未来工作
用 Rust 和 WebAssembly 重写源映射解析和查询中最敏感的性能部分已经取得了成功。在我们的基准测试中,WebAssembly 实现的执行时间是原始 JavaScript 实现的执行时间的几分之一——低至 0.17 倍。我们观察到,对于所有浏览器,WebAssembly 实现都比 JavaScript 实现快。此外,WebAssembly 实现提供了更一致、更可靠的性能:与 JavaScript 实现相比,迭代之间的相对标准差显着下降。
为了提高性能,JavaScript 实现积累了复杂的代码,我们用惯用的 Rust 代码替换了它。Rust 不会强迫我们在清晰地表达意图和运行时性能之间做出选择。
也就是说,我们还有更多工作要做。
最紧迫的下一步是调查为什么 Rust 标准库的排序速度不如我们的自定义快速排序算法,当以 WebAssembly 为目标时。这是重写中唯一不惯用的 Rust 代码。这种行为令人惊讶,因为我们的快速排序实现很简单,而标准库的快速排序是模式击败的,并为小范围和几乎排序的范围使用插入排序。事实上,当以本机代码为目标时,标准库的排序例程确实比我们的快。我们推测内联启发式方法在目标之间有所改变,并且当以 WebAssembly 为目标时,我们的比较器函数没有被内联到标准库的排序例程中。这需要进一步调查。
我们发现 WebAssembly 的大小分析比必要更难。为了获得有意义地呈现的有用信息,我们被迫编写了 我们自己的自制脚本来后处理 wasm-objdump。该脚本构建了调用图,并允许我们查询某个函数的调用者是谁,帮助我们理解为什么函数被发射到 .wasm 文件中,即使我们没有预料到它会被发射。它非常笨拙,并且没有公开有关内联函数的信息。一个合适的 WebAssembly 大小分析器会有所帮助,并且会为我们之后的任何人提供帮助。
分配器相对较大的代码大小占用空间表明,编写或调整专注于代码大小微小的分配器可以为 WebAssembly 生态系统提供相当大的效用。至少对于我们的用例而言,分配器性能不是问题,我们只进行少量动态分配。对于分配器,我们会毫不犹豫地选择代码大小而不是性能。
我们 Data 部分中未使用的段突出了对 wasm-gc 或其他工具的需求,以检测和删除从未引用的静态数据。
对于库的下游用户,我们仍然可以对 JavaScript API 进行一些改进。在当前实现中引入 WebAssembly 需要在用户完成解析映射后手动释放它。对于大多数习惯于依赖垃圾回收器并且通常不考虑任何特定对象生命周期的 JavaScript 程序员来说,这并不自然。我们可以引入一个 SourceMapConsumer.with 函数,它接受一个原始的、未解析的源映射和一个 async 函数。with 函数将构造一个 SourceMapConsumer 实例,使用它调用 async 函数,然后在 async 函数调用完成后在 SourceMapConsumer 实例上调用 destroy。这就像 JavaScript 的 async RAII。
SourceMapConsumer.with = async function (rawSourceMap, f) {
const consumer = await new SourceMapConsumer(rawSourceMap);
try {
await f(consumer);
} finally {
consumer.destroy();
}
};
另一种使 API 更易于 JavaScript 程序员使用的替代方法是为每个 SourceMapConsumer 提供其自己的 WebAssembly 模块实例。然后,因为 SourceMapConsumer 实例将拥有对其 WebAssembly 模块实例的唯一 GC 边缘,我们可以让垃圾回收器管理所有 SourceMapConsumer 实例、WebAssembly 模块实例和模块实例的堆。使用此策略,我们将在 Rust WebAssembly 粘合代码中有一个 static mut MAPPINGS: Mappings,并且 Mappings 实例将在所有导出的查询函数调用中隐式存在。不再需要在 parse_mappings 函数中使用 Box::new(mappings),也不再需要传递 *mut Mappings 指针。只要小心谨慎,我们也许可以从 Rust 库中删除所有分配,这将使发出的 WebAssembly 缩小到当前大小的一半。当然,这完全取决于创建多个相同 WebAssembly 模块实例是否是一个相对便宜的操作,这需要进一步调查。
wasm-bindgen 项目旨在消除手动编写 FFI 粘合代码的需要,并自动化 WebAssembly 和 JavaScript 之间的接口。使用它,我们应该能够删除所有与将 Rust API 导出到 JavaScript 相关的、手写的 unsafe 指针操作代码。
在这个项目中,我们将源映射解析和查询移植到了 Rust 和 WebAssembly,但这只是 source-map 库功能的一半。另一半是生成源映射,并且它也很敏感。我们希望将来也用 Rust 和 WebAssembly 重写构建和编码源映射的核心。我们预计会看到与解析源映射时观察到的类似加速效果。
添加 WebAssembly 实现到 mozilla/source-map 库的 pull 请求正在合并过程中。 该 pull 请求包含基准测试代码,以便可以重现结果,并且我们可以继续改进它们。
最后,我要感谢 Tom Tromey 与我一起参与这个项目。我还想感谢 Aaron Turon、Alex Crichton、Benjamin Bouvier、Jeena Lee、Jim Blandy、Lin Clark、Luke Wagner、Mike Cooper 和 Till Schneidereit 阅读早期草稿并提供宝贵的反馈。这份文档、我们的基准测试和 source-map 库都因为他们的贡献而变得更好。
0 或者 “transpiler”,如果你一定要坚持的话。 ⬑
1 SpiderMonkey 现在使用一个自托管的 JavaScript 实现的 Array.prototype.sort,当有一个自定义比较器函数时,当没有自定义比较器函数时,使用 C++ 实现。 ⬑
2 WebAssembly 和 JavaScript 之间的调用开销在 Firefox 中应该会随着错误 1319203 的解决而大部分消失。 之后,JavaScript 和 WebAssembly 之间的调用将具有与 JavaScript 函数之间非内联调用类似的开销。但是,该补丁尚未发布,其他浏览器也尚未发布等效的改进。 ⬑
3 对于 Firefox 和 Chrome,我们使用最新的 nightly 版本进行了测试。我们没有对 Safari 做同样的事情,因为最新的 Safari Technology Preview 需要比 El Capitan 更新的 macOS 版本,而这台笔记本电脑正在运行 El Capitan。 ⬑
关于 Nick Fitzgerald
我喜欢计算、自行车、嘻哈、书籍和绘图仪。我的代词是 he/him。
7条评论