
构建浏览器很困难;要构建一个好的浏览器,不可避免地需要收集大量数据,以确保实验室中有效的功能在实际使用中也能正常工作。但一旦开始收集数据,就必须确保保护用户隐私。我们一直在寻找改进数据收集安全性的方法,最近我们一直在试验一项非常酷的技术,叫做 Prio。
目前,所有主流浏览器的数据报告都大同小异:浏览器收集大量统计数据,并将其发送回浏览器制造商进行分析;在 Firefox 中,我们称此系统为遥测。构建遥测系统的挑战在于数据敏感性。为了确保我们保护用户的隐私,Mozilla 建立了一套透明的 数据实践,规定我们可以在哪些情况下收集哪些数据。对于特别敏感的 数据类别,我们会要求用户选择加入数据收集,并确保数据以安全的方式处理。
我们明白,这需要用户信任 Mozilla——我们不会滥用他们的数据,数据不会在漏洞中泄露,而且 Mozilla 不会被另一方强迫提供数据访问权限。将来,我们希望用户不必仅仅信任 Mozilla,特别是当我们收集需要选择加入的数据时,这些数据足够敏感。这就是为什么我们正在探索新的方法来保护您的数据隐私和安全,而不会损害我们构建最佳产品和服务所需的信息访问权限。
显然,完全不收集任何数据对隐私来说是最好的,但这也会让我们对实际情况中的问题一无所知,这使得我们很难构建用户需要的功能,包括隐私功能。这是一个常见的问题,在所谓的“隐私保护数据收集”方面已经做了很多工作,包括由 Google 开发的系统(RAPPOR,PROCHLO)和 Apple 开发的系统。这些系统各有优缺点,超出了本文的范围,但足以说明这是一个非常活跃的研究领域。
最近几个月,我们一直在试验一个这样的系统:Prio,由 Dan Boneh 教授 和斯坦福大学计算机科学系的博士生 Henry Corrigan-Gibbs 开发。Prio 背后的基本见解是,对于大多数目的,我们不需要收集单个数据,而只需要收集聚合数据。Prio 属于公共领域,它可以让 Mozilla 收集聚合数据,而无需收集任何人的个人数据。它是通过让浏览器将数据分成两个“份额”来实现的,每个份额都发送到不同的服务器。单独的份额不会告诉你任何关于正在报告的数据的信息,但它们在一起就能告诉你信息。每台服务器都收集来自所有客户端的份额,并将它们加起来。如果服务器随后将它们的总和值放在一起,结果就是所有用户值的总和。只要有一台服务器是诚实的,那么就无法恢复单个值。
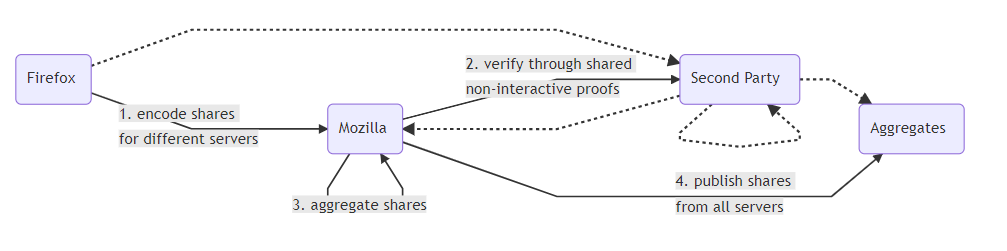
我们一直在与斯坦福团队合作,在 Firefox 中测试 Prio。在实验的第一阶段,我们要确保它在规模上能够高效地工作,并产生预期结果。这应该是一件轻而易举的事,但正如我们之前提到的,在实践中构建系统比理论上要困难得多。为了测试我们的集成,我们正在进行一个简单的部署,我们采用已经使用遥测收集的非敏感数据,并通过 Prio 收集这些数据。这让我们能够在不干扰我们现有的、对敏感数据进行的谨慎处理的情况下,验证该技术。这部分现在已经在 Nightly 中,并且已经开始报告结果。为了处理数据,我们在基于 Spark 的遥测分析系统中集成了对 Prio 的支持,因此它可以自动与 Prio 服务器通信来计算聚合值。
我们的初步结果很有希望:我们在 Nightly 中运行 Prio 已经 6 个星期了,收集了超过 300 万个数据值,在修复了一个我们获得 错误结果 的小故障后,我们的 Prio 结果与我们的遥测结果完全匹配。处理时间和带宽也看起来不错。在接下来的几个月里,我们将进行进一步的测试,以验证 Prio 能够继续产生正确的结果,并且能够很好地与我们现有的数据管道协同工作。
最重要的是,在生产部署中,我们需要确保用户隐私不依赖于信任单方。这意味着通过选择用户可以信任的第三方(或多方)来分散信任。这个第三方永远不会看到任何用户的个人数据,但他们有责任通过确保我们永远不会看到任何用户的个人数据来保证我们的诚信。为此,选择用户可以信任的第三方非常重要;在我们确定计划时,我们将对此进行更多说明。
我们还没有确定要使用 Prio 来保护哪些数据,以及何时保护这些数据。一旦我们验证了它按预期工作,并提供了我们所需的隐私保证,我们就可以继续在最需要的地方应用它。期待将来从我们这里听到更多消息,但现在能够迈出隐私保护数据收集的第一步令人兴奋。
关于 Robert Helmer
关于 Anthony Miyaguchi
Anthony 是 Mozilla 的数据工程师。
更多由 Anthony Miyaguchi 撰写的文章...
关于 Eric Rescorla
Eric 是 Mozilla Firefox 团队的首席技术官。