
错误太多,分类不够
Mozilla 每天收到数百个来自 Firefox 用户的错误报告和功能请求。尽快将错误分配到正确的人手中对于快速修复它们至关重要。这就是 错误分类 的作用:在开发人员知道错误存在之前,他们无法修复它。
鉴于错误数量庞大,让每个开发人员查看每个错误都是不可行的(截至撰写本文时,我们已经达到了错误编号 1536796!)。这就是为什么我们在 Bugzilla 上将错误按 *产品*(例如 Firefox,Firefox for Android,Thunderbird 等)和 *组件*(产品的子集,例如 Firefox::PDF Viewer)进行分组。
历史上,产品/组件的分配主要由志愿者和一些开发人员手动完成。不幸的是,这种流程无法扩展,并且这些工作量最好投入到其他地方。
介绍 BugBug
为了帮助尽快将错误分配到合适的 Firefox 工程师手中,我们开发了 BugBug,这是一个机器学习工具,可以自动为每个新的未分类错误分配产品和组件。通过快速向分类所有者展示新的错误,我们希望缩短修复新问题的时间。该工具基于我们最近实施的另一种技术,用于区分错误报告和功能请求。(您可以在 https://marco-c.github.io/2019/01/18/bugbug.html 中了解有关此技术的更多信息。)
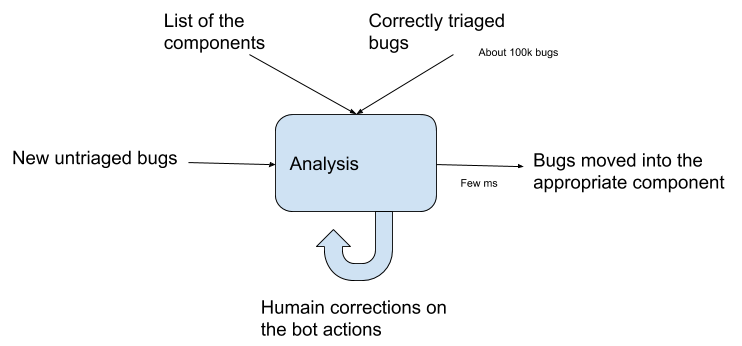
BugBug 训练和操作的高级架构
训练模型
我们拥有大量用于训练此模型的数据:二十年来的错误,这些错误都经过了 Mozilla 社区成员的审查,并被分配到产品和组件中。
显然,我们不能直接使用错误数据:分类完成后对错误的任何更改在工具实际运行时将不可访问。因此,我们将错误“回滚”到最初提交的时间。(在实践中这听起来很简单,但有很多特殊情况需要考虑!)
此外,虽然我们拥有数千个组件,但我们实际上只关心其中的一部分。在过去两年左右的时间里,在 396 个组件中,只有 225 个组件提交的错误数量超过 49 个。因此,我们将工具限制为仅查看错误数量至少为最大组件错误数量 1% 的组件。
我们使用从标题、第一个评论以及与每个错误相关的关键字/标志收集的特征来训练一个 XGBoost 模型。

BugBug 模型的高级概述
在运行时,我们仅在模型对其决策 *足够自信* 时执行分配:目前,我们使用 60% 的置信度阈值。使用此阈值,我们能够以非常低的误报率(> 80% 的精度,使用在 2018 年 12 月至 2019 年 3 月期间分类的错误验证集进行衡量)分配正确的组件。
BugBug 的结果
在 6 核机器上使用 32 GB 内存,对超过两年(大约 100,000 个错误)的数据进行模型训练大约需要 40 分钟。评估时间在毫秒级。鉴于该工具不会暂停,并且始终准备行动,因此该工具的分配速度远远快于手动分配(平均需要大约一周的时间)。
自从我们于 2019 年 2 月底在生产环境中部署 BugBug 以来,我们已经分类了大约 350 个错误。开发人员对已分类错误采取行动的中位时间为 2 天。(平均行动时间为 9 天,但在剔除异常值后,平均行动时间仅为 4 天。)
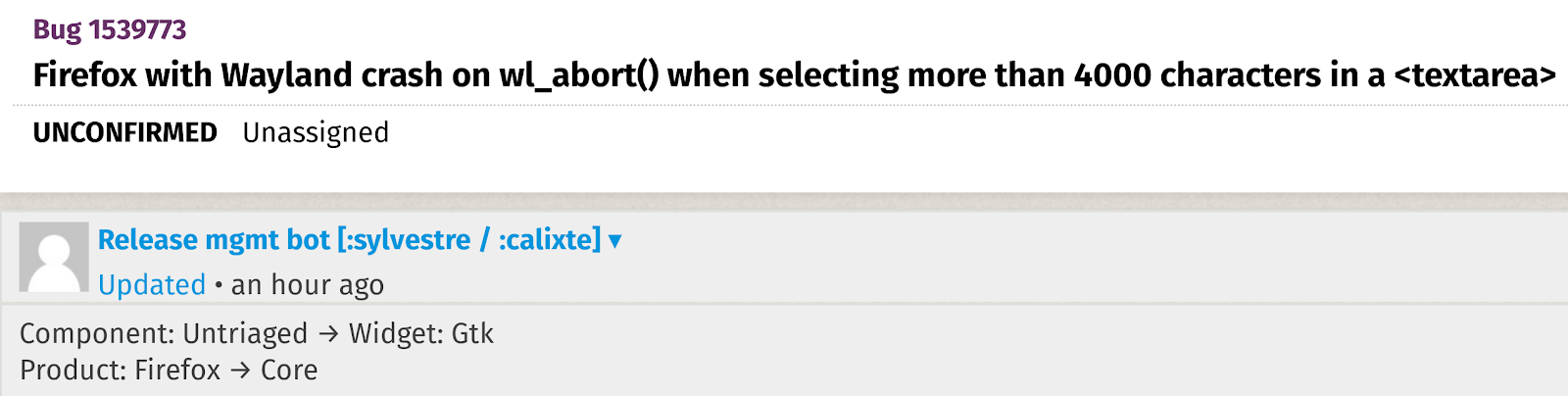
BugBug 在行动中
未来计划
我们计划使用机器学习来帮助其他软件开发流程,例如
- 识别重复的错误。对于导致 Firefox 崩溃的错误,用户通常会以略微不同的方式多次报告相同的错误。这些重复的错误最终会在分类流程中被发现并解决,但尽快找到重复的错误可以为尝试诊断崩溃的开发人员提供更多信息。
- 为开发人员提供额外的自动帮助,例如检测缺少“重现步骤”的错误并要求报告者提供这些步骤,或检测错误类型(例如性能、内存使用、崩溃等)。
- 尽早检测可能对特定 Firefox 版本很重要的错误。
目前,我们的工具仅为 Firefox 相关产品分配组件。我们希望扩展 BugBug,以自动为其他 Mozilla 产品分配组件。
我们也鼓励其他组织采用 BugBug。如果您使用 Bugzilla,采用它将非常容易;否则,我们需要添加对您的错误跟踪系统的支持。在 https://github.com/mozilla/bugbug 上提交问题,我们将解决它。我们乐于助人!
关于 Marco Castelluccio
Marco 是一位充满激情的 Mozilla 黑客(黑客和工程师的奇特混合体),他为 Firefox、PluotSorbet、Open Web Apps 做出了贡献,并将继续做出贡献。最近,他一直在研究将机器学习和数据挖掘技术应用于软件工程(测试、崩溃处理、错误管理等)。
5 条评论