
背景:SpiderMonkey 中的正则表达式
正则表达式(通常称为 RegExps)是 JavaScript 中用于操作字符串的强大工具。它们提供丰富的语法来描述和捕获字符信息。它们也广泛使用,因此 SpiderMonkey(Firefox 中的 JavaScript 引擎)必须对它们进行良好的优化。
多年来,我们对 RegExps 采取了多种方法。方便的是,在 RegExp 引擎和 SpiderMonkey 的其他部分之间有一个相当清晰的界限。替换 RegExp 引擎仍然并不容易,但可以在不影响 SpiderMonkey 的其他部分的情况下完成。
在 2014 年,我们利用了这种灵活性,用 V8 中使用的引擎 Irregexp 的分叉副本替换了 YARR(我们之前的 RegExp 引擎)。这提出了一个棘手的问题:如何使为一个引擎设计的代码在另一个引擎中工作?Irregexp 使用了大量 V8 API,包括核心概念,如 字符串的表示形式、对象模型 以及 垃圾收集器。
当时,我们选择对 Irregexp 进行大量重写,以使用我们自己的内部 API。这使我们更容易使用,但更难从上游导入新更改。RegExps 的变化相对较少,因此这似乎是一个很好的权衡。一开始,这对我们来说很有效。当引入“\u”标志等新功能时,我们在 Irregexp 中添加了它们。然而,随着时间的推移,我们开始落后。ES2018 添加了四个新的 RegExp 功能:dotAll 标志、命名捕获组、Unicode 属性转义 以及 后向断言。V8 团队为 Irregexp 添加了对这些功能的支持,但 SpiderMonkey 的 Irregexp 副本已经发生了足够的偏差,以至于难以应用相同的更改。
我们开始重新思考我们的方法。我们是否有一种方法可以支持现代 RegExp 功能,同时减少持续维护负担?如果我们优先考虑保持引擎的最新状态,我们的 RegExp 引擎会是什么样子?我们能与上游 Irregexp 保持多接近?
解决方案:为 Irregexp 构建一个 shim 层
事实证明,答案非常接近。截至撰写本文,SpiderMonkey 正在使用从 V8 存储库导入的最新版本 Irregexp,除了机械地重写的 #include 语句之外,没有任何更改。刷新导入只需要运行更新脚本以外的最小工作量。我们正在积极在上游贡献错误报告和补丁。
我们如何走到这一步?我们的方法是在 SpiderMonkey 和 Irregexp 之间构建一个shim 层。这个 shim 为 Irregexp 提供了它通常从 V8 获得的所有功能:从内存分配到代码生成,以及各种实用程序函数和数据结构。
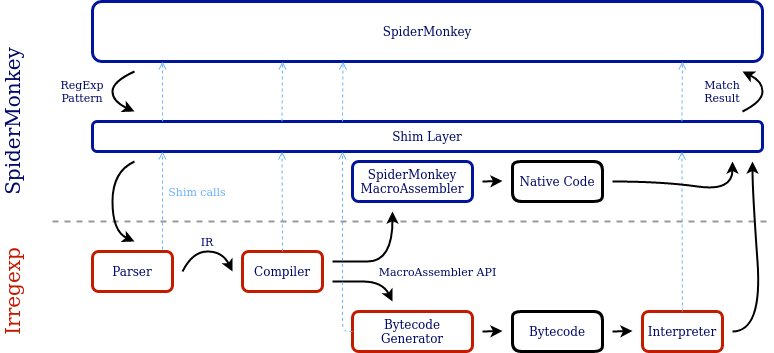
这需要一些工作。其中很多工作是直接将事物连接在一起的简单问题。例如,Irregexp 解析器和编译器使用 V8 的 Zone(一个基于区域的内存分配器)来分配临时对象并有效地丢弃它们。SpiderMonkey 的等效项称为 LifoAlloc,但它具有非常相似的接口。我们的 shim 能够通过直接将它们转发到其 LifoAlloc 等效项来实现对 Zone 方法的调用。
其他领域有更有趣的解决方案。以下是几个例子
代码生成
Irregexp 有两种执行 RegExps 的策略:一个字节码解释器 和一个即时编译器。前者生成更密集的代码(使用更少的内存),并且可以在没有本地代码生成的系统上使用。后者生成运行速度更快的代码,这对于重复执行的 RegExps 很重要。SpiderMonkey 和 V8 都会在第一次使用时解释 RegExps,然后逐步升级到编译它们。
生成本地代码的工具非常特定于引擎。幸运的是,Irregexp 具有一个精心设计的代码生成 API,称为 RegExpMacroAssembler。在解析和优化 RegExp 后,RegExpCompiler 将对 RegExpMacroAssembler 进行一系列调用以生成代码。例如,要确定字符串中的下一个字符是否与特定字符匹配,编译器将调用 CheckCharacter。要回溯如果反向引用未能匹配,编译器将调用 CheckNotBackReference。
总的来说,大约有 40 种可用的操作。这些操作一起可以表示任何 JavaScript RegExp。宏汇编器负责将这些抽象操作转换为最终的可执行形式。V8 包含不少于九种独立的 RegExpMacroAssembler 实现:每种支持的八种架构一种,最后一种实现生成用于解释器的字节码。SpiderMonkey 可以重用字节码生成器和解释器,但我们需要自己的宏汇编器。幸运的是,一些事情对我们有利。
首先,SpiderMonkey 的本地代码生成工具的工作级别高于 V8 的。我们不必为每种架构实现一个宏汇编器,只需要一个,它可以针对任何支持的机器。其次,使用 SpiderMonkey 的代码生成器实现 RegExpMacroAssembler 的大部分工作已经为我们对 Irregexp 的第一次导入完成了。我们必须进行相当多的更改来支持新功能(尤其是后向引用),但现有代码为我们提供了一个很好的起点。
垃圾收集
JavaScript 中的内存是自动管理的。当内存不足时,垃圾收集器 (GC) 将遍历程序并清理不再使用的任何内存。如果您正在编写 JavaScript,那么这会在后台发生。但是,如果您正在实现 JavaScript,那么您必须小心。当您正在处理可能被垃圾回收的东西(例如,您正在与 RegExp 匹配的字符串)时,您需要通知 GC。否则,如果您调用触发垃圾回收的函数,GC 可能会将您的字符串移动到其他地方(或者如果您是唯一的剩余引用,甚至完全将其删除)。出于显而易见的原因,这是一件坏事。通知 GC 您正在使用的对象的流程称为根植。我们 shim 实现中最有趣的挑战之一是 SpiderMonkey 和 V8 根植事物的方式之间的差异。
SpiderMonkey 直接在 C++ 堆栈上创建其根。例如,如果您想根植一个字符串,您可以创建一个 Rooted<JSString*>,它位于您的局部堆栈帧中。当您的函数返回时,根消失,GC 可以自由地收集您的 JSString。在 V8 中,您创建一个 Handle。在幕后,V8 创建一个根并将其存储在并行堆栈中。V8 中根的生存期由 HandleScope 对象控制,这些对象在创建时标记根堆栈上的一个点,并在销毁时清除比标记点更新的所有根。
为了使我们的 shim 工作,我们实现了我们自己的 V8 HandleScope 的缩小版本。更复杂的是,某些类型的对象在 V8 中被垃圾回收,但在 SpiderMonkey 中是常规的非 GC 对象。为了处理这些对象(不是双关语),我们添加了一个“伪句柄”的并行堆栈,它们看起来像普通的 Handle 对 Irregexp,但由(非 GC)唯一指针支持。
合作
没有 V8 团队的支持和建议,这一切都不可能实现。特别感谢 Jakob Gruber 的帮助。事实证明,这个项目与 V8 团队之前想让 Irregexp 更独立于 V8 的愿望相吻合。虽然我们努力使我们的 shim 尽可能完整,但在某些情况下,上游更改是最佳解决方案。许多这样的 更改 是 非常小的。有些更有趣。
V8 和 Irregexp 接口之间的一些代码在 SpiderMonkey 中难以使用。例如,为了执行已编译的正则表达式,Irregexp 调用 NativeRegExpMacroAssembler::Match。该函数与 V8 的字符串表示形式紧密相连。这两个引擎中的字符串实现出奇地接近,但并非如此接近,以至于我们可以共享代码。我们的 解决方案 是将该代码完全移出 Irregexp,并将其他不可用的代码隐藏在特定于嵌入程序的 #ifdef 后面。从技术角度来看,这些变化并不特别有趣,但从软件工程的角度来看,它们让我们更清楚地了解了在未来的项目中如何将 Irregexp 与 V8 分开的 API 边界。
当我们的原型实现接近完成时,我们意识到 SpiderMonkey 测试套件中剩余的失败之一也在 V8 中失败。经过调查,我们确定在处理不区分大小写、非 Unicode 正则表达式时,Irregexp 与 JavaScript 规范之间存在细微的差异。我们 向上游贡献了一个补丁 来重写 Irregexp 对具有非标准大小写折叠行为的字符的处理(例如“ß”,拉丁小写字母锐音 S,在大写时会变成“SS”)。
我们帮助改进 Irregexp 的机会并没有就此结束。在我们完成 Firefox Nightly 中新版 Irregexp 的发布后不久,我们勇敢的 模糊测试 团队发现了一个复杂 的正则表达式,它会导致 SpiderMonkey 和 V8 的调试版本崩溃。幸运的是,经过进一步调查,结果证明这是一个过于严格的断言。但是,它确实激发了一些额外的 代码质量 改进,这些改进是在正则表达式解释器中实现的。
结论:最新版本已准备就绪
除了在 JetStream2 基准测试 上获得了一些 改进的子分数 之外,我们还得到了什么呢?
最重要的是,我们获得了对所有新正则表达式功能的全面支持。Unicode 属性转义和后顾引用只影响正则表达式匹配,因此一旦 shim 完成,它们就可以正常工作。dotAll 标志只需要少量额外工作即可支持。命名捕获需要 SpiderMonkey 其他部分的更多支持,但在启用新引擎的几周后,命名捕获也落地了。(在测试它们时,我们在等效的 V8 代码中发现了 最后一个错误。)这使 Firefox 完全符合 最新的 ECMAScript JavaScript 标准。
我们也为未来的正则表达式支持奠定了更坚实的基础。在 Irregexp 上进行更多合作对双方都有益。SpiderMonkey 可以更快地添加新的正则表达式语法。V8 获得了额外的眼睛和双手来发现和修复错误。假设未来 Irregexp 的嵌入程序有一个经过验证的起点。
新引擎已在 Firefox 78 中可用,该版本目前处于我们的 开发者版 浏览器版本中。希望这项工作将成为 Firefox 中正则表达式的基础,并将持续多年。
关于 Iain Ireland
Iain 为 Mozilla 工作,负责 SpiderMonkey(JavaScript 引擎)。他住在加拿大。
5 条评论