
简介
我们在 Firefox 83 中默认启用了 Warp,这是对 SpiderMonkey 的重大更新。SpiderMonkey 是 Firefox 网页浏览器中使用的 JavaScript 引擎。
借助 Warp(也称为 WarpBuilder),我们对 JIT(即时)编译器 做了重大更改,从而提高了响应速度、加快了页面加载速度并改善了内存使用情况。新架构也更易于维护,并为 SpiderMonkey 的进一步改进解锁了更多可能性。
本文将解释 Warp 的工作原理以及它如何让 SpiderMonkey 更快。
Warp 的工作原理
多个 JIT
运行 JavaScript 时,第一步是将源代码解析为 **字节码**,这是一种更低级的表示形式。字节码可以使用解释器立即执行,也可以由即时(JIT)编译器编译为本地代码。现代 JavaScript 引擎有多个分层执行引擎。
JS 函数可能会在不同层级之间切换,具体取决于切换的预期收益
- **解释器 和 基线 JIT** 编译速度快,仅执行基本的代码优化(通常基于 内联缓存),并收集性能分析数据。
- 优化 JIT 执行高级编译优化,但编译速度较慢,内存使用量也更大,因此仅用于处于活跃状态(多次调用)的函数。
优化 JIT 基于其他层级收集的性能分析数据做出假设。如果这些假设被证明是错误的,则优化后的代码将被丢弃。发生这种情况时,该函数将恢复在基线层级中执行,并必须重新预热(这称为回退)。
对于 SpiderMonkey,它看起来像这样(简化):
性能分析数据
我们之前的优化 JIT,Ion,使用两种截然不同的系统来收集性能分析信息,以指导 JIT 优化。第一个是类型推断(TI),它收集有关 JS 代码中使用的对象类型的全局信息。第二个是 CacheIR,这是一种简单的线性字节码格式,基线解释器和基线 JIT 使用它作为基本优化原语。Ion 主要依赖于 TI,但在 TI 数据不可用时偶尔也会使用 CacheIR 信息。
借助 Warp,我们将优化 JIT 更改为仅依赖于基线层级收集的 CacheIR 数据。下面是它的样子
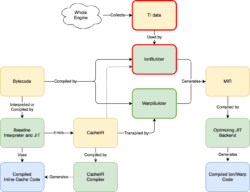
这里有很多信息,但需要注意的是,我们用更简单的 WarpBuilder 前端(用绿色突出显示)替换了 IonBuilder 前端(用红色突出显示)。IonBuilder 和 WarpBuilder 都生成 Ion MIR,这是一种 中间表示,由优化 JIT 后端使用。
IonBuilder 使用从整个引擎收集的 TI 数据来生成 MIR,而 WarpBuilder 使用与基线解释器和基线 JIT 用来生成内联缓存(IC)相同的 CacheIR 来生成 MIR。正如我们将在下面看到的那样,Warp 和低级层级之间的更紧密的集成具有多个优势。
CacheIR 的工作原理
考虑以下 JS 函数
function f(o) {
return o.x - 1;
}**基线解释器** 和 基线 JIT 为此函数使用两个内联缓存:一个用于属性访问 (o.x),另一个用于减法。这是因为在不知道 o 和 o.x 的类型的情况下,我们无法优化此函数。
属性访问 IC,o.x,将使用 o 的值调用。然后它可以附加一个 IC 存根(一小段机器代码)来优化此操作。在 SpiderMonkey 中,这是通过首先生成 CacheIR(一种简单的线性字节码格式,可以将其视为优化配方)来实现的。例如,如果 o 是一个对象,而 x 是一个简单的数据属性,则我们生成以下内容
GuardToObject inputId 0 GuardShape objId 0, shapeOffset 0 LoadFixedSlotResult objId 0, offsetOffset 8 ReturnFromIC
这里我们首先保护输入 (o) 是一个对象,然后我们保护对象的形状(它决定对象的属性和布局),然后我们从对象的插槽中加载 o.x 的值。
请注意,形状和属性在插槽数组中的索引存储在单独的数据部分中,而不是烘焙到 CacheIR 或 IC 代码本身中。CacheIR 使用 shapeOffset 和 offsetOffset 来引用这些字段的偏移量。这允许许多不同的 IC 存根共享相同的生成代码,从而减少了编译开销。
然后,IC 将此 CacheIR 代码片段编译为机器代码。现在,基线解释器和基线 JIT 可以快速执行此操作,而无需调用 C++ 代码。
减法 IC 的工作原理相同。如果 o.x 是一个 int32 值,则减法 IC 将使用两个 int32 值调用,并且 IC 将生成以下 CacheIR 来优化该情况
GuardToInt32 inputId 0 GuardToInt32 inputId 1 Int32SubResult lhsId 0, rhsId 1 ReturnFromIC
这意味着我们首先保护左侧是一个 int32 值,然后保护右侧是一个 int32 值,然后我们可以执行 int32 减法并将结果从 IC 存根返回到函数。
CacheIR 指令捕获优化操作所需的一切。我们有几百个 CacheIR 指令,定义在 一个 YAML 文件 中。这些是我们的 JIT 优化管道的构建块。
Warp:将 CacheIR 转译为 MIR
如果一个 JS 函数被多次调用,我们希望用优化编译器来编译它。使用 Warp 有三个步骤
- WarpOracle:在主线程上运行,创建一个包含基线 CacheIR 数据的快照。
- WarpBuilder:在后台线程上运行,从快照构建 MIR。
- 优化 JIT 后端:也在后台线程上运行,优化 MIR 并生成机器代码。
WarpOracle 阶段在主线程上运行,速度非常快。实际的 MIR 构建可以在后台线程上完成。这比 IonBuilder 更好,在 IonBuilder 中,我们必须在主线程上进行 MIR 构建,因为它依赖于许多用于类型推断的全局数据结构。
WarpBuilder 有一个转译器,可以将 CacheIR 转译为 MIR。这是一个非常机械的过程:对于每个 CacheIR 指令,它只是生成相应的 MIR 指令。
将这一切放在一起,我们就得到了下面的图片(点击查看大图)

我们对这种设计非常兴奋:当我们对 CacheIR 指令进行更改时,它会自动影响我们所有的 JIT 层级(参见上图中的蓝色箭头)。Warp 只是 将 函数的字节码和 CacheIR 指令编织到一个单独的 MIR 图中。
我们旧的 MIR 构建器(IonBuilder)有许多复杂的代码,我们不需要在 WarpBuilder 中使用这些代码,因为所有 JS 语义都由我们也需要用于 IC 的 CacheIR 数据捕获。
试用内联:对内联函数进行类型特化
优化 JavaScript JIT 能够将 JavaScript 函数内联到调用者中。借助 Warp,我们更进一步:Warp 还能够根据调用位置对内联函数进行特化。
再次考虑我们的示例函数
function f(o) {
return o.x - 1;
}此函数可能会从多个地方调用,每个地方传递不同的对象形状或不同的 o.x 类型。在这种情况下,内联缓存将具有多态 CacheIR IC 存根,即使每个调用者只传递单个类型也是如此。如果我们在 Warp 中内联此函数,我们将无法像我们希望的那样对其进行优化。
为了解决这个问题,我们引入了一种称为试用内联的新优化。每个函数都有一个 ICScript,它存储该函数的 CacheIR 和 IC 数据。在我们 Warp 编译函数之前,我们会扫描该函数中的基线 IC 以搜索对可内联函数的调用。对于每个可内联的调用位置,我们都会为被调用函数创建一个新的 ICScript。每当我们调用内联候选项时,我们不会使用被调用函数的默认 ICScript,而是传入新的特化 ICScript。这意味着基线解释器、基线 JIT 和 Warp 现在将收集并使用针对该调用位置特化的信息。
试用内联非常强大,因为它可以递归使用。例如,考虑以下 JS 代码
function callWithArg(fun, x) {
return fun(x);
}
function test(a) {
var b = callWithArg(x => x + 1, a);
var c = callWithArg(x => x - 1, a);
return b + c;
}
当我们对 test 函数执行试用内联时,我们将为每个 callWithArg 调用生成一个特化的 ICScript。之后,我们尝试在那些针对调用者特化的 callWithArg 函数中进行递归试用内联,然后我们可以根据调用者对 fun 调用进行特化。这在 IonBuilder 中是不可能的。
当要 Warp 编译 test 函数时,我们拥有针对调用者特化的 CacheIR 数据,并可以生成最佳代码。
这意味着我们在函数被 Warp 编译之前构建内联图,通过(递归)在调用位置对基线 IC 数据进行特化。然后,Warp 只需根据该数据进行内联,而无需其自己的内联启发式算法。
优化内置函数
IonBuilder 能够直接内联某些内置函数。这对于诸如 Math.abs 和 Array.prototype.push 之类的事情特别有用,因为我们可以用几个机器指令来实现它们,这比调用函数快得多。
由于 Warp 由 CacheIR 驱动,我们决定为对这些函数的调用生成优化的 CacheIR。
这意味着这些内置函数现在在我们的 Baseline Interpreter 和 JIT 中也得到了适当的优化,使用了 IC 存根。新的设计使我们能够生成正确的 CacheIR 指令,这不仅有利于 Warp,也利于我们所有的 JIT 层级。
例如,让我们看一下一个带有两个 int32 参数的 Math.pow 调用。我们生成以下 CacheIR
LoadArgumentFixedSlot resultId 1, slotIndex 3 GuardToObject inputId 1 GuardSpecificFunction funId 1, expectedOffset 0, nargsAndFlagsOffset 8 LoadArgumentFixedSlot resultId 2, slotIndex 1 LoadArgumentFixedSlot resultId 3, slotIndex 0 GuardToInt32 inputId 2 GuardToInt32 inputId 3 Int32PowResult lhsId 2, rhsId 3 ReturnFromIC
首先,我们确保被调用者是内置的 pow 函数。然后我们加载两个参数,并确保它们是 int32 值。然后我们执行专门针对两个 int32 参数的 pow 操作,并将该操作的结果从 IC 存根返回。
此外,Int32PowResult CacheIR 指令也被用来优化 JS 的 指数运算符,x ** y。对于该运算符,我们可能会生成
GuardToInt32 inputId 0 GuardToInt32 inputId 1 Int32PowResult lhsId 0, rhsId 1 ReturnFromIC
当我们为 Int32PowResult 添加 Warp 的 转译器支持 时,Warp 能够在不进行额外更改的情况下优化指数运算符和 Math.pow。这是一个很好的例子,说明 CacheIR 提供了可以用于优化不同操作的构建块。
结果
性能
Warp 在许多工作负载上比 Ion 更快。下面的图片展示了几个例子:我们在 Google Docs 加载时间上提高了 20%,在 Speedometer 基准测试中快了 10-12%

我们在其他以 JS 为主的网站(如 Reddit 和 Netflix)上也看到了类似的页面加载和响应速度的改进。Nightly 用户的反馈也很好。
这些改进主要是因为 Warp 基于 CacheIR,让我们可以删除引擎中用于跟踪 IonBuilder 使用的全局类型推断数据的代码,从而在整个引擎中提高速度。
旧系统要求所有函数都跟踪类型信息,而这些信息只有在非常热的功能中才有用。使用 Warp,用于优化 Warp 的分析信息(CacheIR)也被用来加速 Baseline Interpreter 和 Baseline JIT 中运行的代码。
Warp 还能够在非线程中执行更多工作,并且需要更少的重新编译(以前的设计经常过度专门化,导致许多放弃)。
合成 JS 基准测试
Warp 在某些合成 JS 基准测试(如 Octane 和 Kraken)上目前比 Ion 慢。这并不奇怪,因为 Warp 需要与近十年来专门针对这些基准测试的优化工作和调整竞争。
我们认为这些基准测试不代表现代 JS 代码(另请参见 V8 团队关于此的 博客文章),并且这些回归被其他地方的大幅提速和其他改进所抵消。
也就是说,我们将在未来几个月继续优化 Warp,我们预计将在所有这些工作负载上看到改进。
内存使用
删除全局类型推断数据还意味着我们使用了更少的内存。例如,下面的图片显示了 Firefox 中的 JS 代码在加载多个网站(tp6)时使用了少 8% 的内存

我们预计随着我们删除旧代码并能够简化更多数据结构,这个数字将在未来几个月内有所改善。
更快的 GC
类型推断数据也为垃圾回收增加了大量开销。在 9 月 23 日将 Warp 默认启用到 Firefox Nightly 后,我们注意到我们的遥测数据中 GC 清扫(GC 的一个阶段)有一些重大改进

可维护性和开发人员速度
由于 WarpBuilder 比 IonBuilder 更具机械性,我们发现代码更简单、更紧凑、更易于维护,并且错误更少。通过在所有地方使用 CacheIR,我们可以用更少的代码添加新的优化。这使得团队更容易提高性能并实现新功能。
接下来是什么?
使用 Warp,我们已经替换了 IonMonkey JIT 的前端(MIR 构建阶段)。下一步是删除旧代码和架构。这很可能在 Firefox 85 中发生。我们预计这将带来额外的性能和内存使用方面的改进。
我们还将继续逐步简化和优化 IonMonkey JIT 的后端。我们相信对于以 JS 为主的负载,仍然有很大的改进空间。
最后,由于我们所有的 JIT 现在都基于 CacheIR 数据,我们正在开发一个工具,让我们(以及 Web 开发人员)可以探索 JS 函数的 CacheIR 数据。我们希望这将有助于开发人员更好地了解 JS 性能。
致谢
Warp 的大部分工作是由 Caroline Cullen、Iain Ireland、Jan de Mooij 以及我们优秀的贡献者 André Bargull 和 Tom Schuster 完成的。SpiderMonkey 团队的其他人为我们提供了许多反馈和想法。Christian Holler 和 Gary Kwong 报告了各种 模糊错误。
感谢 Ted Campbell、Caroline Cullen、Steven DeTar、Matthew Gaudet、Melissa Thermidor,尤其是 Iain Ireland 对这篇文章的宝贵反馈和建议。
关于 Jan de Mooij
Jan 是 Mozilla 的一名软件工程师,他在那里负责 SpiderMonkey,即 Firefox 中的 JavaScript 引擎。他住在荷兰。
8 条评论