
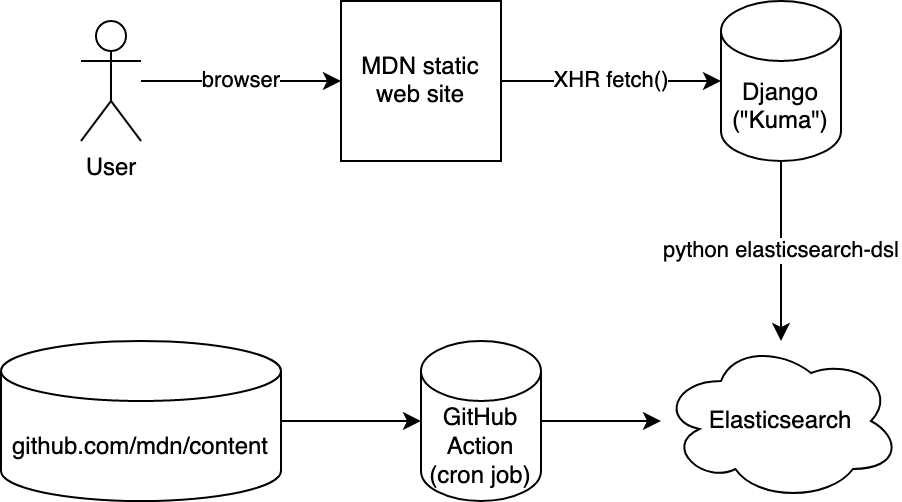
简而言之:定期,MDN 的全部内容通过 GitHub Action 中 我们的 Node 代码 生成。Python 脚本将这些内容批量发布到 Elasticsearch。我们的 Django 服务器通过 /api/v1/search 查询同一个 Elasticsearch。网站搜索页面是一个静态的单页应用程序,它向 /api/v1/search 端点发送 XHR 请求。搜索结果的排序方式由匹配度和“流行度”决定。
Jamstack
对于数据量过于庞大且动态更新频繁的网站,使用 “Jamstack” 的挑战在于,静态构建这些数据没有意义。搜索就是其中之一。据记录,截至 2021 年 2 月,MDN 包含 11,619 个英文文档(也称为文章)。另外还有大约 40,000 个翻译的文档。仅英语就包含 530 万个单词。因此,为了提供良好的搜索体验,我们需要在静态站点构建过程中,将所有这些内容索引到一个全文搜索数据库中。Elasticsearch 就是这样的数据库,并且它表现出色。特别是,Elasticsearch 是 MDN 非常熟悉的东西,因为它曾在 MDN 还是维基百科时,从 Django 应用程序中使用过。
构建
当我们构建整个网站时,脚本会基本循环遍历所有原始内容,应用宏和修复,生成一个 index.html(通过 React 服务器端渲染)和一个 index.json。index.json 包含所有完全渲染的文本(以 HTML 形式!),以“散文”形式分块。看起来像这样
{
"doc": {
"title": "DOCUMENT TITLE",
"summary": "DOCUMENT SUMMARY",
"body": [
{
"type": "prose",
"value": {
"id": "introduction",
"title": "INTRODUCTION",
"content": "<p>FIRST BLOCK OF TEXTS</p>"
}
},
...
],
"popularity": 0.12345,
...
}0
您可以在此处查看一个示例:/en-US/docs/Web/index.json
索引
接下来,在生成所有 index.json 文件后,Python 脚本接管,并遍历所有 index.json 文件,并根据其结构确定标题、摘要和整个正文(以 HTML 形式)。
接下来,在将这些内容发送到 Elasticsearch 批量发布器之前,它会剥离 HTML 代码。它不仅仅是将 <p>Some <em>cool</em> text.</p> 转换为 Some cool text.,因为它还会清理诸如 <div class="hidden"> 和某些 <div class="notecard warning"> 块之类的东西。
值得注意的一点是,整个过程大约每 24 小时运行一次,然后构建所有内容。但是,如果在两次运行之间删除(或移动)了某个页面,如何从 Elasticsearch 中删除之前添加的内容?解决方案很简单:它每天都会从头开始删除并重新创建索引。整个批量发布需要一段时间,因此在删除索引后,搜索结果不会那么好。有些人可能很不走运,他们在删除索引几秒钟后搜索 MDN,并且现在必须等待索引重建。
这是一个不幸的现实,但为了简单起见,这是一个值得冒的风险。此外,大多数人正在搜索英语内容,特别是 Web/ 树,因此批量发布的方式是先发布最受欢迎的内容,然后发布其余内容。以下是构建输出日志
Found 50,461 (potential) documents to index
Deleting any possible existing index and creating a new one called mdn_docs
Took 3m 35s to index 50,362 documents. Approximately 234.1 docs/second
Counts per priority prefixes:
en-us/docs/web 9,056
*rest* 41,306
因此,是的,在 3 分 35 秒内,索引中缺少一些内容,一些倒霉的人会得到比他们应该得到的更少的搜索结果。但我们可以将来优化这一点。
搜索
连接 Elasticsearch 的方式很简单,通过一个 URL,看起来像这样
https://USER:PASSWD@HASH.us-west-2.aws.found.io:9243
这是一个由 Elastic 管理的 Elasticsearch 集群,运行在 AWS 内部。我们的任务是确保我们在 GitHub Action(“写入器”)中使用的 URL 与我们在 Django 服务器(“读取器”)中使用的 URL 完全相同。
实际上,我们有 3 个 Elastic 集群:Prod、Stage、Dev。
我们还有 2 个 Django 服务器:Prod、Stage。
因此,我们只需要仔细确保秘密设置正确以匹配正确的环境。
现在,在 Django 服务器中,我们只需要将类似 GET /api/v1/search?q=foo&locale=fr(例如)的请求转换为发送到 Elasticsearch 的查询即可。我们有一个简单的 Django 视图函数,它会验证查询字符串参数,执行一些速率限制,创建一个查询(使用 elasticsearch-dsl),并将 Elasticsearch 结果打包回 JSON。
我们如何创建该查询很重要。搜索最重要的功能就在这里;如何对结果进行排序。
简单来说,排序顺序是流行度和“匹配度”的组合。假设大多数人想要流行的内容。例如,他们搜索 foreach,想要访问 /en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/forEach,而不是 /en-US/docs/Web/API/NodeList/forEach,这两个页面标题中都包含 forEach。“流行度”基于 Google Analytics 页面浏览量,我们会定期下载并将其归一化为 1 到 0 之间的浮点数。在撰写本文时,评分函数执行的操作类似于以下内容
rank = doc.popularity * 10 + search.score
这似乎可以产生相当合理的结果。
但“匹配度”还有更多内容。Elasticsearch 有自己的 API 用于定义提升,我们应用的方式是
- 标题中的匹配短语:提升 = 10.0
- 正文中的匹配短语:提升 = 5.0
- 标题中的匹配:提升 = 2.0
- 正文中的匹配:提升 = 1.0
然后将此应用于 Elasticsearch 执行的其他操作,例如“词频”和“逆文档频率”(tf 和 if)。这篇文章是关于 Elasticsearch 评分机制的有用介绍。
我们很可能不会就此止步。我们可能还可以做很多事情来调整这些无数的旋钮和滑块,以获得匹配文档的最佳排名。
Web UI
最后一块拼图是,我们如何向用户展示所有这些内容。它的工作原理是,developer.mozilla.org/$locale/search 返回一个空白的静态页面。页面加载后,它会延迟加载 JavaScript,该 JavaScript 实际上可以发出 XHR 请求以获取和显示搜索结果。代码看起来像这样
function SearchResults() {
const [searchParams] = useSearchParams();
const sp = createSearchParams(searchParams);
// add defaults and stuff here
const fetchURL = `/api/v1/search?${sp.toString()}`;
const { data, error } = useSWR(
fetchURL,
async (url) => {
const response = await fetch(URL);
// various checks on the response.statusCode here
return await response.json();
}
);
// render 'data' or 'error' accordingly here
此代码片段省略了许多有趣细节。您必须自己查看才能更深入地了解它的实际工作原理。但基本上,window.location(和 pushState)查询字符串驱动 fetch() 调用,然后该组件需要做的就是显示带有突出显示的搜索结果。
/api/v1/search 端点还会在主要搜索查询中运行 建议查询。这会提取出有趣的替代搜索查询。这些查询会经过过滤和评分,我们会发出“子查询”只是为了获取每个查询的计数。现在我们可以进行其中一个“您是说…”。例如:搜索 intersections。
总结
这篇博文中省略了许多有趣的、重要的和谨慎的细节。这是一个不断发展的系统,我们一直在努力改进和完善系统,使其符合用户的预期。
许多人通过 Google 搜索(例如 mdn array foreach)访问 MDN,但尽管如此,MDN 上近 5% 的流量来自网站搜索功能。/$locale/search?... 端点是 MDN 上访问量最大的页面。拥有一个可靠的搜索引擎非常重要。拥有和控制整个管道使我们能够完成一些其他网站不需要的、特定于 MDN 的事情。例如,我们索引了大量原始 HTML(例如 <video>),并且我们需要搜索代码片段。
希望 MDN 网站搜索能够从仅限于非常有限的功能,转变为现在可以真正帮助人们比 Google 更好地找到所需页面的工具。是的,值得定下高目标!
(最初发布在我的个人博客上)
关于 Peter Bengtsson
Peter 是 Mozilla 的一名网页开发人员,负责 MDN 网页文档。他在 www.peterbe.com 上撰写博客
2 条评论