
上个月,Gregor Weber 和我在 MDN Web 文档 中添加了一个自动完成搜索功能,允许您通过键入文档标题的一部分快速跳转到您要查找的文档。这是关于其实现方式的故事。如果您坚持到最后,我将分享一个“彩蛋”功能,一旦您学会了它,就会让您在晚宴上显得非常酷。或者,您可能只是想比普通人更快地浏览 MDN。
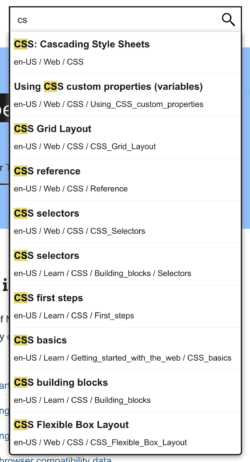
最简单的形式是,输入字段有一个 onkeypress 事件监听器,它会过滤每个文档标题(按语言环境)的完整列表。在撰写本文时,美国英语有 11,690 个不同的文档标题(及其 URL)。您可以通过打开 https://mdn.org.cn/en-US/search-index.json 来查看预览。是的,它很大,但它并不大到无法全部加载到内存中。毕竟,与执行搜索的代码一起,它只在用户表示要键入某些内容时才会加载。说到大小,由于该文件使用 Brotli 压缩,因此该文件在网络上的大小仅为 144KB。
实现细节
默认情况下,唯一加载的 JavaScript 代码是一个小的 shim,用于监视搜索 <input> 字段的 onmouseover 和 onfocus。整个 document 上还有一个事件监听器,用于查找特定的按键。在任何时候按下 /,都与使用鼠标光标将焦点放在 <input> 字段中一样。一旦触发焦点,它首先要做的是下载两个 JavaScript 包,这会将 <input> 字段变成更高级的东西。以其最简单的(伪)形式,以下是它的工作原理
<input
type="search"
name="q"
onfocus="startAutocomplete()"
onmouseover="startAutocomplete()"
placeholder="Site search..."
value="q">let started = false;
function startAutocomplete() {
if (started) {
return false;
}
const script = document.createElement("script");
script.src = "/static/js/autocomplete.js";
document.head.appendChild(script);
}然后它加载 /static/js/autocomplete.js,真正的魔法就发生在这里。让我们用伪代码深入了解一下
(async function() {
const response = await fetch('/en-US/search-index.json');
const documents = await response.json();
const inputValue = document.querySelector(
'input[type="search"]'
).value;
const flex = FlexSearch.create();
documents.forEach(({ title }, i) => {
flex.add(i, title);
});
const indexResults = flex.search(inputValue);
const foundDocuments = indexResults.map((index) => documents[index]);
displayFoundDocuments(foundDocuments.slice(0, 10));
})();如您所见,这只是它实际工作方式的简化版本,但现在还不是深入了解细节的时候。下一步是显示匹配项。我们使用(TypeScript)React 来完成此操作,但以下伪代码更容易理解
function displayFoundResults(documents) {
const container = document.createElement("ul");
documents.forEach(({url, title}) => {
const row = document.createElement("li");
const link = document.createElement("a");
link.href = url;
link.textContent = title;
row.appendChild(link);
container.appendChild(row);
});
document.querySelector('#search').appendChild(container);
}
然后使用一些 CSS,我们只需将其显示为 <input> 字段正下方的覆盖层。例如,我们根据 inputValue 突出显示每个 title,并且各种按键事件处理程序负责在您上下导航时突出显示相关行。
好的,让我们更深入地了解实现细节
我们只创建 一次 FlexSearch 索引,并对每次新的按键都重复使用它。因为用户可能在等待网络的同时输入更多内容,所以它实际上是响应式的,因此在所有 JavaScript 和 JSON XHR 到达后才会执行实际搜索。
在我们深入了解这个 FlexSearch 之前,让我们先谈谈显示实际上是如何工作的。为此,我们使用一个名为 downshift 的 React 库,它处理所有交互、显示,并确保显示的搜索结果可访问。downshift 是一个成熟的库,它处理构建此类小部件的无数挑战,尤其是使其可访问的方面。
那么,这个 FlexSearch 库 是什么呢?它是另一个第三方库,确保对标题的搜索考虑了自然语言。它将自己描述为“网络上速度最快、内存最灵活的无依赖项全文搜索库”,这比尝试在长字符串列表中简单查找一个字符串的性能和准确性都要高得多。
决定首先显示哪个结果
公平地说,如果用户键入 foreac,将 10,000 多个文档标题的列表缩减到仅包含标题中包含 foreac 的那些标题并不难,然后我们决定首先显示哪个结果。我们实现该方法的方式依赖于页面浏览量统计数据。我们记录每个 MDN URL 的页面浏览量,作为确定“流行度”的一种形式。大多数人决定访问的文档很可能是用户正在搜索的内容。
我们的 构建流程 生成 search-index.json 文件,它了解每个 URL 的页面浏览量。我们实际上并不关心绝对数字,但我们关心的是相对差异。例如,我们知道 Array.prototype.forEach()(这是文档标题之一)比 TypedArray.prototype.forEach() 更受欢迎,因此我们利用这一点并相应地对 search-index.json 中的条目进行排序。现在,通过 FlexSearch 进行缩减,我们使用数组的“自然顺序”作为技巧,试图向用户提供他们可能正在寻找的文档。这实际上与我们在完整站点搜索中用于 Elasticsearch 的技术相同。更多信息请参见:MDN 站点搜索的工作原理。
彩蛋:如何通过 URL 搜索
实际上,这不是一个异想天开的彩蛋,而是一个源于此自动完成功能需要为我们的内容创建者工作的事实的功能。您会看到,当您在 MDN 中处理内容 时,您会启动一个本地“预览服务器”,它是所有文档的完整副本,但所有文档都在本地作为静态站点在 https://:5000 下运行。在那里,您不想依赖服务器来执行搜索。内容作者需要快速在文档之间移动,因此自动完成搜索完全在客户端完成的原因很大程度上是因为这一点。
在 VSCode 和 Atom IDE 等工具中通常实现“模糊搜索”,您可以通过键入文件路径的一部分来查找和打开文件。例如,搜索 whmlemvo 应该会找到文件 files/<b>w</b>eb/<b>h</b>t<b>ml</b>/<b>e</b>lement/<b>v</b>ide<b>o</b>。您也可以使用 MDN 的自动完成搜索来执行此操作。操作方法是在输入的第一个字符中键入 /。
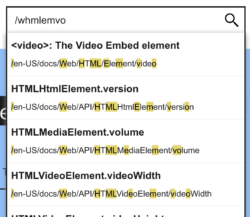
如果您知道文档的 URL 但不想完全拼写出来,这可以快速跳转到该文档。
事实上,还有另一种导航方式,那就是在浏览 MDN 时首先在任意位置按下 /,这会激活自动完成搜索。然后再次键入 /,您就可以开始了!
如何深入了解实现细节
所有这些代码都在 Yari 存储库 中,该项目用于构建和预览所有 MDN 内容。要查找确切的代码,请点击 client/src/search.tsx 源代码,您将找到延迟加载、搜索、预加载和显示自动完成搜索的所有代码。
关于 Peter Bengtsson
Peter 是 Mozilla 的一名 Web 开发人员,负责 MDN Web 文档。他在 www.peterbe.com 上写博客
11 条评论