
简介
去年,在封锁期间,许多人发现了 PDF 表单的重要性,因为他们不得不远程处理政府机构和大型组织(如银行)。Firefox 支持显示 PDF 表单,但它不支持填写表单:用户必须打印表单,用手填写表单,然后将其扫描回数字格式。 我们决定是时候重新投资 PDF 查看器(PDF.js)并支持在 Firefox 中填写 PDF 表单,以简化用户的生活。
在 PDF 查看器上投入更多时间的同时,我们还检查了积压的工作,并优先考虑提高我们的 PDF 阅读器对辅助技术的用户的可访问性。在下面,我们将介绍如何实现表单支持、改进可访问性,并确保在整个过程中没有出现回归。
PDF.js 架构的简要概述
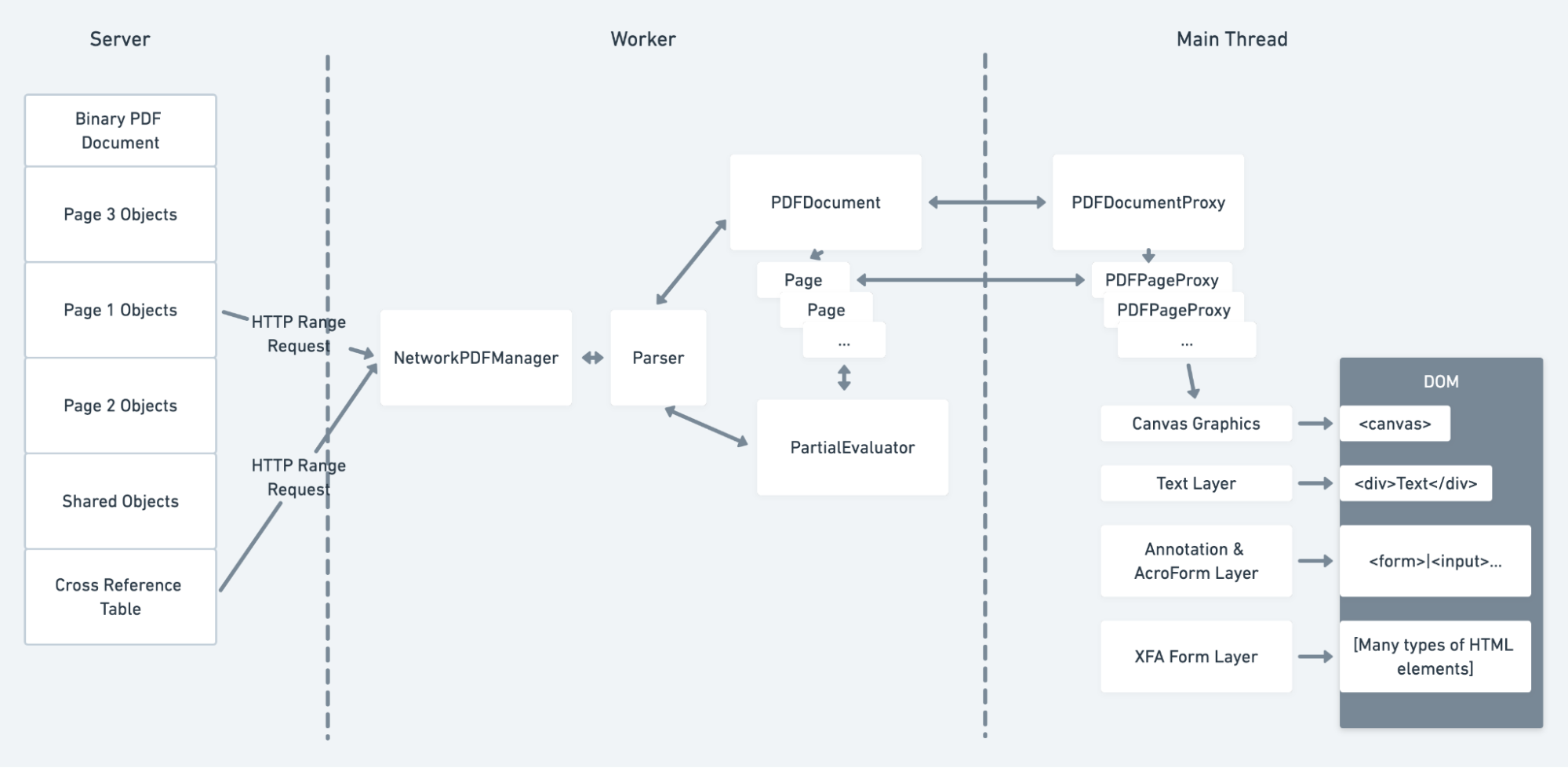 为了了解我们如何添加对表单和标记 PDF 的支持,首先要了解有关 PDF 查看器(PDF.js)如何在 Firefox 中工作的一些基本知识。
为了了解我们如何添加对表单和标记 PDF 的支持,首先要了解有关 PDF 查看器(PDF.js)如何在 Firefox 中工作的一些基本知识。
首先,PDF.js 会在 Web 工作器中获取并解析文档。解析后的文档将生成绘图指令。PDF.js 将它们发送到主线程并在 HTML5 canvas 元素上绘制它们。
除了画布外,PDF.js 可能还会创建三个额外的层,这些层显示在画布的顶部。第一层是文本层,它启用文本选择和搜索。它包含与画布上绘制的文本对齐的透明 span 元素。另外两个层是注释/AcroForm 层和XFA 表单层。它们支持表单填写,我们将在下面更详细地介绍它们。
填写表单(AcroForms)
AcroForms 是 PDF 支持的两种表单类型之一,也是最常见的表单类型。
AcroForm 结构
在 PDF 文件中,表单元素存储在注释数据中。PDF 中的注释与文档的主要内容是独立的元素。它们通常用于对文档进行笔记或在文档上绘图等操作。AcroForm 注释元素支持类似于 HTML 输入的用户输入,例如文本、复选框、单选按钮。
AcroForm 实现
在 PDF.js 中,我们解析 PDF 文件并在 Web 工作器中创建注释。然后,我们将其从工作器中发送出去并在主进程中使用插入到 div(注释层)中的 HTML 元素来渲染它们。我们将这个由 HTML 元素组成的注释层渲染在画布层的顶部。
注释层非常适合在浏览器中显示表单元素,但它与 PDF.js 支持打印的方式不兼容。在打印 PDF 时,我们在特殊的打印画布上绘制其内容,将其插入当前文档并将其发送到打印机。为了支持打印带有用户输入的表单元素,我们需要在画布上绘制它们。
通过检查(借助 qpdf 工具)使用其他工具保存的表单的原始 PDF 数据,我们发现我们需要通过 使用一些 PDF 绘图指令来保存已填写字段的外观,并且我们可以通过一个通用的实现来支持保存和打印。
为了生成字段外观,我们需要获取用户输入的值。我们引入了名为 annotationStorage 的对象,通过在相应的 HTML 元素中使用回调函数来存储这些值。然后在保存或打印时将 annotationStorage 传递给工作器,每个注释的值用于创建外观。
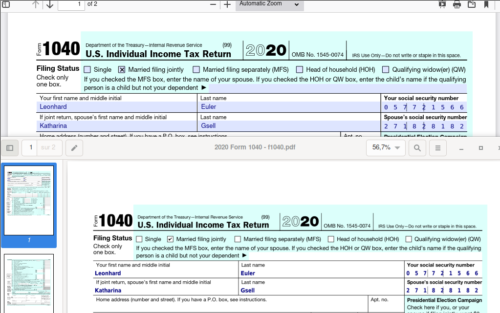
顶部是 Firefox 中的已填写表单,底部是 Evince 中打开的已打印 PDF。
安全地在 PDF 中执行 JavaScript
借助我们的遥测,我们发现许多表单包含并使用嵌入式 JavaScript 代码(是的,确实存在!)。
PDF 中的 JavaScript 可用于多种用途,但最常用于验证用户输入的数据或自动计算公式。例如,在此 PDF中,税款计算会从用户输入开始自动执行。由于此功能很常见且对用户很有帮助,因此我们着手在 PDF.js 中实现它。
备选方案
从一开始实施 JavaScript 时,我们最关心的就是安全性。我们不想让 PDF 文件成为新的攻击媒介。嵌入式 JS 代码必须在加载 PDF 时或在表单元素生成的事件(焦点、输入等)上执行。
我们研究了使用以下:
- JS eval 函数
- JS 引擎编译到 WebAssembly 中,使用 emscripten
- Firefox JS 引擎 ComponentUtils.Sandbox
第一个选项虽然很简单,但立即被放弃,因为在 eval 中运行不受信任的代码非常不安全。
第二个选项是使用用 WebAssembly 编译的 JS 引擎,这是一个强有力的竞争者,因为它可以与内置的 Firefox PDF 查看器和可以在普通网站中使用的 PDF.js 版本一起使用。但是,它会成为一个需要审核的大型新攻击面。它还会大大增加 PDF.js 的大小,并且会更慢。
第三个选项是沙箱,它是 Firefox 中向特权代码公开的一项功能,允许在特殊的隔离环境中执行 JS。沙箱是使用 空主体创建的,这意味着沙箱内部的所有内容只能被沙箱本身访问,并且只能访问沙箱本身内的其他内容(以及特权 Firefox 代码)。
我们的最终选择
我们决定使用 ComponentUtils.Sandbox 作为 Firefox 内置查看器。ComponentUtils.Sandbox 已经在 WebExtensions 中使用多年,因此这种实现经过了实战检验,非常安全:从 PDF 执行脚本至少与从普通网页执行脚本一样安全。
对于通用 Web 查看器(我们只能使用标准 Web API,因此我们对 ComponentUtils.Sandbox 一无所知)和pdf.js 测试套件,我们使用了 QuickJS 的 WebAssembly 版本(有关详细信息,请参阅 pdf.js.quickjs )。
在 Firefox 中的 PDF 沙箱的 实现 工作原理如下:
- 我们收集所有字段及其属性(包括与它们关联的 JS 操作),然后将它们克隆到沙箱中;
- 在构建时,我们使用 JS 代码生成一个捆绑包,以实现 PDF JS API(与我们习惯的 Web API 完全不同!)。我们将其加载到沙箱中,然后使用第一步中收集的数据执行它;
- 在字段的HTML 表示中,我们添加了回调以处理事件(焦点、输入等)。回调只是通过包含字段标识符和链接参数的对象将它们分派到沙箱中。我们使用 eval 在沙箱中执行相应的 JS 操作(在这种情况下是安全的:我们是在沙箱中)。然后,我们将结果克隆并将其分派到沙箱外部,以更新字段 HTML 表示中的状态。
我们决定不实现与 I/O(网络、磁盘等)相关的 PDF API,以避免任何安全问题。
另一种表单格式:XFA
我们的遥测还告诉我们,另一种类型的 PDF 表单, XFA,相当普遍。这种格式已从官方 PDF 规范中删除,但许多包含 XFA 的 PDF 仍然存在并被我们的用户查看,因此我们决定也实施它。
XFA 格式
XFA 格式与 PDF 文件中的内容大不相同。普通的 PDF 通常是绘制命令列表,所有布局由 PDF 生成器静态定义。但是,XFA 更接近于 HTML,并且具有 PDF 查看器必须生成的更动态的布局。实际上,XFA 是一种完全不同的格式,它被添加到 PDF 中。
PDF 中的 XFA 条目包含多个 XML 流:其中最重要的是模板和数据集。 template XML 包含渲染表单所需的所有信息:它包含 UI 元素(例如文本字段、复选框等)和容器(子表单、绘制等),这些容器可以具有静态或动态布局。 datasets XML 包含表单本身使用的所有数据(例如文本字段内容、复选框状态等)。所有这些数据都绑定到模板中(在布局之前),以设置不同 UI 元素的值。
模板示例
<template xmlns="http://www.xfa.org/schema/xfa-template/3.6/">
<subform>
<pageSet name="ps">
<pageArea name="page1" id="Page1">
<contentArea x="7.62mm" y="30.48mm" w="200.66mm" h="226.06mm"/>
<medium stock="default" short="215.9mm" long="279.4mm"/>
</pageArea>
</pageSet>
<subform>
<draw name="Text1" y="10mm" x="50mm" w="200mm" h="7mm">
<font size="15pt" typeface="Helvetica"/>
<value>
<text>Hello XFA & PDF.js world !</text>
</value>
</ draw>
</subform>
</subform>
</template>模板输出

XFA 实现
在 PDF.js 中,我们已经有一个非常好的 XML 解析器来检索有关 PDF 的元数据:这是一个良好的开端。
我们决定将每个 XML 节点映射到一个 JavaScript 对象,其结构用于验证节点(例如可能的子节点及其不同的数量)。解析和验证 XML 后,需要将表单数据绑定到表单模板中,并且可以使用 SOM 表达式(类似于 XPath 表达式)来使用一些原型。
布局引擎
在 XFA 中,我们可以拥有不同类型的布局,最终的布局取决于内容。我们最初计划依赖 Firefox 布局引擎,但我们发现不幸的是,我们需要自己布局所有内容,因为 XFA 使用了 Firefox 中不存在的一些布局功能。 例如,当容器溢出时,额外内容可以放在另一个容器中(通常在新的页面上,但有时也会放在另一个子表单中)。此外,一些模板元素没有尺寸,必须根据其内容推断。
最终,我们实现了一个自定义布局引擎:我们从上到下遍历模板树,并遵循布局规则,检查元素是否适合可用空间。如果不适合,我们将所有已布局的元素刷新到当前内容区域,然后移到下一个内容区域。
在布局过程中,我们将所有 XML 元素转换为具有树状结构的 JavaScript 对象。然后,我们将它们发送到主进程,将其转换为 HTML 元素并放置在 XFA 层中。
缺少字体问题
如上所述,一些元素的尺寸没有指定。我们必须根据它们使用的字体自己计算它们。这更具挑战性,因为字体有时不会嵌入 PDF 文件中。
在 PDF 中不嵌入字体被认为是不好的做法,但实际上许多 PDF 并没有包含一些知名字体(例如 Acrobat 或 Windows 附带的字体:Arial、Calibri 等),因为 PDF 创建者只是期望这些字体始终可用。
为了使我们的输出更接近 Adobe Acrobat,我们决定提供 Liberation 字体和知名字体的字形宽度。我们使用这些宽度重新缩放字形绘制,以便为所有知名字体提供兼容的字体替换。

左边:没有字形重新缩放的默认字体。右边:使用字形重新缩放以模拟 MyriadPro 的 Liberation 字体。
结果
最终结果还不错,例如,你现在可以在 Firefox 93 中打开诸如 5704 – APPLICATION FOR A FISH EXPORT LICENCE 之类的 PDF!
使 PDF 可访问
什么是标记 PDF?
早期的 PDF 版本对于屏幕阅读器等辅助工具并不友好。这主要是因为在文档中,页面上的所有文本或多或少都是绝对定位的,并且没有段落、标题或句子之类的逻辑结构概念。也没有办法为图像或图形提供文本描述。例如,一些关于 PDF 如何绘制文本的伪代码
showText(“This”, 0 /*x*/, 60 /*y*/);
showText(“is”, 0, 40);
showText(“a”, 0, 20);
showText(“Heading!”, 0, 0);这将把文本绘制为四行,但屏幕阅读器不知道它们都属于一个标题。为了帮助提高可访问性,后来版本的 PDF 规范引入了“标记 PDF”。这使得 PDF 可以创建屏幕阅读器可以使用的一种逻辑结构。可以将其视为类似于 HTML DOM 节点的层次结构。使用上面的示例,可以添加标记
beginTag(“heading 1”);
showText(“This”, 0 /*x*/, 60 /*y*/);
showText(“is”, 0, 40);
showText(“a”, 0, 20);
showText(“Heading!”, 0, 0);
endTag(“heading 1”);有了额外的标签信息,屏幕阅读器就知道所有这些行都属于“标题 1”,并且可以以更自然的方式读取它。该结构还允许屏幕阅读器轻松导航到文档的不同部分。
上面的示例仅涉及文本,但标记 PDF 支持更多功能,例如图像的替代文本、表格数据、列表等。
我们在 PDF.js 中如何支持标记 PDF
对于标记 PDF,我们利用现有的“文本层”和浏览器内置的 HTML ARIA 可访问性功能。我们可以通过一个简单的 PDF 示例(包含一个标题和一个段落)轻松地看到这一点。首先,我们生成逻辑结构并将其插入画布中:
<canvas id="page1">
<!-- This content is not visible,
but available to screen readers -->
<span role="heading" aria-level="1" aria-owns="heading_id"></span>
<span aria_owns="some_paragraph"></span>
</canvas>在覆盖画布的文本层中
<div id="text_layer">
<span id="heading_id">Some Heading</span>
<span id="some_paragaph">Hello world!</span>
</div>然后,屏幕阅读器将遍历画布中的 DOM 可访问性树,并使用 `aria-owns` 属性查找每个节点的文本内容。对于上面的示例,屏幕阅读器将宣布
标题级别 1 一些标题
你好,世界!
对于不熟悉屏幕阅读器的人来说,拥有这种额外的结构也可以使在 PDF 中导航变得更容易:你可以从一个标题跳转到另一个标题,并阅读段落,而无需不必要的停顿。
确保没有大规模回归,满足 ref 测试
爬取 PDF
在过去的几个月里,我们构建了一个网络爬虫,从网络上检索 PDF,并使用一组启发式算法收集有关它们的统计信息(例如,它们是 XFA 吗?它们使用什么字体?它们包含哪些格式的图像?)。
我们还使用爬虫及其启发式算法从 “PDF 协会发布的压力 PDF 语料库” 中检索我们感兴趣的 PDF,这被证明特别有趣,因为它们包含了许多我们认为不可能存在的边缘情况。
使用爬虫,我们能够构建一个大型标记 PDF 语料库(约 32000 个)、使用 JS 的 PDF(约 1900 个)和 XFA PDF(约 1200 个),我们可以将其用于手动和自动测试。感谢我们的 QA 团队审阅了这么多 PDF!他们现在对申请加拿大捕鱼许可证的一切了如指掌,生活技能!
ref 测试大获全胜
我们不仅使用语料库进行手动 QA,还将其中一些 PDF 添加到我们的 ref 测试列表(参考测试)中。
ref 测试 是一种测试,它包含一个测试文件和一个参考文件。测试文件使用 pdf.js 渲染引擎,而参考文件则不使用(以确保它是一致的,并且不会受到验证测试的补丁中的更改的影响)。参考文件只是从 pdf.js 的“主”分支中渲染给定 PDF 的屏幕截图。
ref 测试过程
当开发人员向 PDF.js 仓库提交更改时,我们运行 ref 测试,并确保测试文件的渲染与参考屏幕截图完全相同。如果有差异,我们确保差异是改进而不是回归。
接受并合并更改后,我们将重新生成参考文件。
ref 测试的不足
在某些情况下,测试的渲染可能会与参考文件存在细微差异,例如由于抗锯齿。这在结果中引入了噪声,导致开发人员和审阅人员必须筛选“虚假”回归。有时,由于要查看的差异太多,可能会错过真正的回归。
ref 测试的另一个不足之处是它们通常很大。ref 测试中的回归不像单元测试失败那样容易调查。
尽管有这些不足,ref 测试仍然是 pdf.js 武器库中一个非常强大的回归预防武器。我们拥有的大量 ref 测试在我们应用更改时增强了我们的信心。
结论
对 AcroForms 的支持已在 Firefox v84 中推出。JavaScript 执行已在 v88 中推出。标记 PDF 已在 v89 中推出。XFA 表单已在 v93 中推出(明天,2021 年 10 月 5 日!)。
虽然所有这些功能都极大地提高了表单的可用性和可访问性,但我们仍然希望添加更多功能。如果你有兴趣帮忙,我们一直在寻找更多贡献者,你可以加入我们,在 element 或 github 上与我们联系。
我们还要感谢两位贡献者 Jonas Jenwald 和 Tim van der Meij 对上述项目的持续帮助。
关于 bdahl
关于 Calixte Denizet
关于 Marco Castelluccio
Marco 是一位热情的 Mozilla hackeneer(黑客和工程师的奇怪混合体),他为 Firefox、PluotSorbet、Open Web Apps 做出了贡献,并一直贡献至今。最近,他一直在研究将机器学习和数据挖掘技术用于软件工程(测试、崩溃处理、错误管理等)。
3 条评论