
机器翻译是扩展网络内容可访问性的重要工具。通常,人们使用云提供商来翻译网页。最先进的神经机器翻译 (NMT) 模型很大,通常需要像 GPU 这样的专用硬件才能实时进行推理。
如果人们能够在本地机器 CPU 上运行一个紧凑的机器翻译 (MT) 模型,而不会牺牲翻译精度,那么这将有助于保护隐私并降低成本。
Bergamot 项目 是 Mozilla、爱丁堡大学、布拉格查理大学、谢菲尔德大学和塔尔图大学之间的合作项目,由欧盟地平线 2020 研究与创新计划资助。它将 MT 带入本地环境,提供小型、高质量、针对 CPU 优化的 NMT 模型。 Firefox 翻译 Web 扩展 利用了 Bergamot 项目的成果,为 Firefox 带来了本地翻译。
在本文中,我们将讨论用于训练我们高效 NMT 模型的组件。该项目是开源的,因此您可以尝试一下,也可以训练自己的模型!
架构
NMT 模型被训练为语言对,从语言 A 翻译到语言 B。 训练管道 被设计为端到端地训练语言对的翻译模型,从环境配置到导出可立即使用的模型。如果使用相同的代码、硬件和配置文件,则管道运行是完全可重复的。
管道复杂性来自于生产高效模型的要求。我们使用教师-学生蒸馏将高质量但资源密集型教师模型压缩成一个高效的、针对 CPU 优化的学生模型,该模型仍然具有良好的翻译质量。我们将在压缩部分进一步解释这一点。
管道包括许多步骤:组件编译、下载和清理数据集、训练教师、学生和反向模型、解码、量化、评估等(更多详细信息见下文)。管道可以表示为有向无环图 (DAG)。
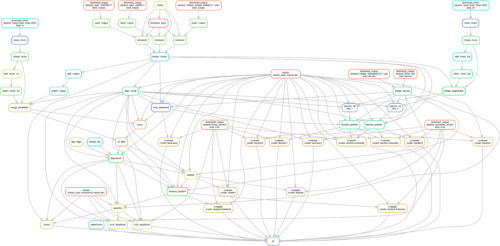
工作流是基于文件的,并使用自包含脚本,这些脚本使用磁盘上的数据作为输入,并将中间结果和输出结果写回磁盘。
我们使用 Marian 神经机器翻译引擎。它用 C++ 编写,旨在速度快。该引擎是开源的,被许多大学和公司使用,包括微软。
训练高质量模型
管道的第一个任务是训练一个高质量模型,该模型稍后将被压缩。此阶段的主要挑战是找到一个好的平行语料库,该语料库包含两种源语言和目标语言中相同句子的翻译,然后应用适当的清理程序。
数据集
事实证明,互联网上有很多用于机器翻译的开源平行数据集。最有趣的项目是 OPUS,它聚合了这些数据集。机器翻译年度会议还收集并分发了一些用于竞赛的数据集,例如, WMT21 新闻机器翻译。另一个很好的 MT 语料库来源是 Paracrawl 项目。
OPUS 数据集搜索界面
可以使用磁盘上的任何数据集,但从开源资源中自动下载数据集可以轻松添加新的语言对,并且无论何时扩展数据集,我们都可以轻松地重新训练模型以利用额外的。在使用之前,请务必检查开源数据集的许可证。
数据清理
大多数开源数据集都有一些噪声。抓取的网站和字幕翻译就是很好的例子。来自网站的文本可能是质量较差的自动翻译,或者包含意外的 HTML,而字幕通常是自由形式的翻译,会改变文本的含义。
众所周知,在机器学习 (ML) 世界中,如果我们向模型输入垃圾,我们就会得到垃圾作为结果。数据集清理可能是管道中获得良好质量的最关键步骤。
我们使用了一些适用于大多数数据集的基本清理技术,例如删除过短或过长的句子,并过滤掉源到目标长度比率不合理的句子。我们还使用 bicleaner,它是一个预训练的 ML 分类器,试图指示数据集中的训练示例是否可逆翻译。然后我们可以删除可能不正确或以其他方式添加不需要的噪声的低评分翻译对。
当您的训练集很大时,自动化是必要的。但是,始终建议手动查看您的数据,以便调整清理阈值并添加特定于数据集的修复程序,以获得最佳质量。
数据增强
世界上有 7000 多种语言,其中大多数被归类为低资源语言,这意味着用于训练的平行语料库数据很少。在这些情况下,我们使用一种称为反向翻译的流行数据增强策略。
反向翻译是一种增加可用训练数据量的方法,通过添加合成翻译。我们通过训练从目标语言到源语言的翻译模型来获得这些合成示例。然后,我们使用它将目标语言的单语数据翻译成源语言,创建合成示例,这些示例将添加到我们真正想要的模型的训练数据中,从源语言到目标语言。
模型
最后,当我们有一个干净的平行语料库时,我们训练一个大型的 transformer 模型以达到我们能达到的最佳质量。
一旦模型在增强数据集上收敛,我们就在不包括来自反向翻译的合成示例的原始平行语料库上对其进行微调,以进一步提高质量。
压缩
训练后的模型的大小可能在 800Mb 或更大,具体取决于配置,并且需要大量的计算能力才能执行翻译(解码)。在这一点上,它通常在 GPU 上执行,并且不适合在大多数消费级笔记本电脑上运行。在接下来的步骤中,我们将准备一个在消费级 CPU 上高效工作的模型。
知识蒸馏
我们用于压缩的主要技术是教师-学生知识蒸馏。这个想法是使用我们训练的重量级模型(教师)将大量文本从源语言解码成目标语言,然后使用更少的参数(学生)训练一个更小的模型,以学习这些合成翻译。学生应该模仿教师的行为,并展现出类似的翻译质量,尽管速度明显更快,更紧凑。
我们还使用源语言中的单语数据来增强平行语料库数据进行解码。这通过提供教师行为的额外训练示例来改进学生。
集成
另一个技巧是不只使用一个教师,而是使用 2-4 个在相同平行语料库上独立训练的教师的集成。它可以以必须训练更多教师为代价,稍微提高质量。管道支持使用教师集成进行训练和解码。
量化
模型压缩的另一种流行技术是量化。我们使用 8 位量化,这实质上意味着我们将神经网络的权重存储为 int8 而不是 float32。它节省了空间,并加快了推理时的矩阵乘法。
其他技巧
其他值得一提但超出本文范围的特性是学生模型的专门神经网络架构、教师模型的半精度解码以加快速度、词汇简短列表、词对齐的训练以及量化学生的微调。
是的,很多!现在您可以明白为什么我们希望拥有一个端到端管道。
如何了解更多信息
这项工作基于大量研究。如果您对训练管道背后的科学感兴趣,请查看 训练管道存储库自述文件中的参考文献 和 更广泛的 Bergamot 项目中的参考文献。 爱丁堡大学对 2020 年机器翻译效率任务的提交 是一篇很好的学术入门文章。查看 Nikolay Bogoychev 的这篇教程,以获得更实际和操作性的步骤解释。
结果
最终的学生模型比原始的教师模型小 47 倍,快 37 倍,并且质量仅略有下降!
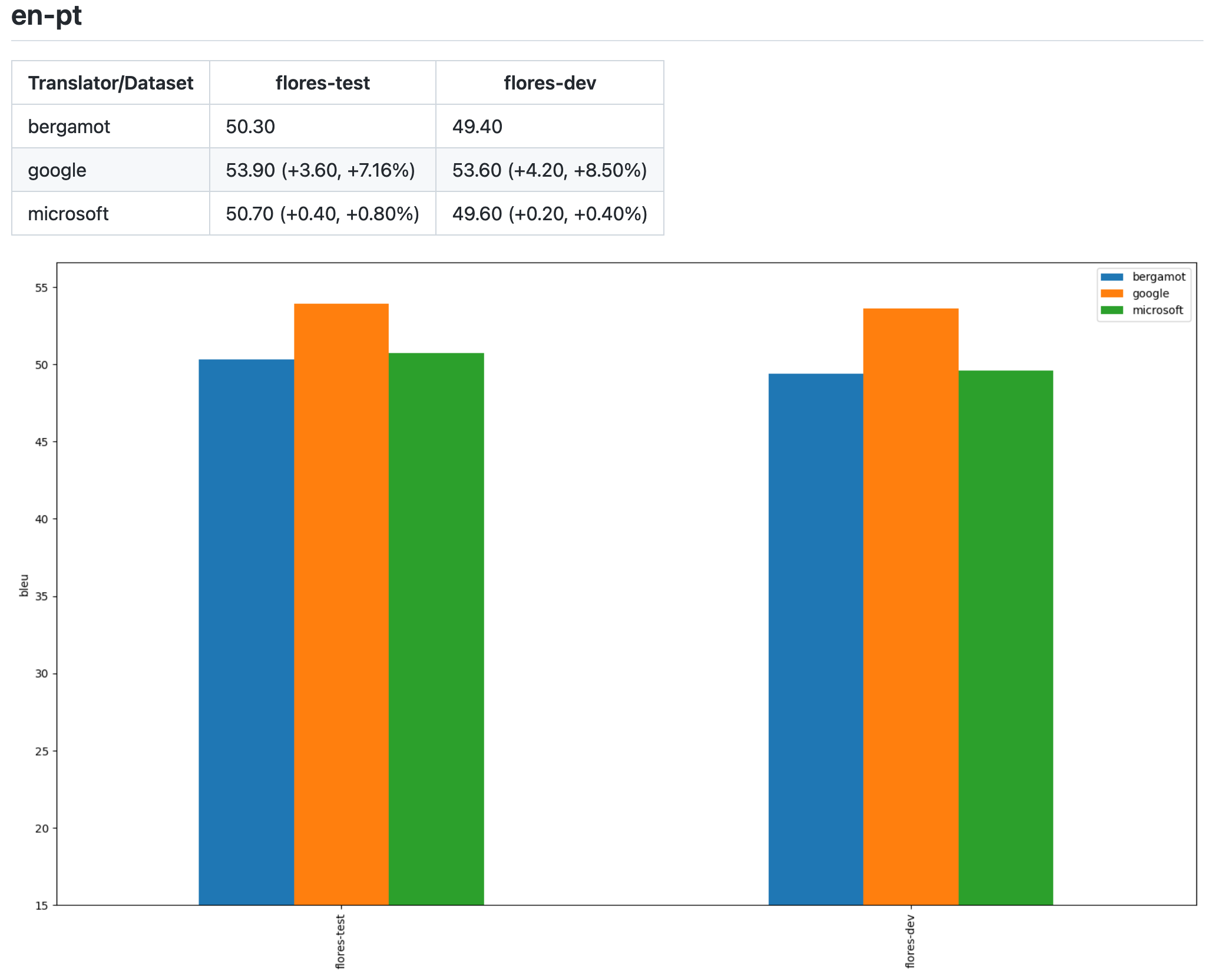
en-pt 模型和 Flores 数据集的基准测试
| 模型 | 大小 | 参数总数 | 1 个 CPU 内核上的数据集解码时间 | 质量,BLEU |
| 教师 | 798Mb | 192.75M | 631s | 52.5 |
| 量化学生 | 17Mb | 15.7M | 17.9s | 50.7 |
我们使用 MT 标准 BLEU 分数 评估结果,这些分数本质上代表了翻译文本和参考文本的相似程度。这种方法并不完美,但已证明 BLEU 分数与人类对翻译质量的判断密切相关。
我们有一个 GitHub 存储库,其中包含所有经过训练的模型和 评估结果,我们在其中将我们模型的准确性与云提供商的流行 API 进行比较。我们可以看到,一些模型的表现相似,甚至超过了云提供商,考虑到我们模型的效率、可重复性和开源性质,这是一个很棒的结果。
例如,您可以看到 Mozilla 使用仅开源数据训练的英语到葡萄牙语模型的评估结果。
任何人都可以训练模型并将其贡献到我们的仓库。这些贡献可以在 Firefox Translations 网页扩展 和其他地方使用(见下文)。
缩放
当然可以在一台机器上运行整个管道,尽管这可能需要一段时间。管道中的某些步骤受 CPU 限制,难以并行化,而其他步骤可以卸载到多个 GPU 上。存储库中的大多数官方模型都是在配备 8 个 GPU 的机器上训练的。一些步骤,例如知识蒸馏期间的教师解码,即使在资源充足的单机上也可能需要几天的时间。因此,为了加快速度,我们添加了集群支持,以便能够在多个节点上分布管道的不同步骤。
工作流管理器
为了管理这种复杂性,我们选择了 Snakemake,它在生物信息学领域非常流行。它使用基于文件的流程,允许在 Python 中指定步骤依赖项,支持容器化以及与不同集群软件的集成。我们考虑了专注于作业调度的替代解决方案,但最终选择了 Snakemake,因为它更适合一次运行实验流程。
Snakemake 规则的示例(规则之间的依赖关系是隐式推断的)
rule train_teacher:
message: "Training teacher on all data"
log: f"{log_dir}/train_teacher{{ens}}.log"
conda: "envs/base.yml"
threads: gpus_num*2
resources: gpu=gpus_num
input:
rules.merge_devset.output,
train_src=f'{teacher_corpus}.{src}.gz',
train_trg=f'{teacher_corpus}.{trg}.gz',
bin=ancient(trainer),
vocab=vocab_path
output: model=f'{teacher_base_dir}{{ens}}/{best_model}'
params:
prefix_train=teacher_corpus,
prefix_test=f"{original}/devset",
dir=directory(f'{teacher_base_dir}{{ens}}'),
args=get_args("training-teacher-base")
shell: '''bash pipeline/train/train.sh \
teacher train {src} {trg} "{params.prefix_train}" \
"{params.prefix_test}" "{params.dir}" \
"{input.vocab}" {params.args} >> {log} 2>&1'''集群支持
为了在集群节点之间并行化工作流步骤,我们使用 Slurm 资源管理器。它操作起来比较简单,非常适合高性能实验流程,并支持 Singularity 容器,从而更易于复制。Slurm 也是学术界用于模型训练的高性能计算机 (HPC) 中最流行的集群管理器,大多数联盟合作伙伴已经在使用它或熟悉它。
如何开始训练
工作流非常资源密集型,因此您需要一台性能良好的服务器或甚至一个集群。我们建议每台机器使用 4-8 个 Nvidia 2080 或更好的 GPU。
克隆 https://github.com/mozilla/firefox-translations-training 并按照 自述文件 中的说明进行配置。
最重要的是找到并行数据集,并根据您可用的数据和硬件正确配置设置。您可以在自述文件中了解更多信息。
如何使用现有模型
现有模型与 Firefox Translations 网页扩展 一起提供,使用户能够在 Firefox 中翻译网页。这些模型会根据需要下载到本地计算机。网页扩展使用这些模型以及 bergamot-translator Marian 包装器,该包装器编译为 WebAssembly。
此外,还有一个位于 https://mozilla.github.io/translate 的游乐场网站,您可以在其中输入文本并立即翻译,也是在本地进行的,但作为静态网站提供,而不是作为浏览器扩展。
如果您对服务器上的高效 NMT 推理感兴趣,可以尝试一个原型 HTTP 服务,它使用本机编译的 bergamot-translator,而不是编译为 WASM。
或者按照 bergamot-translator 自述文件 中的构建说明直接使用 C++、JavaScript WASM 或 Python 绑定。
结论
近年来,机器翻译研究取得了令人惊叹的进步。本地高质量翻译是未来,越来越多的公司和研究人员能够训练此类模型,即使他们无法访问专有数据或大规模计算能力。
我们希望 Firefox Translations 将为所有人提供一种新的隐私保护、高效、开源的机器翻译标准。
致谢
我要感谢 Bergamot 项目 的所有参与者,感谢他们使这项技术成为可能,感谢我的队友 Andre Natal 和 Abhishek Aggarwal 为使 Firefox Translations 成为现实做出的杰出贡献,感谢 Lonnen 管理项目并编辑这篇博文,当然也要感谢 Mozilla 的优秀社区,感谢他们帮助本地化网页扩展并测试其早期版本。
该项目已获得欧盟地平线 2020 研究与创新计划的资助,拨款协议编号 825303
关于 Evgeny Pavlov
Evgeny 是 Mozilla 的高级软件工程师。他从事应用机器学习项目。