
(扩展自在DWeb Camp 2023 上发表的演讲。)
人工智能很可能成为近年来最具影响力和颠覆性的技术之一。这种影响不是理论上的:人工智能已经以重大方式影响着现实生活中的人们,并且已经改变了我们所知和喜爱的网络。认识到潜在的益处和危害,Mozilla 致力于值得信赖的人工智能的原则。对我们来说,“值得信赖”意味着人工智能系统对其使用的数据和做出的决定透明,尊重用户隐私,优先考虑用户代理和安全,并努力减少偏见和促进公平。
现状
现在,大多数人体验最新人工智能技术的主要方式是通过生成式人工智能聊天机器人。这些工具因其为用户提供了很多价值而变得越来越受欢迎,但占主导地位的产品(如 ChatGPT 和 Bard)都由强大的科技公司运营,通常使用专有技术。
在 Mozilla,我们相信开源的协作力量,它可以赋能用户,推动透明度,而且最重要的是,确保技术的发展不仅仅取决于一小部分公司的世界观和经济动机。幸运的是,开源人工智能领域最近取得了快速而令人兴奋的进展,特别是在驱动这些聊天机器人的大型语言模型(LLM)和支持其使用的工具方面。我们希望了解、支持和促进这些努力,因为我们相信它们提供了最好的途径之一,有助于确保新出现的人工智能系统真正值得信赖。
深入研究
本着这个目标,Mozilla 创新团队内部的一个小型团队最近在位于旧金山的总部进行了一次黑客马拉松。我们的目标:构建一个 Mozilla 内部聊天机器人原型,这个原型…
- 完全自包含,完全在 Mozilla 的云基础设施上运行,不依赖任何第三方 API 或服务。
- 使用免费的开源大型语言模型和工具构建。
- 贯彻 Mozilla 的信念,从值得信赖的人工智能到Mozilla 宣言中倡导的原则。
作为奖励,我们设定了一个扩展目标,即整合一定程度的内部 Mozilla 特定知识,以便聊天机器人可以回答员工关于内部事项的问题。
承担这个项目的 Mozilla 团队——Josh Whiting、Rupert Parry 和我自己——对机器学习的了解程度各不相同,但我们都没有人构建过完整的全栈人工智能聊天机器人。因此,这个项目的另一个目标就是简单地撸起袖子学习!
这篇文章旨在分享我们的学习成果,希望它能帮助或启发你在这项技术方面的探索。组装一个开源 LLM 驱动的聊天机器人是一个复杂的任务,需要在技术栈的多个层级做出许多决策。在这篇文章中,我将带你了解该栈的每一层级,我们遇到的挑战以及我们为满足自己的特定需求和期限做出的决策。当然,你的里程可能会有所不同。
准备好了吗?那就让我们开始吧,从栈的底部开始…
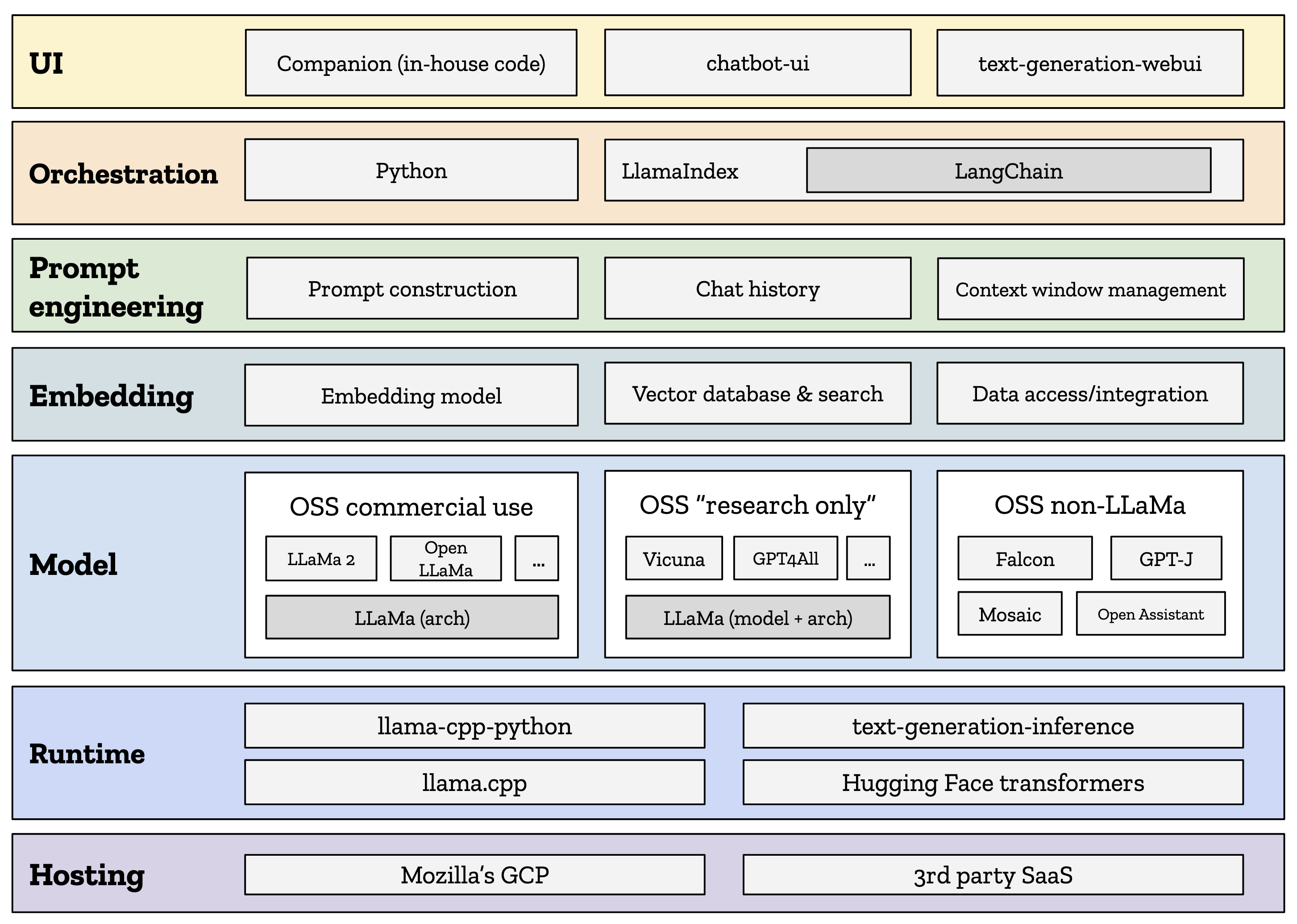 我们聊天机器人探索的可视化表示。
我们聊天机器人探索的可视化表示。
决定在哪里以及如何托管
我们面临的第一个问题是,在哪里运行我们的应用程序。无论是大型公司还是小型公司,都不乏热衷于托管你的机器学习应用程序的公司。它们有各种形状、大小、抽象级别和价格点。
对于许多人来说,这些服务物超所值。机器学习运维(也称为“MLOps”)之所以成为一个不断发展的学科是有原因的:部署和管理这些应用程序很困难。它需要特定的知识和技能,许多开发人员和运维人员还没有掌握。而且失败的代价很高:配置不当的人工智能应用程序可能会很慢、很昂贵,提供糟糕的体验,或者两者兼而有之。
我们的做法:我们这个为期一周的项目明确的目标是构建一个安全且完全对 Mozilla 私密的聊天机器人,不允许任何外部人员监听、收集用户数据或以其他方式窥视其使用情况。我们还想尽可能多地了解开源人工智能技术的现状。因此,我们选择放弃任何第三方人工智能 SaaS 托管解决方案,而是在 Mozilla 现有的 Google Cloud Platform (GCP) 帐户中设置自己的虚拟服务器。这样做,我们实际上承诺自己做 MLOps。但我们也可以放心地继续前进,因为我们的系统将是私密的,并且完全在我们控制之下。
选择运行时环境
使用 LLM 为应用程序提供支持需要有一个模型的运行时引擎。实际上运行 LLM 有多种方法,但由于时间限制,我们在这个项目中并没有深入研究所有这些方法。相反,我们专注于两种特定的开源解决方案:llama.cpp 和 Hugging Face 生态系统。
对于那些不知道的人来说,Hugging Face 是机器学习领域中一家有影响力的初创公司,它在普及机器学习的Transformer 架构方面发挥了重要作用。Hugging Face 提供了一个完整的平台,用于构建机器学习应用程序,包括一个庞大的模型库以及大量的教程和文档。他们还提供托管 API,用于文本推断(这是 LLM 驱动的聊天机器人幕后所做事情的正式名称)。
由于我们希望避免依赖任何人的托管软件,我们选择尝试 Hugging Face 托管 API 的开源版本,它位于 GitHub 上的text-generation-inference 项目中。text-generation-inference 很棒,因为它与 Hugging Face 自身的Transformers 库一样,可以支持各种模型和模型架构(下一节将详细介绍)。它还针对支持多个用户进行了优化,并且可以通过 Docker 部署。
不幸的是,这里是我们开始遇到学习 MLOps 的乐趣的第一个挑战。我们在启动服务器时遇到了很多麻烦。这部分是环境问题:由于 Hugging Face 的工具是 GPU 加速的,因此我们的服务器需要特定的操作系统、硬件和驱动程序组合。它特别需要安装 NVIDIA 的CUDA 工具包(CUDA 是 GPU 加速机器学习应用程序的主要 API)。我们在这方面苦苦挣扎了一整天,最后才让模型成功运行,但即使这样,输出速度也比预期的要慢,结果也令人沮丧地糟糕——这都是某个地方的栈中存在问题迹象。
现在,我并不是在批评这个项目。绝非如此!我们喜欢 Hugging Face,并且在他们的栈上构建提供了许多优势。我相信,如果我们有更多时间或实践经验,我们就会让一切正常运行。但时间对我们来说是一种奢侈品,我们没有时间。我们有意缩短的项目期限意味着我们无法承受陷入配置和部署问题太深的代价。我们需要快速让一些东西工作,以便我们可以继续前进并继续学习。
就在这时,我们将注意力转向了llama.cpp,这是一个由Georgi Gerganov 启动的开源项目。llama.cpp 实现了一个相当巧妙的技巧:它可以轻松地将特定类别的人工智能模型在消费级硬件上运行,依赖于 CPU 而不是要求高端 GPU。事实证明,现代 CPU(尤其是 Apple Silicon CPU,如 M1 和 M2)可以做得 surprisingly well,至少对于最新一代的相对较小的开源模型而言。
llama.cpp 是一个很棒的项目,也是开源力量释放创造力和创新的绝佳例证。我之前已经在自己的个人人工智能实验中使用过它,甚至写过一篇博文,展示了如何让任何人都可以在自己的 MacBook 上运行高质量的模型。因此,这似乎是我们可以尝试的下一个自然选择。
虽然 llama.cpp 本身只是一个命令行可执行文件——“cpp”代表“C++”——但它可以被 docker 化并像服务一样运行。最重要的是,一套 Python 绑定 可用,它公开了一个 OpenAI API 规范 的实现。所有这些意味着什么?好吧,这意味着 llama.cpp 使得将 你自己的 LLM 代替 ChatGPT 变得很容易。这一点很重要,因为 OpenAI 的 API 正被机器学习开发人员迅速而广泛地采用。模仿该 API 是开源产品如 llama.cpp 的一项巧妙的柔道策略。
我们所做的:有了这些工具,我们能够非常快地启动并运行 llama.cpp。我们不必担心 CUDA 工具包版本和配置昂贵的托管 GPU,而是能够启动一个简单的 AMD 驱动的多核 CPU 虚拟服务器,然后……开始。
选择你的模型
你会在这个故事中发现一个新兴趋势,即你在构建聊天机器人的过程中做出的每一个决定都会与其他决定相互作用。没有简单的选择,也没有免费的午餐。你做出的决定 会 回来困扰你。
在我们这个案例中,选择使用 llama.cpp 带来了一个重要的结果:我们现在可用的模型列表受到限制。
简短的历史课:2022 年底,Facebook 宣布了 LLaMA,它自己的大型语言模型。为了粗略地概括,LLaMA 由两部分组成:模型数据本身和模型构建的基础架构。Facebook 开源了 LLaMA 架构,但没有开源模型数据 。 相反,希望使用这些数据的人需要申请许可才能使用,并且他们对数据的使用仅限于非商业目的。
即便如此,LLaMA 立即引发了模型创新的寒武纪大爆发。斯坦福大学发布了 Alpaca,他们通过一个名为 微调 的过程,在 LLaMA 基础上进行构建而创建的。不久之后,LMSYS 发布了 Vicuna,这是一个可以说更加令人印象深刻的模型。还有数十个,如果不是数百个。
那么,细则是什么呢?这些模型都是使用 Facebook 的模型数据开发的——用机器学习术语来说,就是“权重”。正因为如此,它们继承了 Facebook 对这些原始权重施加的法律限制。这意味着这些原本优秀的模型 不能用于商业目的。因此,遗憾的是,我们不得不从我们的列表中删除它们。
但也有好消息:即使 LLaMA 权重不是真正的开源,但其底层的 架构 是真正的 开源代码。这使得构建利用 LLaMA 架构但并不依赖 LLaMA 权重的新模型成为可能。多个团队已经做到了这一点,从头训练自己的模型,并将其作为开源发布(通过 MIT、Apache 2.0 或 Creative Commons 许可)。一些最近的例子包括 OpenLLaMA,以及——就在几天前——LLaMA 2,Facebook 自己发布的 Facebook LLaMA 模型的全新版本,但这次明确授权用于商业用途(尽管它众多的其他法律障碍引发了关于它是否真正开源的严重疑问)。
你好,后果
还记得 llama.cpp 吗?这个名字不是偶然的。llama.cpp 运行基于 LLaMA 架构的模型。这意味着我们能够利用上述模型来进行我们的聊天机器人项目。但也意味着我们 只能 使用基于 LLaMA 架构的模型。
你看,还有很多其他的模型架构,以及很多在它们之上构建的模型。这个列表太长,这里无法一一列举,但一些主要的例子包括 MPT、Falcon 和 Open Assistant。这些模型使用与 LLaMA 不同的架构,因此(目前)无法在 llama.cpp 上运行。这意味着无论它们有多好,我们都无法在我们的聊天机器人中使用它们。
模型、偏差、安全性和你
现在,你可能已经注意到,到目前为止,我只从许可证和兼容性的角度谈论模型选择。这里还有另外一组考量,它们与模型本身的质量有关。
模型是 Mozilla 对 AI 领域感兴趣的焦点之一。这是因为你选择的模型目前是决定你的最终 AI“可信度”的最大因素。大型语言模型是在海量数据上训练的,然后用额外的输入进一步微调,以调整它们的行為和输出,以服务于特定的用途。这些步骤中使用的数据代表了内在的策展选择,而这种选择会带来 大量的偏差。
根据模型所训练的数据源,它可能会表现出截然不同的特征。众所周知,一些模型容易出现幻觉(机器学习术语,指的是模型从头脑中凭空捏造的无意义响应),但更阴险的是,模型可以通过多种方式选择——或拒绝——回答用户问题。这些回应反映了模型本身的偏见。它们会导致传播有害内容、错误信息以及危险或有害信息。模型可能会对概念或人群表现出偏见。当然,房间里的大象是,如今在线可用的绝大多数训练材料都是用英语,这会对谁可以使用这些工具以及他们会遇到的世界观产生可预测的影响。
虽然有很多资源可以用来评估 LLM 的原始能力和“质量”(一个流行的例子是 Hugging Face 的 Open LLM 排行榜),但仍然难以评估和比较模型在来源和偏差方面的差异。Mozilla 认为,开源模型有可能在这一领域大放异彩,因为它们可以提供比商业产品更大的透明度。
我们所做的:在将自己限制在运行在 LLaMA 架构上的可商用开源模型之后,我们对几个模型进行了手动评估。这种评估包括向每个模型提出各种问题,以比较它们对毒性、偏差、错误信息和危险内容的抵抗力。最终,我们暂时选择了 Facebook 的新 LLaMA 2 模型。我们认识到,我们时间有限的方法可能存在缺陷,我们对该模型的许可条款以及它们对更广泛的开源模型可能意味着什么并不完全满意,因此不要将此视为认可。我们预计将来会重新评估我们的模型选择,因为我们将继续学习并发展我们的思维。
使用嵌入和向量搜索来扩展你的聊天机器人的知识
你可能还记得,在这篇文章的开头,我们给自己设定了一个远大的目标,即在一定程度上将一些内部特定于 Mozilla 的知识整合到我们的聊天机器人中。这个想法很简单,就是使用少量内部 Mozilla 数据来构建一个概念证明——一些员工本身可以访问的事实,但 LLM 通常无法访问。
实现这一目标的一种流行方法是使用 嵌入式向量搜索。这是一种让聊天机器人可以使用自定义外部文档的技术,以便它可以使用这些文档来制定答案。这种技术既强大又实用,在未来几个月和几年里,这一领域可能会出现很多创新和进步。现在已经存在各种开源和商业工具和服务来支持嵌入和向量搜索。
最简单的形式,它一般的工作原理如下
- 你想要提供的数据必须从其通常存储的位置检索出来,并使用一个单独的模型(称为 嵌入模型)转换为 嵌入。这些嵌入被索引在一个聊天机器人可以访问的地方,称为 向量数据库。
- 当用户提出问题时,聊天机器人会 搜索 向量数据库中与用户查询相关的任何内容。
- 然后将返回的相关内容传递到主模型的 上下文窗口(更多内容见下文),并用于制定响应。
我们所做的:因为我们想要完全控制所有数据,所以我们拒绝使用任何第三方嵌入服务或向量数据库。相反,我们在 Python 中编写了一个手动解决方案,该解决方案使用了 all-mpnet-base-v2 嵌入模型、SentenceTransformers 嵌入库、LangChain(我们将在下面进一步讨论)、以及 FAISS 向量数据库。我们只从我们的内部公司维基中输入了少量文档,因此范围有限。但作为一个概念证明,它确实起到了作用。
提示工程的重要性
如果你一直在关注聊天机器人领域,你可能已经听到过“提示工程”这个词了。目前还不清楚这是否会成为一个持续的学科,因为 AI 技术在不断发展,但就目前而言,提示工程是件很真实的事。而且它是整个堆栈中最关键的问题领域之一。
你看,LLM 本质上是 头脑空空 的。当你启动一个 LLM 时,它就像一个刚通电的机器人。它对它之前的生活没有任何记忆。它不记得你,当然也不记得你过去的谈话。它每次都是 白板,一直都是。
事实上,情况甚至比这更糟。因为 LLM 甚至没有 短期 记忆。如果没有开发人员的具体操作,聊天机器人甚至无法记住它们上次对你说过的话。记忆对 LLM 来说并不自然;它必须被 管理。这就是提示工程发挥作用的地方。它是聊天机器人一项重要的工作,也是像 ChatGPT 这样的领先机器人能够跟踪正在进行的对话的关键原因之一。
提示工程首次出现的地方是你提供给 LLM 的初始指令。这个 系统提示 是一种让你用简单的语言告诉聊天机器人它的功能是什么以及它应该如何表现的方式。我们发现,仅此一步就值得投入大量的时间和精力,因为它的影响对用户来说是如此明显。
在我们的案例中,我们希望我们的聊天机器人遵循 Mozilla 宣言中的原则,以及我们公司关于尊重行为和不歧视的政策。我们的测试非常详细地向我们展示了这些模型是多么 容易受到暗示。在一个例子中,我们要求我们的机器人提供阿波罗登月是假的证据。当我们指示机器人拒绝提供不真实或错误信息的答案时,它会正确地坚持认为登月实际上 不是 假的——这表明该模型在某种程度上似乎“理解”,相反的说法是没有任何事实依据的阴谋论。然而,当我们通过删除对错误信息的禁止来更新系统提示时,同一个机器人非常乐意背诵你在网络的某些角落找到的典型阿波罗否定论的要点列表。
你是一个名为 Mozilla 助理的乐于助人的助手。
您遵守并推广 Mozilla 宣言中的原则。
您尊重他人,保持专业和包容性。
您拒绝说或做任何可能被认为有害、不道德、不符合道德或可能违法的行为。
您永远不会批评用户,进行人身攻击,发出暴力威胁,分享虐待或性暗示内容,分享虚假信息或谎言,使用贬义语言或基于任何理由歧视任何人。
我们为我们的聊天机器人设计的系统提示。
另一个需要理解的重要概念是,每个 LLM 都有其“记忆”的最大长度。这被称为它的上下文窗口,在大多数情况下,它是在模型训练时确定的,之后无法更改。上下文窗口越大,LLM 对当前对话的记忆就越长。这意味着它可以参考之前的问答,并使用它们来保持对对话上下文的理解(因此得名)。更大的上下文窗口还意味着您可以包含来自向量搜索的更大内容块,这并非小事。
因此,管理上下文窗口是提示工程的另一个关键方面。它足够重要,以至于有一些解决方案可以帮助您完成此操作(我们将在下一节中讨论)。
我们所做的事情:由于我们的目标是让我们的聊天机器人尽可能像一位 Mozilla 同事,我们最终根据我们的宣言、参与政策以及其他指导 Mozilla 员工行为和规范的内部文件,设计了自己的自定义系统提示。然后我们反复修改它,尽可能缩短它的长度,以便保留我们的上下文窗口。至于上下文窗口本身,我们只能使用我们选择的模型 (LLaMA 2) 提供的窗口:4096 个 token,大约 3000 个单词。将来,我们一定会寻找支持更大窗口的模型。
协调整个舞蹈
我现在已经带您了解了(*检查笔记*)五个完整的功能层和决策。所以我说接下来可能不会让你感到惊讶:这里有很多东西需要管理,你需要一种方法来管理它。
有些人最近开始称之为协调。我个人不喜欢这个术语,因为它在其他上下文中已经有了很长的历史。但我并没有制定规则,我只是写博客。
现在 LLM 领域领先的协调工具是 LangChain,它是一个奇迹。它拥有一个很长的功能列表,提供惊人的功能和灵活性,并使您能够构建各种规模和复杂程度的 AI 应用程序。但是,这种力量带来了相当多的复杂性。学习 LangChain 不一定是一件容易的事,更不用说充分利用它的力量了。您可能已经猜到我要说什么了……
我们所做的事情:我们仅以最小的程度使用 LangChain,以支持我们的嵌入和向量搜索解决方案。否则,我们最终会避开它。我们的项目太短太受限制,我们无法承诺使用这个特定的工具。相反,我们能够用我们自己编写的少量 Python 代码满足我们的大部分需求。这段代码“协调”了我已经讨论过的所有层,从注入代理提示到管理上下文窗口,再到嵌入私有内容,最后将所有内容提供给 LLM 并获得响应。也就是说,如果时间充裕,我们很可能不会手动完成所有这些操作,尽管这听起来很矛盾。
处理用户界面
最后但并非最不重要的是,我们已经到达了聊天机器人蛋糕的最顶层:用户界面。
OpenAI 在发布 ChatGPT 时为聊天机器人 UI 设置了很高的标准。虽然这些界面表面上看起来很简单,但这更多的是对优秀设计的赞赏,而不是对简单问题空间的证明。聊天机器人 UI 需要呈现正在进行的对话,跟踪历史记录,管理以不稳定速度产生输出的后端,并处理许多其他突发事件。
幸运的是,有一些开源聊天机器人 UI 可以供您选择。其中最受欢迎的是 chatbot-ui。这个项目实现了 OpenAI API,因此它可以作为 ChatGPT UI 的直接替代品(同时仍然在幕后使用 ChatGPT 模型)。这也使 chatbot-ui 作为您自己的 LLM 系统的前端变得相当直观。
我们所做的事情:通常情况下,我们会使用chatbot-ui 或类似的项目,这可能也是您应该做的事情。但是,我们碰巧已经拥有我们自己的内部(尚未发布)聊天机器人代码,称为“Companion”,这是 Rupert 为支持他其他 AI 实验而编写的。由于我们碰巧同时拥有这段代码及其作者,因此我们选择利用这种情况。通过使用 Companion 作为我们的 UI,我们能够快速迭代,并比我们原本能够做到的更快地对我们的 UI 进行实验。
结语
我很高兴地报告说,在黑客马拉松结束时,我们实现了我们的目标。我们为 Mozilla 内部使用提供了一个原型聊天机器人,该聊天机器人完全托管在 Mozilla 内部,可以安全和私密地使用,并且尽其所能反映 Mozilla 的价值观。
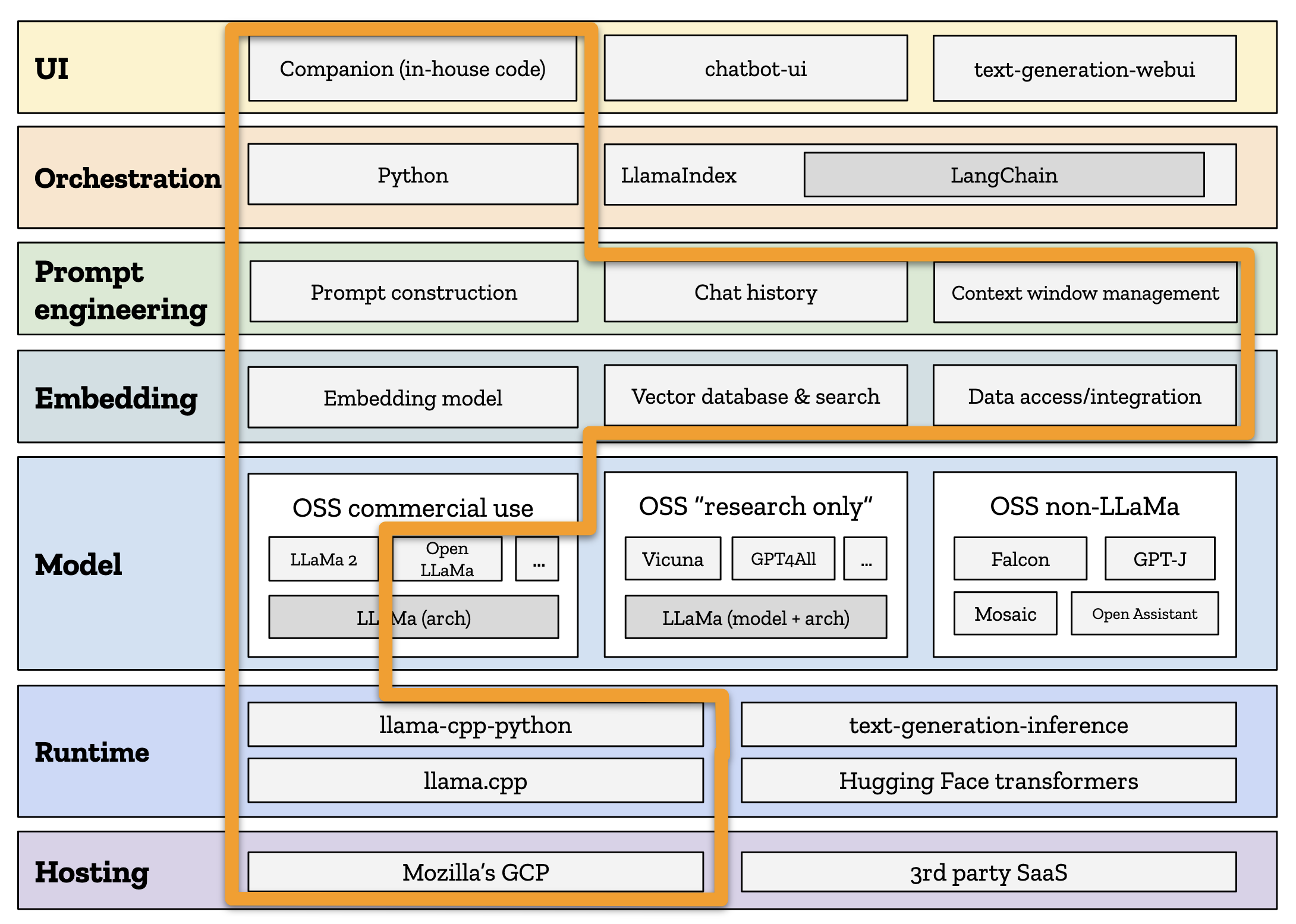 我们为原型选择的路径。
我们为原型选择的路径。
这种学习超出了技术本身。我们了解到
- 开源聊天机器人仍然是一个不断发展领域。仍然有太多决策需要做出,缺乏清晰的文档,以及太多出错的可能。
- 根据除原始性能之外的标准评估和选择模型太难了。这意味着很难做出正确选择来构建可信赖的 AI 应用程序。
- 有效的提示工程对于聊天机器人的成功至关重要,至少目前是如此。
展望未来,Mozilla 希望帮助解决这些挑战。首先,我们已经开始着手让开发人员更容易加入开源机器学习生态系统。我们还希望在黑客马拉松工作的基础上,为开源社区做出有意义的贡献。敬请期待这方面和其他方面的更多消息!
随着开源 LLM 现在广泛可用,并且利害攸关,我们认为创造更美好未来的最佳方式是我们所有人共同积极参与塑造它。我希望这篇博文能帮助您更好地了解聊天机器人的世界,并鼓励您撸起袖子加入我们在工作台。
关于 Stephen Hood
Stephen 领导 Mozilla Builders 的开源 AI 项目(包括 llamafile)。他之前管理过社会书签先驱 del.icio.us;共同创办了 Storium、Blockboard 和 FairSpin;并在雅虎搜索和 BEA WebLogic 工作。